


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Similarity calculation method based on text and semantics, server and storage medium
A technology of semantic similarity and text similarity, which is applied in text database query, unstructured text data retrieval, special data processing applications, etc., can solve the problems of diverse expressions in difficult conversations, single expression methods, etc., to ensure diverse expressions , Improve intelligence and reduce the effect of text information loss
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
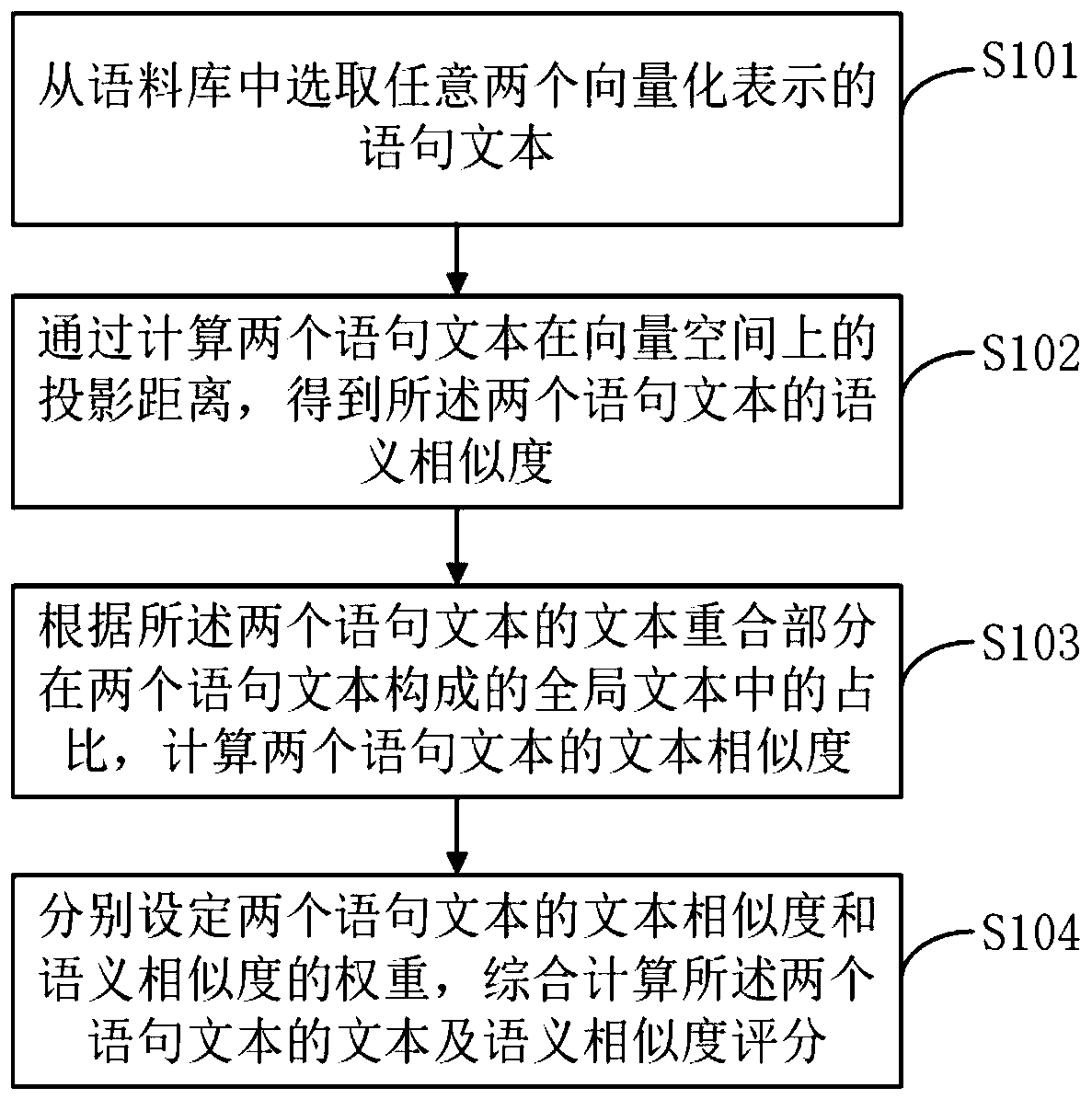
[0027] see figure 1 , a schematic flowchart of a method for calculating similarity based on text and semantics provided by an embodiment of the present invention, including:
[0028] S101. Select any two vectorized sentence texts from the corpus;
[0029] The corpus is the language material that actually appears in the actual use of the language. It is generally a large-scale electronic text library, which can be formed by manually collecting language materials in a specific field to form a prediction library, such as collecting barrage materials in the live broadcast field to form Bullet screen corpus. The vectorized representation refers to expressing the sentence text as a series of vectors capable of expressing the semantics of the text, which is generally realized by word vectorization, and the vectorized representation of the sentence text can facilitate computer recognition and processing.
