


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A GEMM (general matrix-matrix multiplication) high-performance realization method based on a domestic SW 26010 many-core CPU
A dense matrix, realization method technology, applied in program control design, instrument, electrical digital data processing and other directions, can solve the problem of low performance, open source BLAS math library Shenwei many-core processor 26010 optimized, can not give full play to many-core computing Ability and other issues to achieve the effect of improving function performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0036] The present invention will be described in detail below in conjunction with the accompanying drawings and embodiments.
[0037] Such as figure 1 As shown, the specific implementation adopts the three-level code framework of "interface interface layer-scheduling task scheduling layer-kernel assembly computing layer", which is described as follows:
[0038] (1) Interface interface layer function: This layer is a function interface, which checks the input parameters and returns an error code if an illegal parameter is judged; in addition, according to the accuracy and transposition of the input matrix A, B, call the corresponding scheduling Task scheduling layer function;
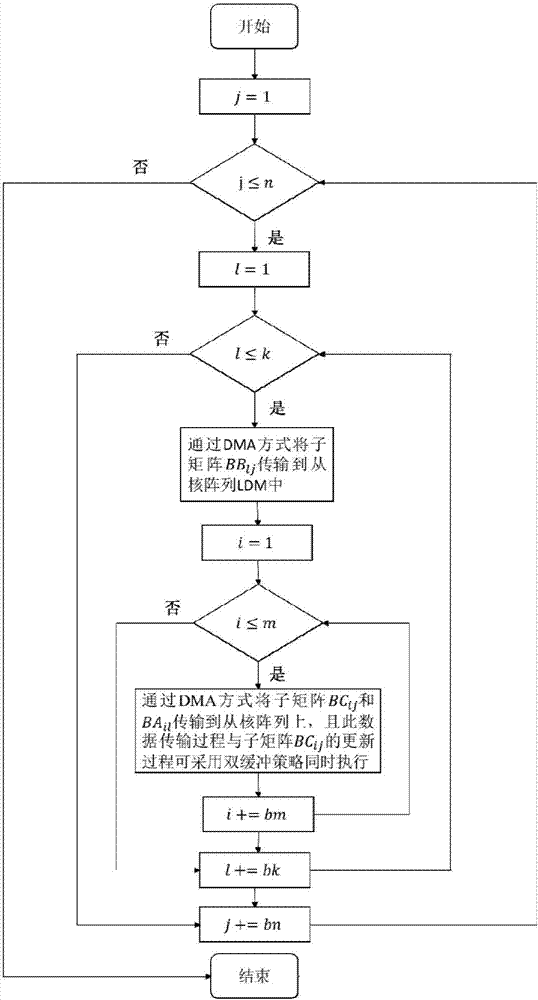
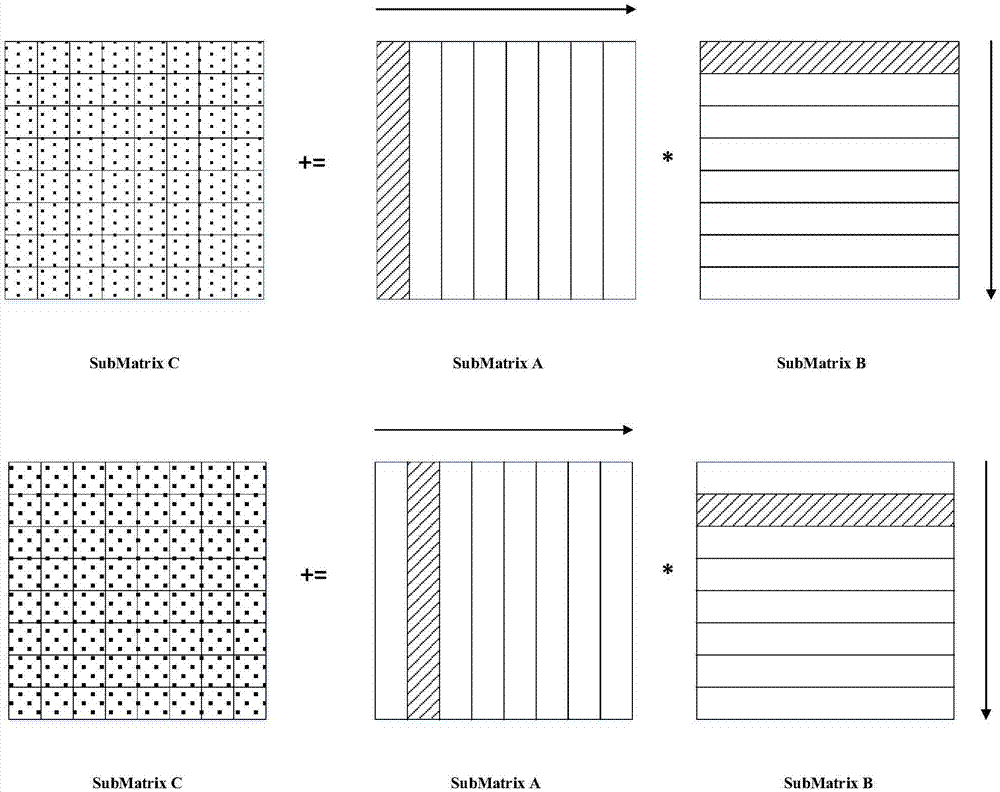
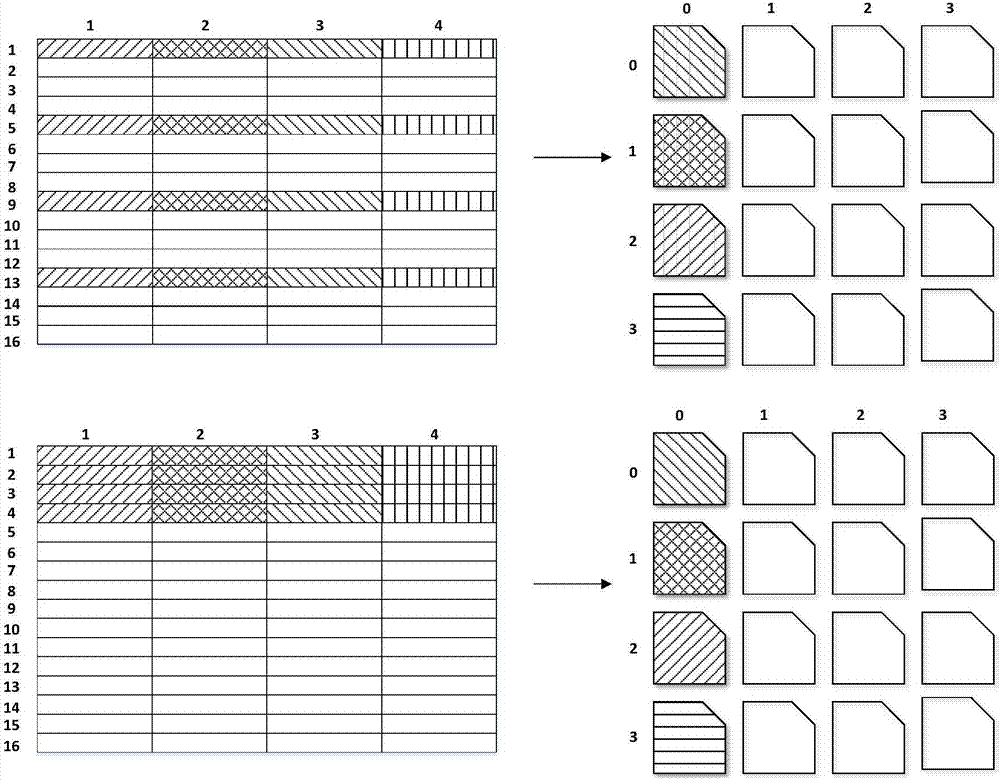
[0039] (2) Scheduling task scheduling layer function: It is called by the interface interface layer function, and calls the kernel assembly computing layer function. The updating order of the matrix C is controlled through the n-k-m three-layer loop, and the C sub-matrices are updated serially, with ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com