


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Subway fault data classification method based on unbalanced data set
A technology of fault data and classification methods, applied in data processing applications, instruments, calculations, etc., can solve problems such as intrusion into the distribution space of negative samples, sample deletion, and insufficient consideration of spatial distribution, so as to achieve good model generalization ability and improve recognition The effect of rate, good classification effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

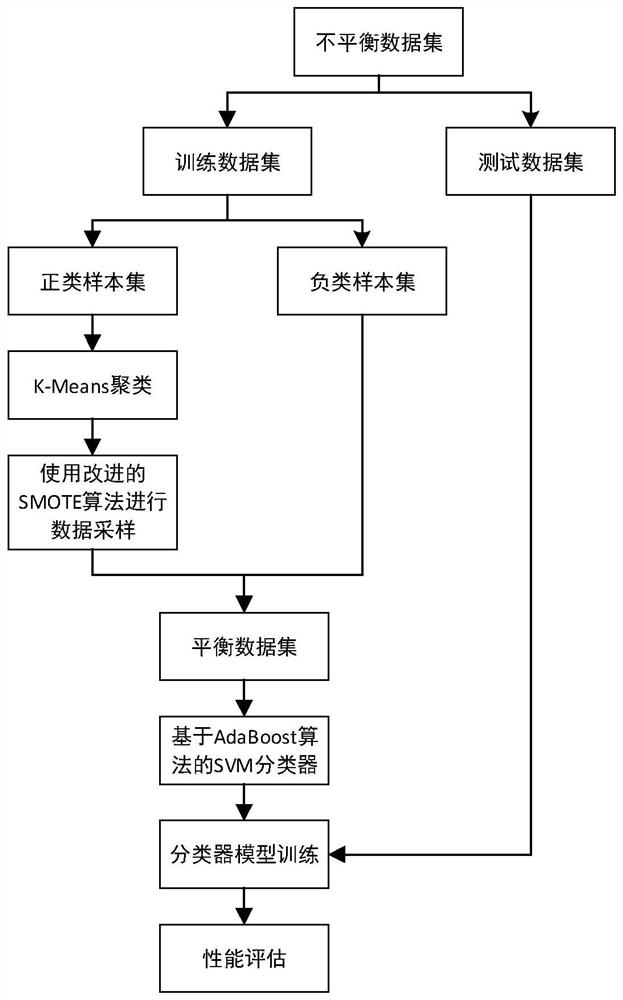
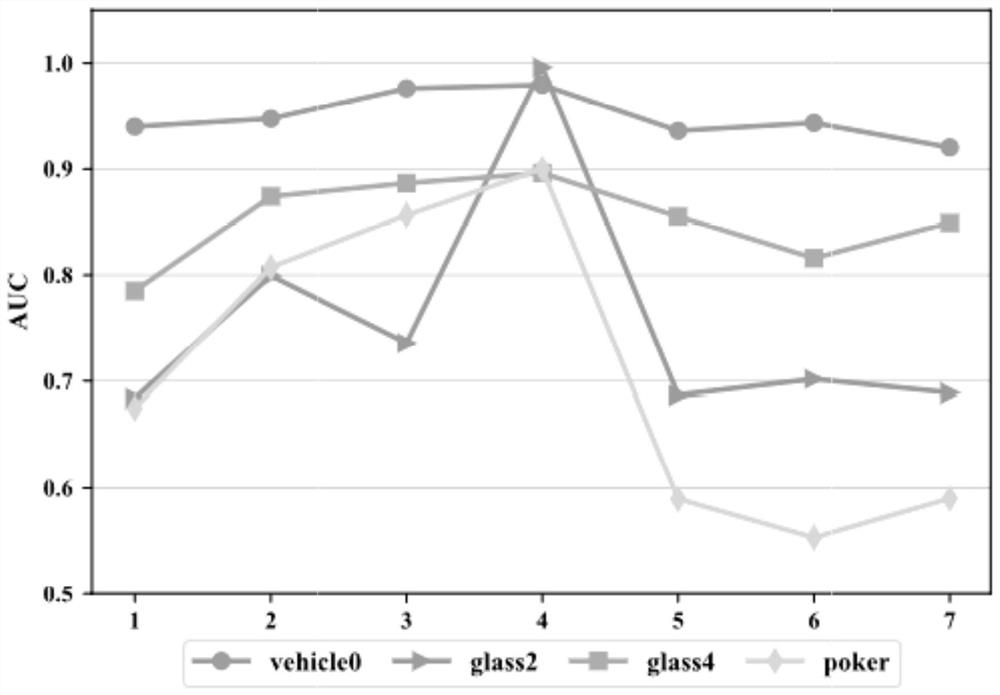
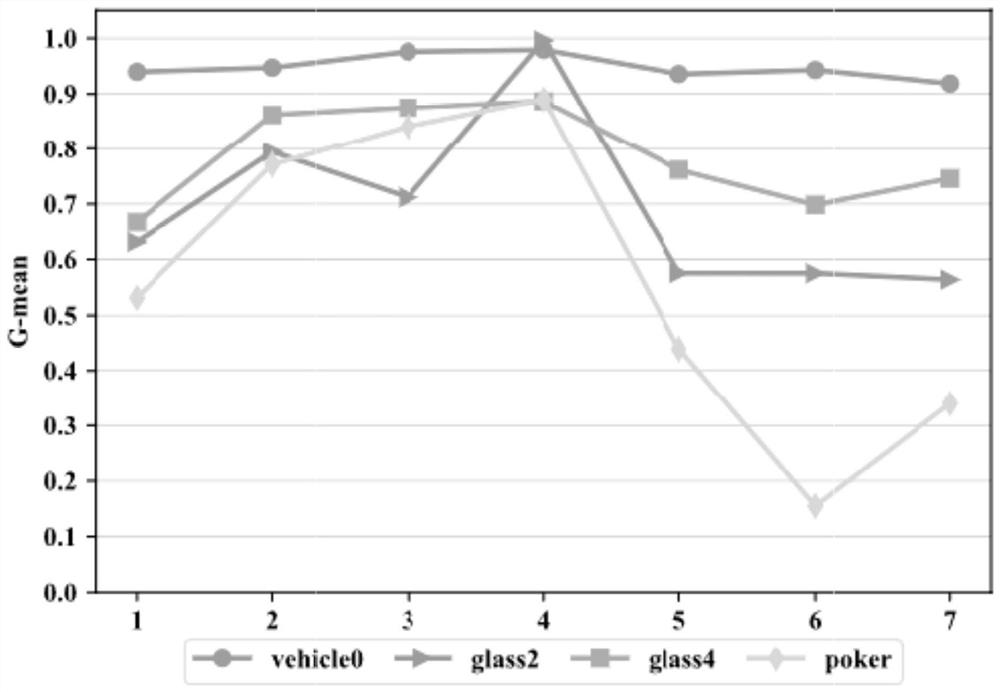
Examples
Embodiment
[0114] Step 1. Obtain the unbalanced data set D required for the experiment from the Guangzhou Metro operation data;
[0115] Step 2, divide the data set D into training data set D Train and the test dataset D Test ,Specific steps are as follows:
[0116] 2.1) Randomly divide the unbalanced data set into 5 parts with the same number of samples;
[0117] 2.2) One of the 5 samples is randomly selected as the test data set, and the other 4 samples are used as the training data set.
[0118] Step 3, put D Train The data samples in are divided into positive sample sets N min (minority class samples) and negative class sample set N maj (majority class samples), and calculate the number of samples to be sampled: T=N maj -N min ;
[0119] Step 4, use the k-Means clustering algorithm to classify the positive data set N min Clustering to get k clusters C i ,i=1,2,...,k. The specific steps of the K-Means clustering algorithm are as follows:
[0120] 4.1) The input data is pos...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com