Long text-oriented semantic matching method and system
A technology for semantic matching and long text, applied in the field of semantic matching methods and systems for long texts, can solve problems such as unsatisfactory effects of text semantic understanding methods, achieve unsatisfactory results, optimize user experience, and improve search speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
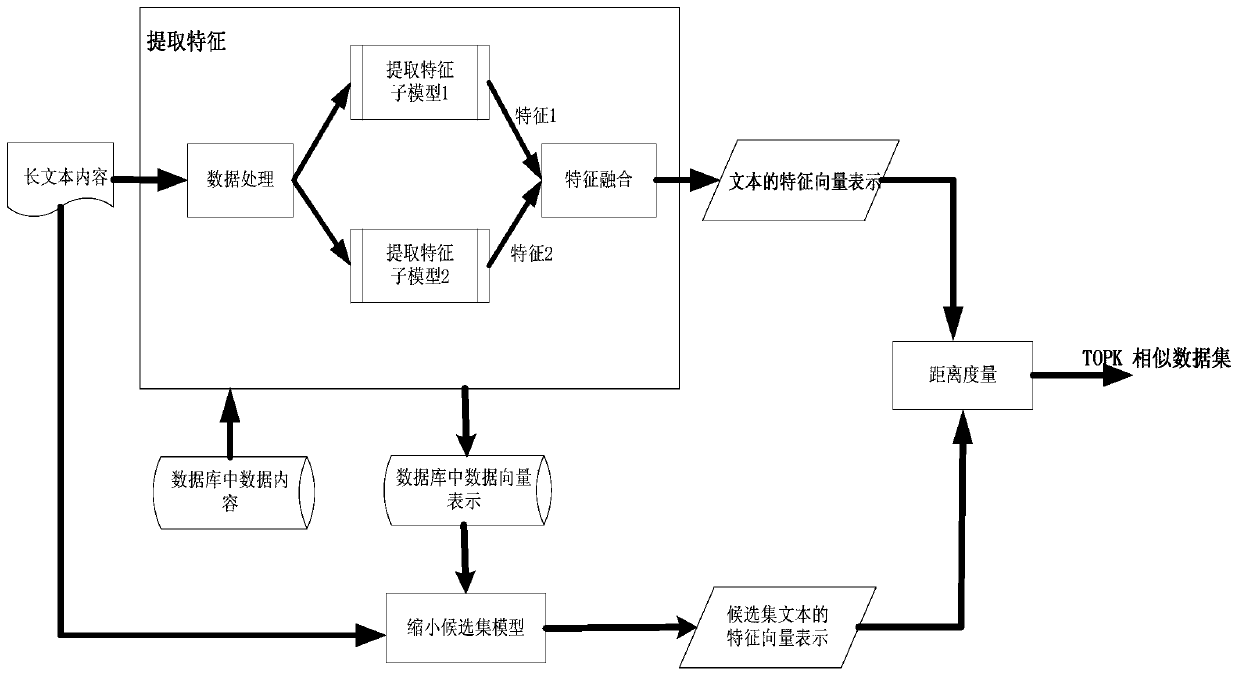
[0038] Embodiment 1 provides a semantic matching method for long texts, which is mainly used in the field of semantic matching of long texts, to find TOPK text data similar to the target text, such as figure 1 The specific implementation steps shown are as follows:
[0039] Step s1: Perform data processing on the input text, including operations such as removing special characters, word segmentation, word segmentation, and text preprocessing.
[0040] During the data processing in step s1, invalid characters in the input text can be removed, and then the input text can be converted into a text sequence in units of characters and a text sequence in units of words.
