Parallel random forest algorithm for processing unbalanced big data
A random forest method and big data technology, applied in the field of unbalanced big data classification, can solve the problems of deepening the influence of data bias, reducing classification efficiency, and low density of positive samples
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0024] specific implementation plan
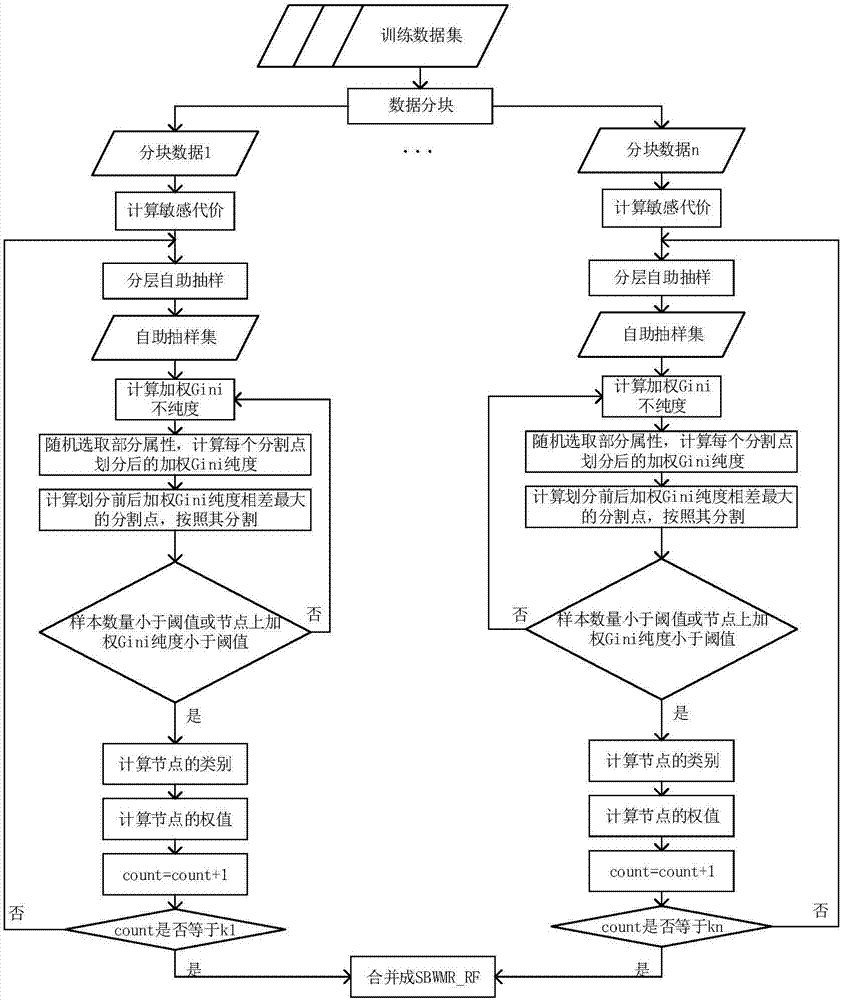
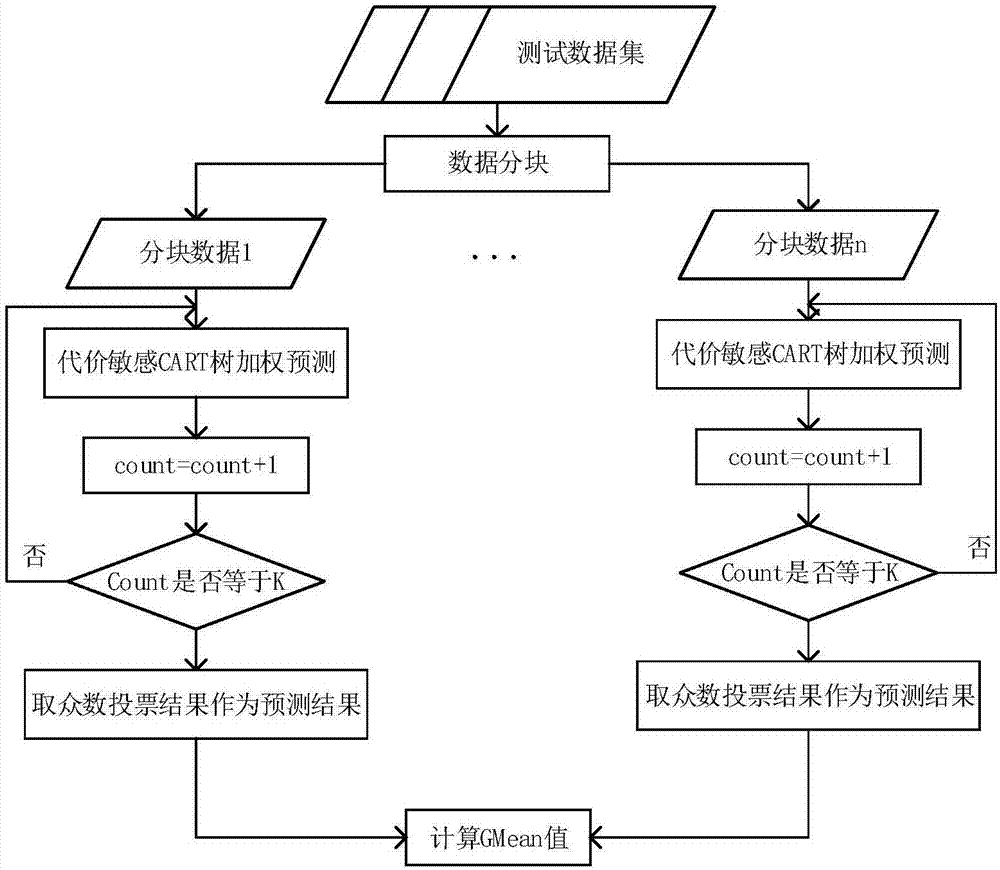
[0025] The invention designs a parallel random forest algorithm for effectively dealing with unbalanced data classification problems in a big data environment. The specific process is divided into two parts: model building and classification prediction, which will be combined with figure 1 , figure 2 The flowchart description is as follows:
[0026] When the SBWMR_RF algorithm is building a model, multiple blocks are processed in parallel. First, use the Hardtop platform to divide the data into blocks and send them to different data nodes, and then calculate the cost matrix of each block, see formula (1), C(-,+) uses a dynamic local imbalance index to avoid splitting Blocks deepen imbalances. The data key-value pair is used as input, the key is the binary stream encoding an instance, and the value is the specific data of each instance. Stratified self-sampling is performed on each block data, and then the final sample data set {sd ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com