Online learning-based super computer node active fault-tolerant method
A technology for supercomputers and node failures, which is applied to the redundancy of calculations and operations for data error detection, generation of response errors, etc., and can solve problems such as high fault tolerance overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
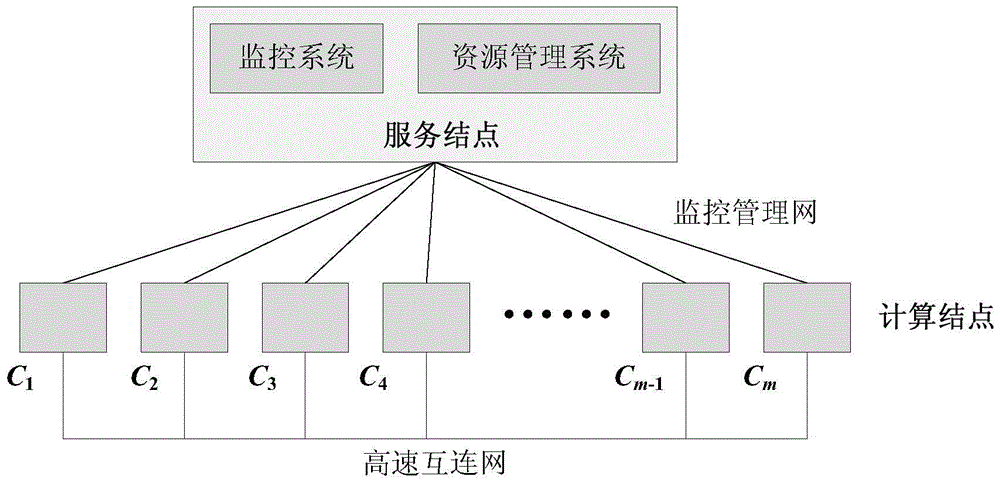
[0072] figure 1 It is a schematic diagram of the execution effect of each computing node using the traditional system-level checkpoint recovery method (Research and Analysis of Du Yunfei's Fault-Tolerant Parallel Algorithm, National University of Defense Technology, Doctoral Thesis, 2008, pages 7-12, 30-32), T c is the time required to perform a system-level checkpoint, T rc is the recovery time for a failure. The unshaded part in the figure is the time for the system to execute computing tasks. Assume that the cross-shaped position is the time point when the fault occurs, and the triangular position is the position where the program continues to execute after the fault is recovered. Taking the petascale supercomputer system "Tianhe-1" as an example, the mean time between failures (MTBF) of the system is several hours, and the time required to perform a system-level checkpoint T c It has reached more than ten minutes, the time T required to perform fault recovery rc Than T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com