[0030] Preferably, a corpus is formed by collecting conversational materials ...
Embodiment 2
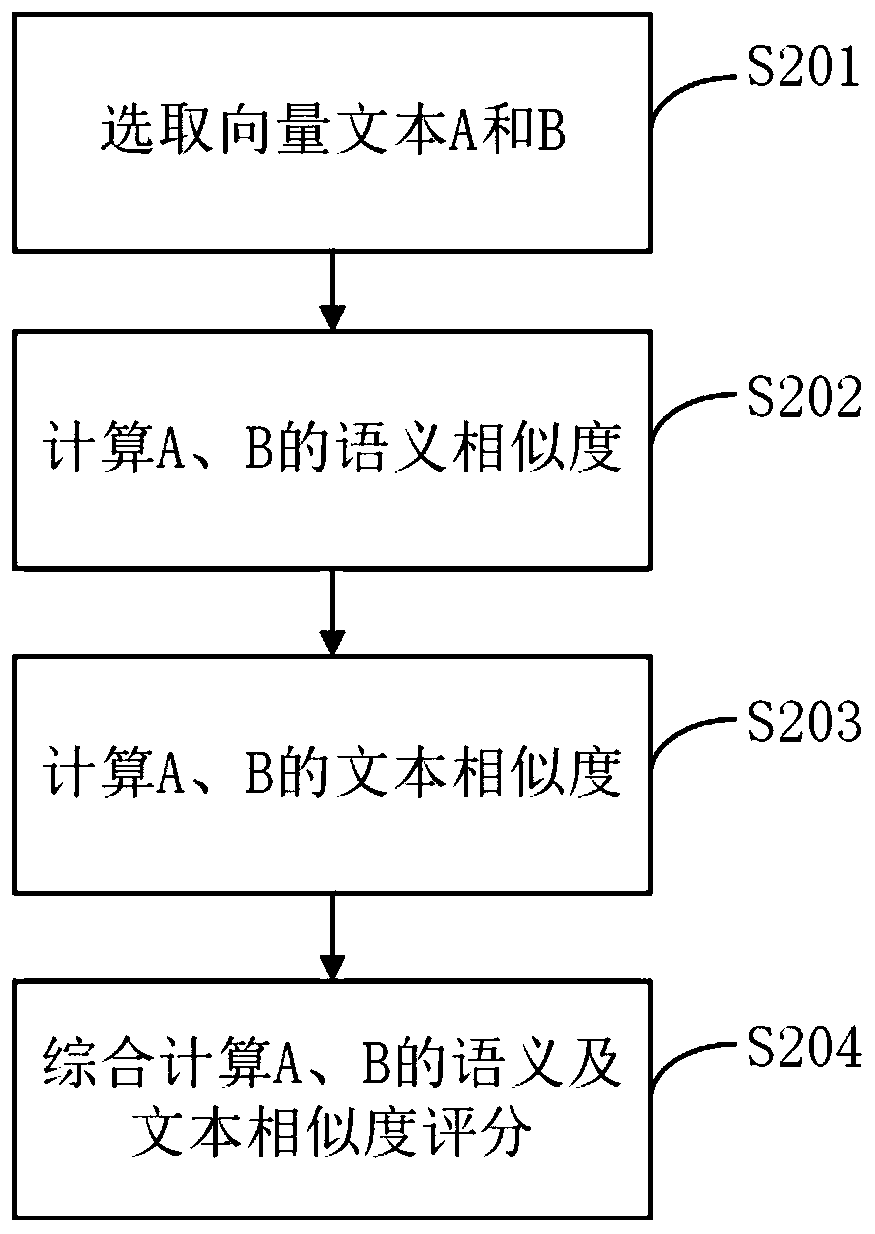
[0057] figure 2 Another schematic flow chart of the text-based and semantic similarity method provided by Embodiment 2 of the present invention. On the basis of Embodiment 1, take the actual calculation of the text similarity of two sentences as an example to describe in detail:
[0058] Collect the corpus of specific fields to form a corpus. In this embodiment, take the bullet chat corpus as an example, collect the bullet chat corpus, and after removing repetitions, removing phrase numbers, removing sensitive words, shielding vulgar sentences, etc., perform jieba word segmentation, and Use doc2vec to vectorize all the text in the bullet chat corpus.
