Annotation data generation method and device and computer readable storage medium
A technology for labeling data and computer programs, applied in the field of data models, can solve problems such as insufficient dispersion of features, lower recognition rate, model overfitting, etc., and achieve faster training speed and accuracy, expanded size and richness, and strong data randomness Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
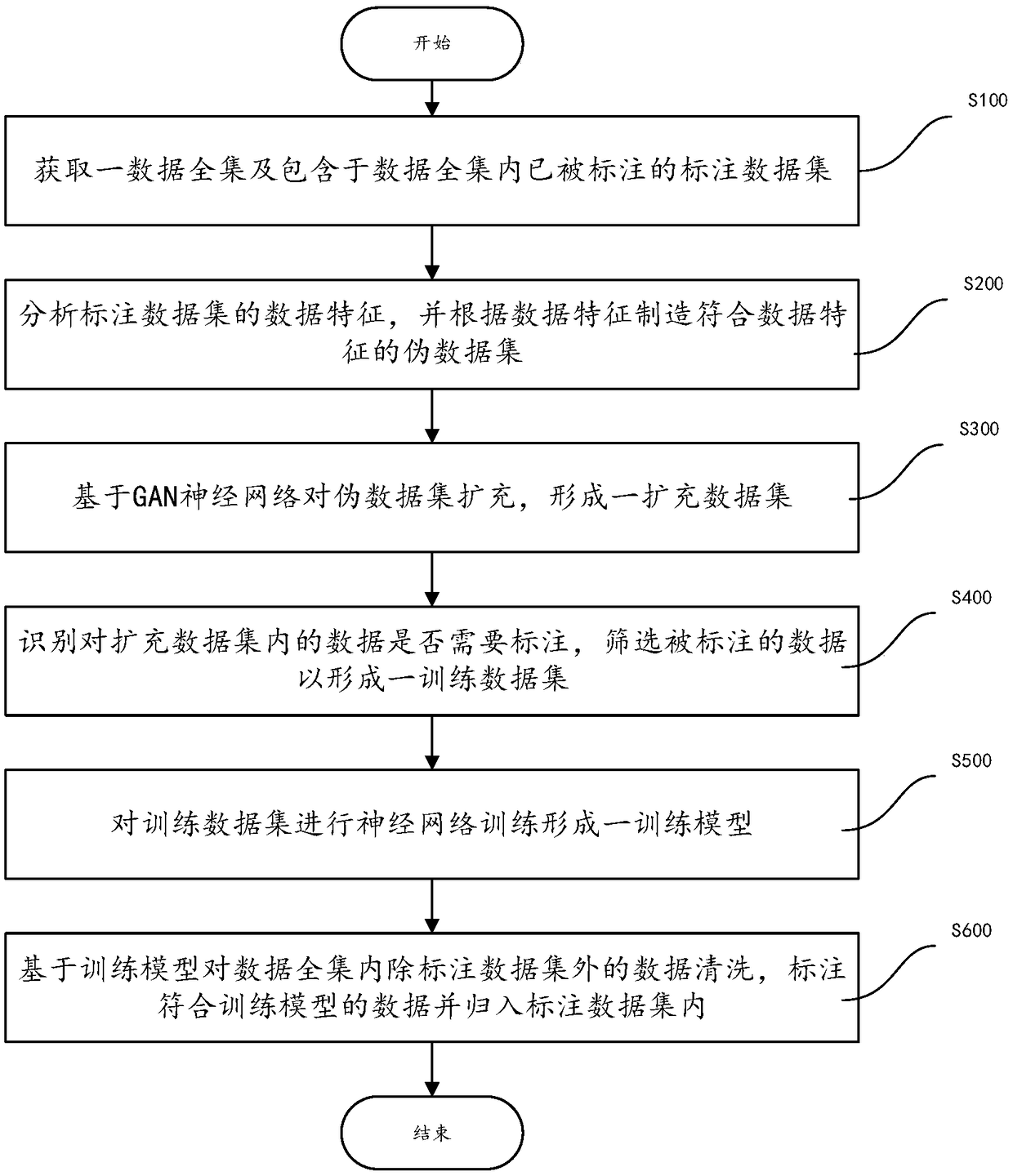
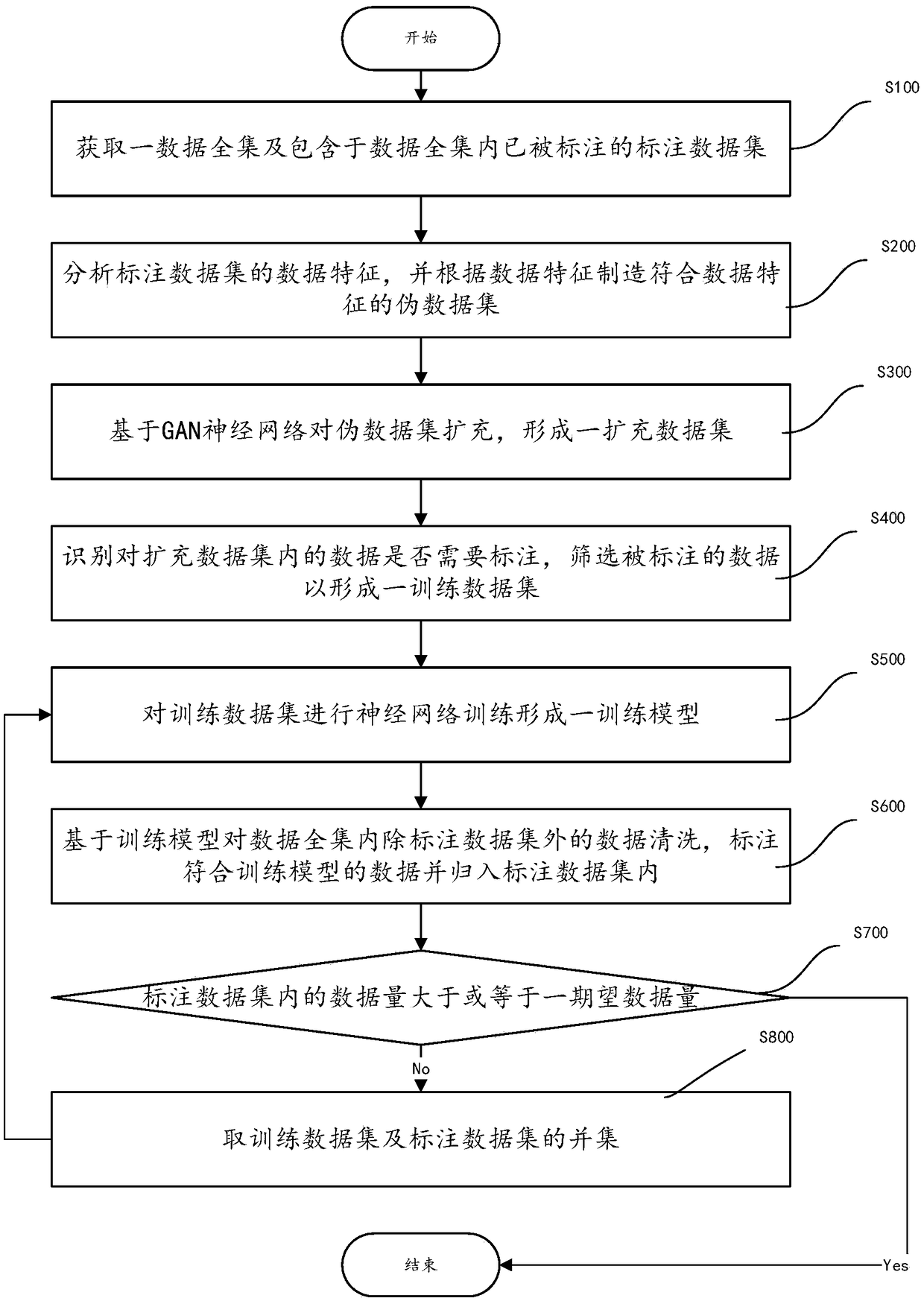
[0076] refer to image 3 , in a preferred embodiment, the annotation data generation method also includes the following steps:
[0077] S700: Determine whether the amount of data in the labeled data set A' is greater than or equal to an expected amount of data;
[0078] First of all, it is necessary to judge the amount of data in the currently obtained labeled data set A', and whether the quality of the training model meets the expected amount of data, or the expected quality. That is to say, when analyzing and discriminating the data in the complete data set U, Whether the training model can accurately label the data can be verified by experiments to determine how well the training model fits the labeled data with the labeled data.
[0079] S800: When the amount of data in the labeled dataset A is less than the expected amount of data, take the union of the training dataset T and the labeled dataset A, and execute steps S500-S600 again.
[0080] When it is determined that t...
Embodiment 2
[0082] In another embodiment, the label data generation method further includes the following steps:
[0083] S700: Determine whether the amount of data in the labeled data set A' is greater than or equal to an expected amount of data;
[0084] First of all, it is necessary to judge the amount of data in the currently obtained labeled data set A', and whether the quality of the training model meets the expected amount of data, or the expected quality. That is to say, when analyzing and discriminating the data in the complete data set U, Whether the training model can accurately label the data can be verified by experiments to determine how well the training model fits the labeled data with the labeled data.
[0085] S800': When the amount of data in the labeled dataset A is less than the expected amount of data, replace the data in the fake dataset F with the data in the labeled dataset A, and execute steps S300-S600 again
[0086] Different from the trust in the training res...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com