Speech synthesis method and system based on neural network, and storage medium
A neural network and speech synthesis technology, applied in the field of speech synthesis based on neural network, can solve the problems of difficult speech synthesis, difficult sample acquisition and high acquisition cost
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
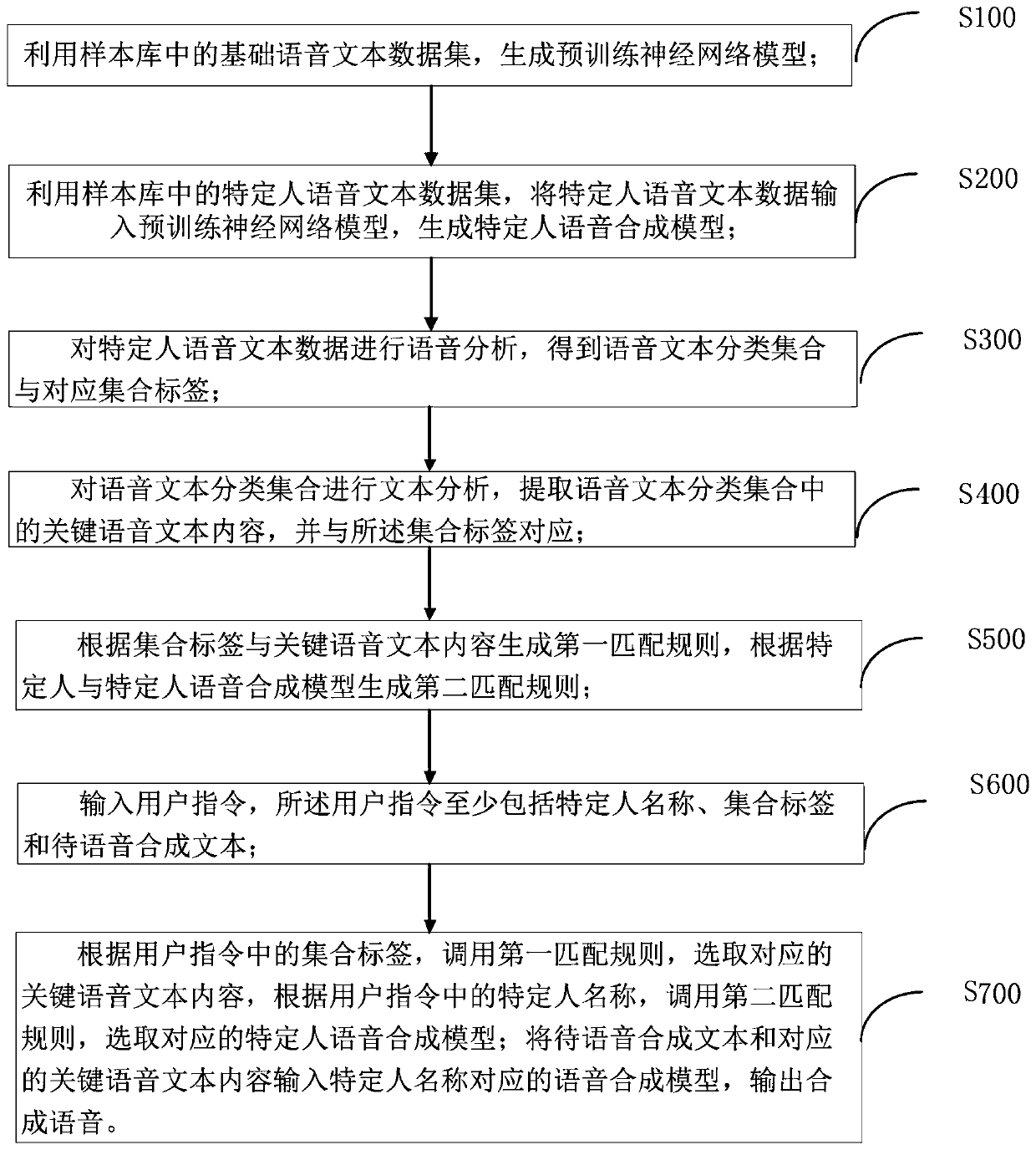
[0033] Such as figure 1 , the present invention also discloses a neural network-based speech synthesis method, comprising:
[0034] S100, generating a pre-trained neural network model by using the basic speech-text data set in the sample library;
[0035] Specifically, the neural network module acquires the basic data set in the sample library, the basic data set is the text data and voice data of a single person, the basic data set is preferably a single person, medium-volume, and high-quality text data and voice data, and the single person is selected Human and high-quality speech and text data can make the trained pre-training neural network model reflect the mapping from text to speech, and choosing a medium level, compared with the large number of levels adopted by the existing technology, can not only save costs, but also Data acquisition is also easy. The basic data set can be stored in the sample library module in advance, and can also be temporarily imported into th...
Embodiment 2
[0071] As shown in the figure, the embodiment of the present invention provides a neural network-based speech synthesis system, such as image 3 , including: sample library module 1, data processing module 2, neural network module 3, information input module 4, matching rule module 5, wherein:
[0072] The sample library module 1 is used to store several sets of corresponding data, each set of data includes at least text data and voice data. Specifically, the sample library module 1 includes basic data sets and specific person data sets. The basic data set is text data and voice data of a single person, and the basic data set is preferably single person, medium-volume, high-quality text data and voice data. The specific person data set is several groups of specific person text data and voice data. A small amount of low-quality text data and speech data are preferred for specific person data sets. The low quality here refers to audio obtained from non-professional recordings,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com