[0059] S201. Select vector text A and B;
[0060] Assume that the vector text or barrage text is: A=Miss Sister has a nice singing voice, I like it very much, B=Miss Sister with beautiful voice and sweet singing voice.
[0061] Text A and B can be represented by doc2vec vectors as:
[0062]
[0063]
[0064] Among them...
Embodiment 3
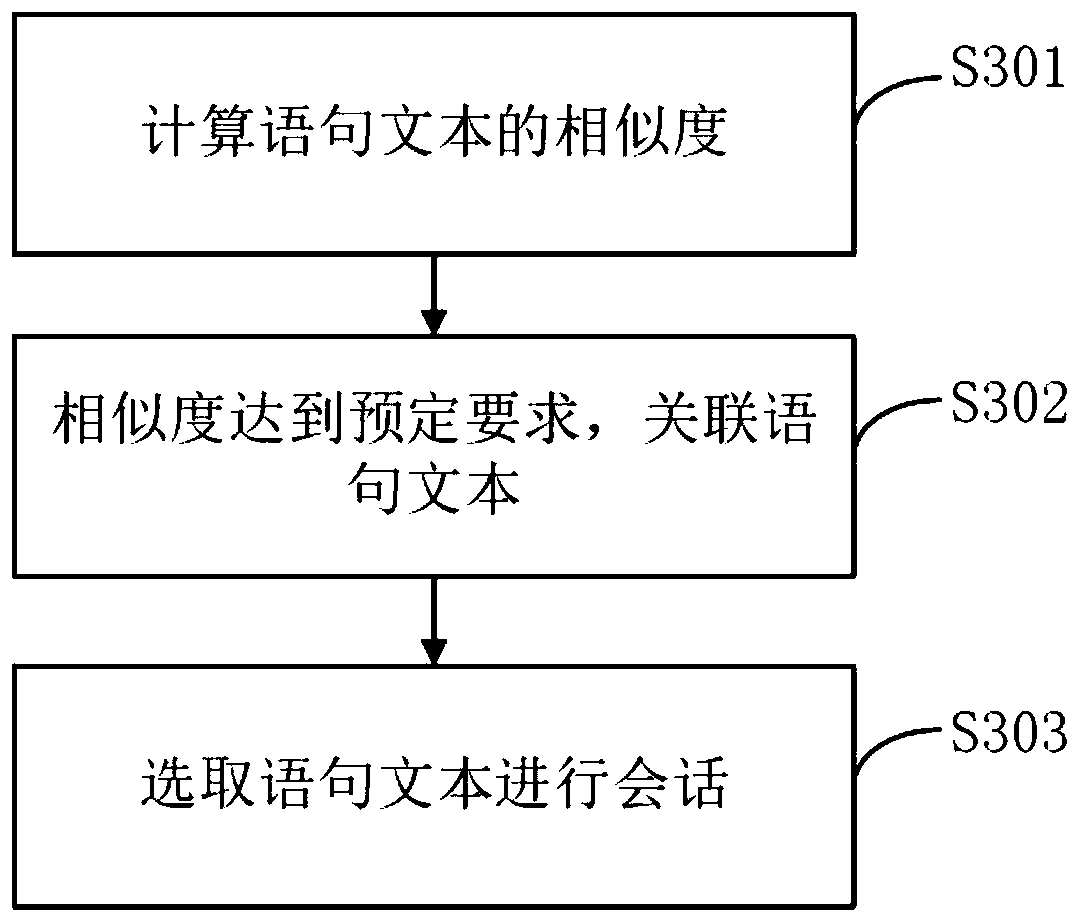
[0085] image 3 Another schematic flow chart of the text-based and semantic similarity calculation method provided by Embodiment 3 of the present invention. On the basis of Embodiment 1, the semantic and text similarity calculation of the calculation statement in step S104 is further described. Including the following:
[0086] By calculating the semantics and text similarity of the sentence text, it is possible to determine the similarity of any two sentences in terms of semantic expression and text composition. If the semantic similarity is calculated separately, the expression form of the sentence will be too simple. If the text similarity is calculated separately , there are texts with the same composition but different expressions. Therefore, when conducting a man-machine dialogue, based on the existing corpus, the computer can reply with various text content.
[0087] It should be noted that this implementation is only a specific application provided by the comprehensi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com