Audio data labeling method, device and system
An audio data and audio technology, applied in the field of audio data labeling methods, devices and systems, can solve the problems of unstable labeling audio data quality, low accuracy of acoustic models, time-consuming and labor-intensive, etc., to save manpower and material resources, and maximize The effect of optimizing the identification path is accurate and improving the accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
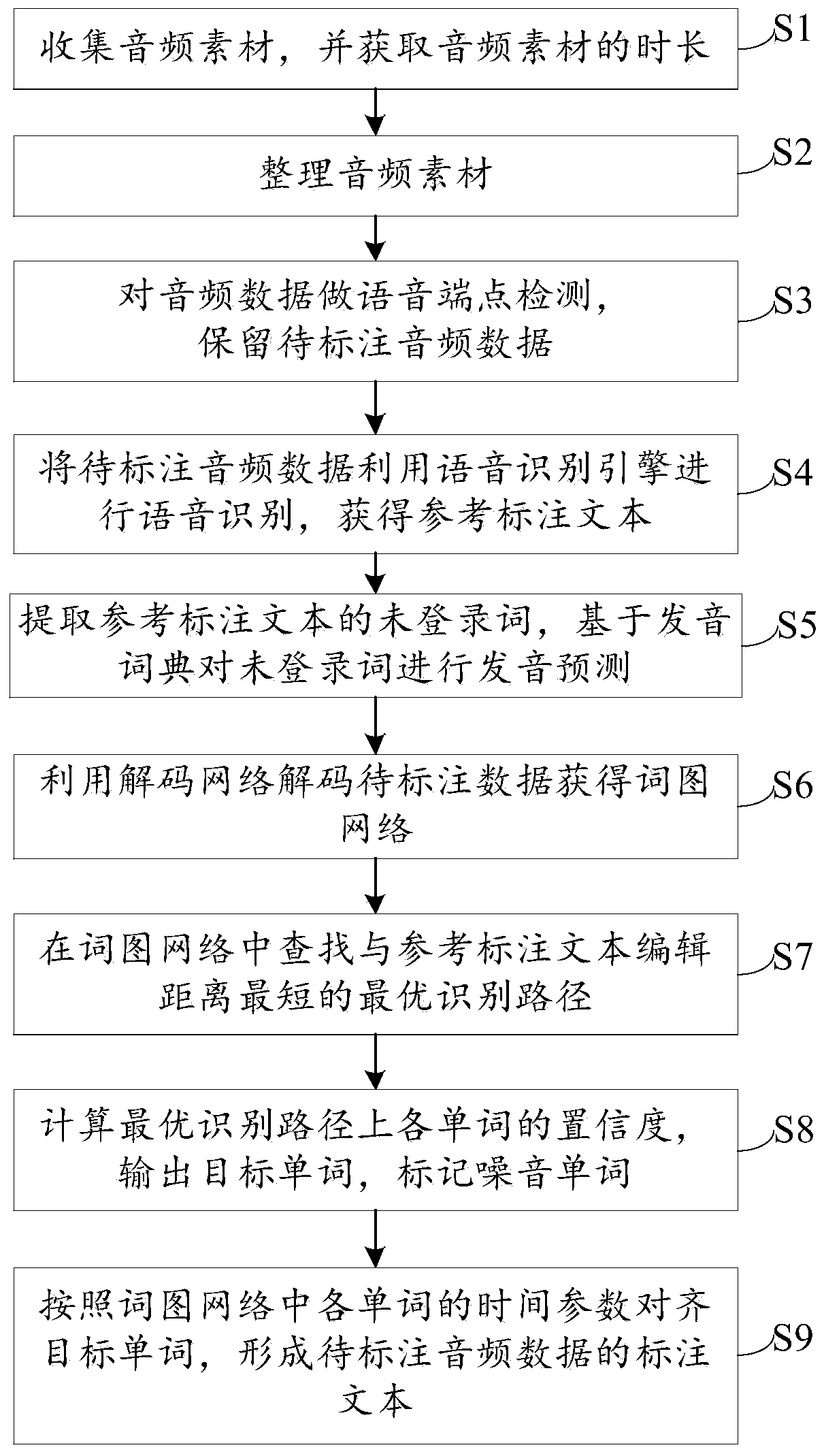
[0062] Such as figure 1 As shown, a method for labeling audio data includes the following steps:
[0063] S1. Collect audio material and obtain the duration of the audio material.
[0064] The audio material in step S1 is the collected original audio, which may contain invalid data such as noise and long blank space, but the duration of the audio material described in this step is the audio duration including noise and blank space.
[0065] S2. Organize the audio material, compare the duration of the audio material with the preset duration condition, and delete the audio material that does not meet the duration condition.
[0066] The main purpose of step S2 is to delete the shorter audio material and split the longer audio material, because the text content of the shorter audio expression may be incomplete, and the longer audio material contains more text content, which increases the difficulty of training .
[0067] S3. Perform voice endpoint detection on the audio data, ...
Embodiment 2
[0088] In order to implement an audio tagging method disclosed in Embodiment 1, this embodiment provides an audio tagging device on the basis of Embodiment 1, such as figure 2 As shown, an audio labeling device includes:
[0089] The audio duration acquisition module is used to acquire the duration of the collected audio material.
[0090] The audio sorting module is used to compare the duration of the audio material with the preset duration condition, and delete the audio material that does not meet the duration condition.
[0091] It should be noted that: the duration condition in the audio organizing module can include: any one or both of the large boundary value and the small boundary value, when the duration of the audio material is less than or equal to the small boundary value, the audio material Delete, when the duration of the audio material is greater than or equal to the maximum boundary value, the audio material is divided.
[0092] The endpoint detection module...
Embodiment 3
[0106] The embodiment of the present application provides a computer system based on the audio data labeling method of Embodiment 1, including:
[0107] one or more processors; and
[0108] A memory associated with the one or more processors, the memory is used to store program instructions, and when the program instructions are read and executed by the one or more processors, execute the above audio data tagging method.
[0109] in, image 3 The architecture of the computer system is exemplarily shown, which may specifically include a processor 310 , a video display adapter 311 , a disk drive 312 , an input / output interface 313 , a network interface 314 , and a memory 320 . The processor 310 , video display adapter 311 , disk drive 312 , input / output interface 313 , network interface 314 , and the memory 320 can be connected by communication bus 330 .
[0110] Wherein, the processor 310 may be implemented by a general-purpose CPU (Central Processing Unit, central processing...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com