Wikipedia-based Chinese and English cross-language entity matching method
A Wikipedia, matching method technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as non-compliance with the LOD open principle, knowledge integrity and reliability loss, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

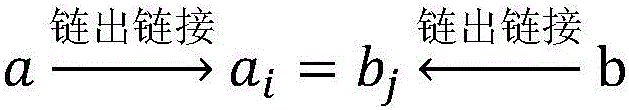
Examples
Embodiment
[0141] An example is provided below to describe the implementation steps of the present invention in detail:
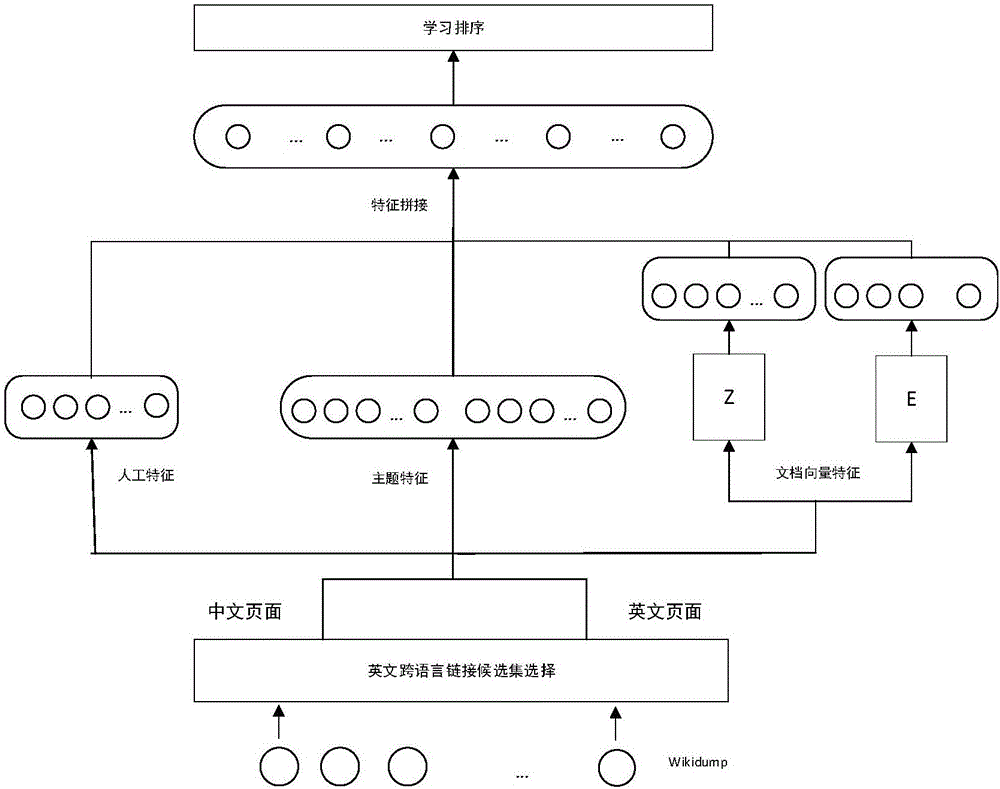
[0142] (1) The data sets used in the example come from Chinese Wikipedia and English Wikipedia. The number of pages in Chinese Wikipedia is 1,020,863, and the number of pages in English Wikipedia is 6,144,107. Analyze the information structure of the above pages, extract titles, abstracts, directories, categories, link-in links, link-out links, full-text text and other information, and store these information in the lucene index. Except for the title, other fields can be null.
[0143](2) Randomly select 3,000 pages with existing cross-language links from the Chinese Wikipedia in (1), and use the outgoing links and existing cross-language links to extract the English cross-language page candidate set of these 3,000 Chinese pages .
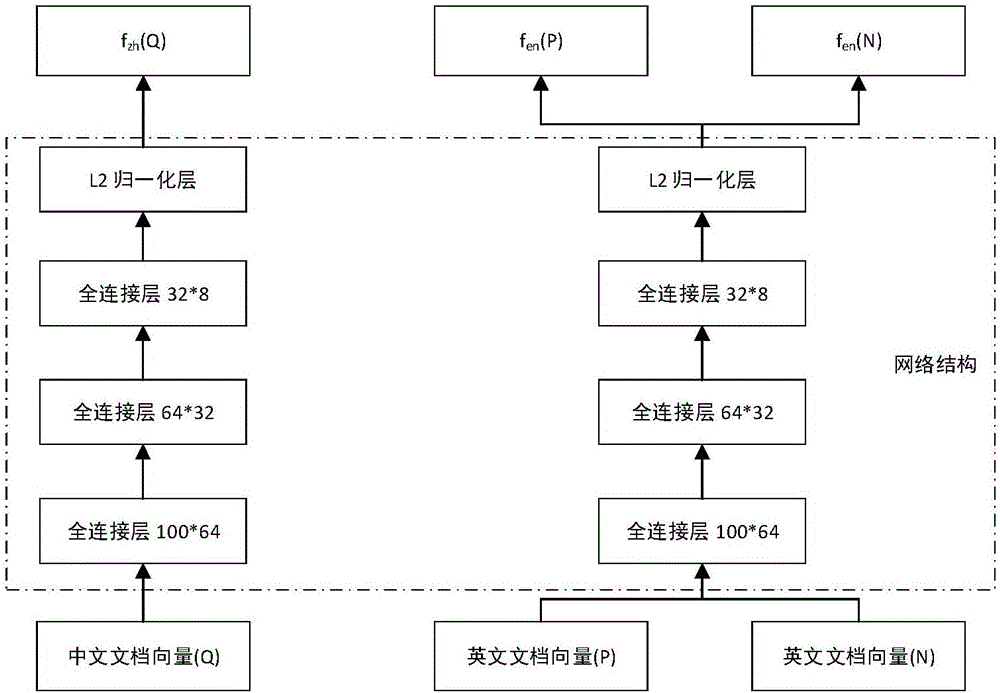
[0144] (3) Use the existing cross-language links to construct training data and train the parameters in the latent Dirichlet distributi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com