[0041] Step s2: Map the input text after data processing into a numerical sequence. Specifically, it may include:
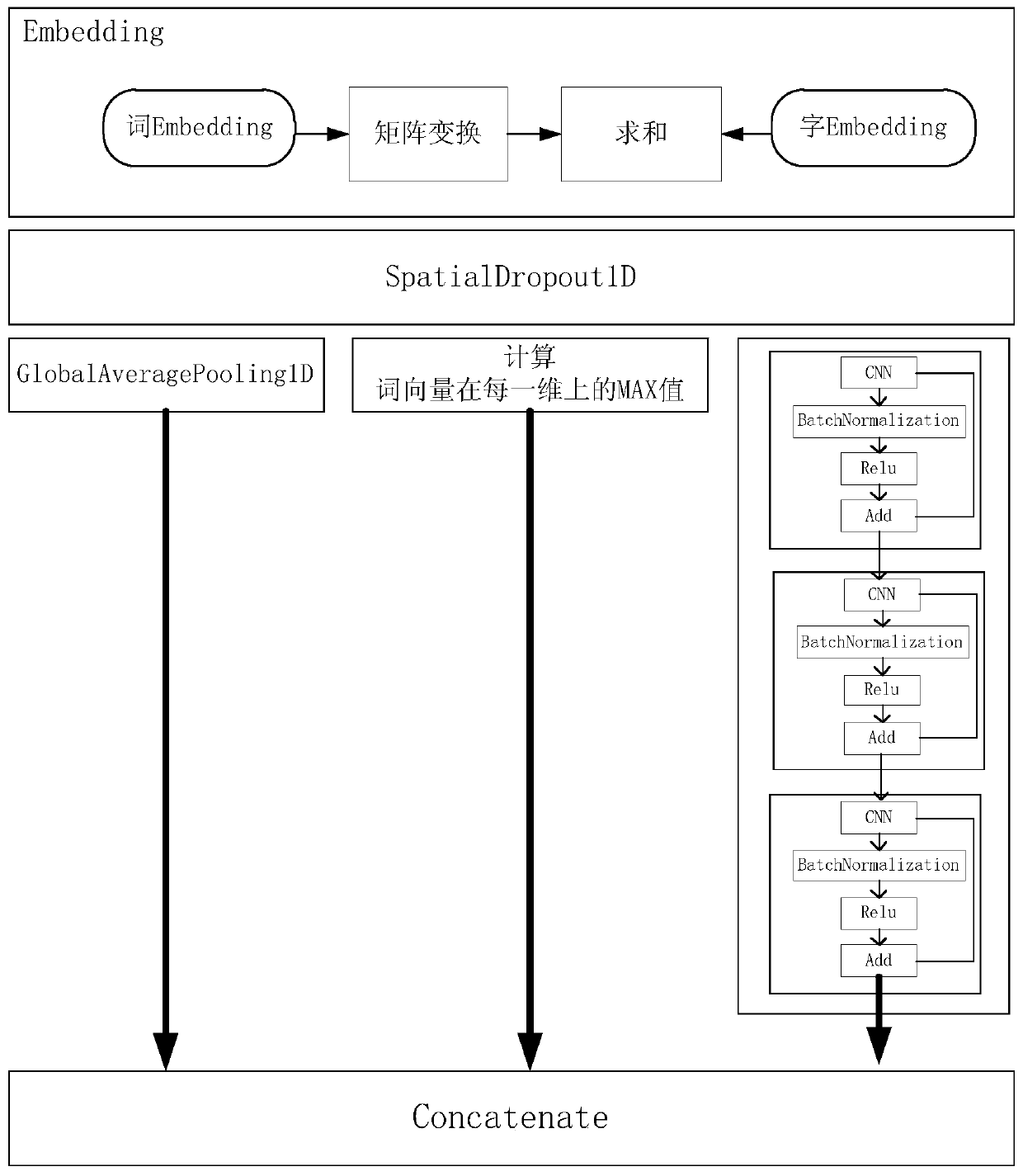
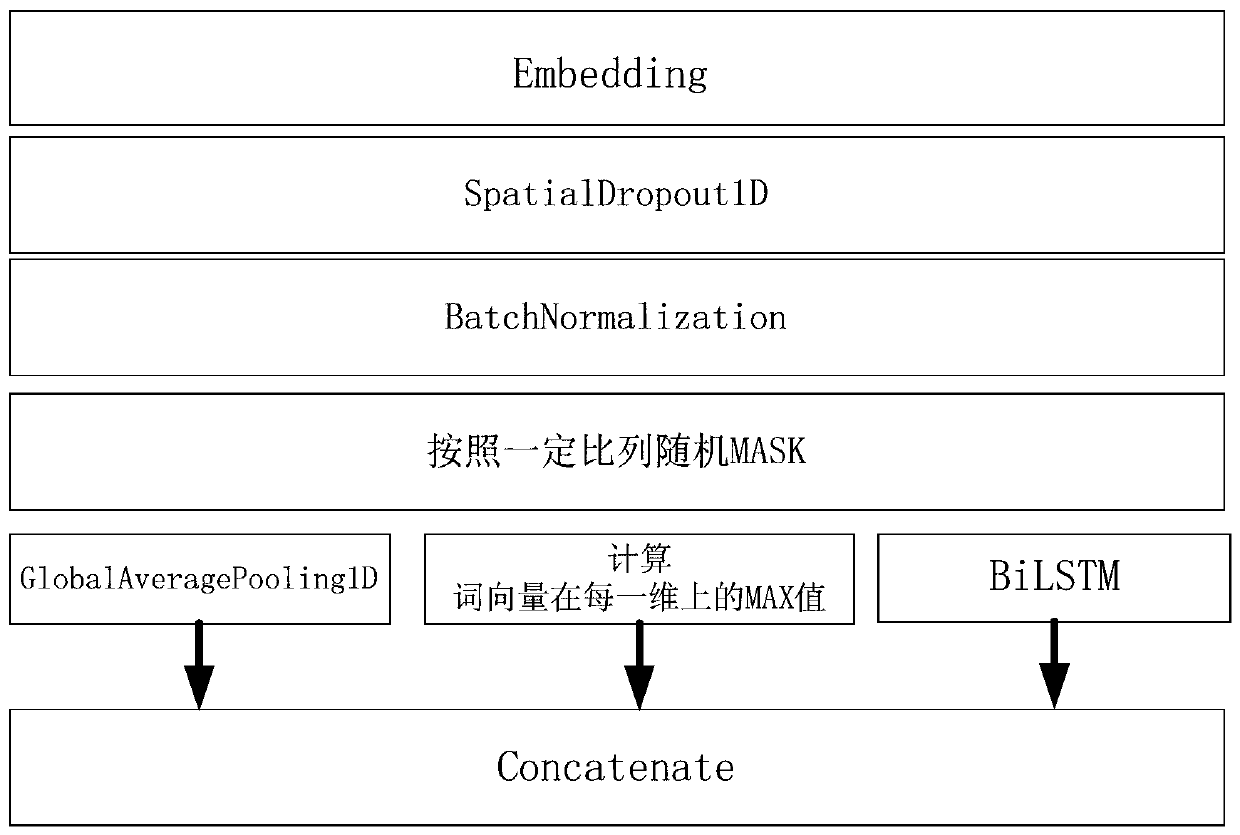
[0042] Step s21: Perform word vector training based on the data in the database, and generate a dictionary to obtain a word vector model. Different sub-feature extraction modules have different word ...
Embodiment 2
[0072] Embodiment 2 provides a long text-oriented semantic matching system, including:
[0073] The text processing module is used to perform data processing on the input text, including operations such as removing special characters, word segmentation, word segmentation, and text preprocessing;
[0074] A numerical sequence generation module, which is used to map the input text after data processing into a numerical sequence in units of words and a numerical sequence in units of words;
[0075] The feature vector extraction module is used to input the numerical sequence of the input text into the feature extraction model to obtain the feature vector of the input text. The feature extraction module includes multiple sub-feature extraction models, and the feature vector of the input text is the output result of multiple sub-feature models. Fusion;
[0076] The database processing module is used to pass each piece of data in the database through a text processing module, a nume...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com