Blended data clustering method based on density searching and rapid partitioning
A technology of mixed data and clustering methods, applied in the field of data clustering, can solve the problems of inability to determine whether the distance calculation method is reasonable, the accuracy is unstable, and the distance calculation method of mixed data type data cannot be directly and effectively processed.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
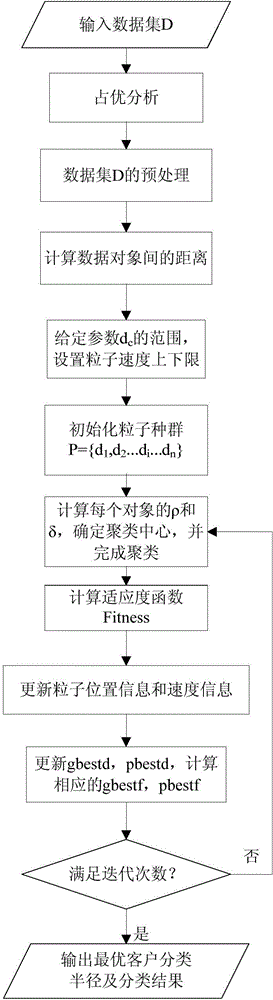
[0075] This embodiment takes the research object of "catalog marketing" (catalog market) of marketing, and the mixed data that needs to be clustered is customer information, that is, the collection of all customer information is used as the data set to be clustered. Each piece of customer information includes numerical attribute information such as age, income, and online duration, as well as classified attribute information such as gender, constellation, and consumer variety, using a hybrid data aggregation based on density search and fast division in this embodiment. The class method clusters all customer information, and then according to the clustering results, recommends specific products to different categories of users, and regularly releases marketing strategies such as similar people to buy items.
[0076] The hybrid data clustering method based on density search and fast division in this embodiment, such as figure 1 shown, including:
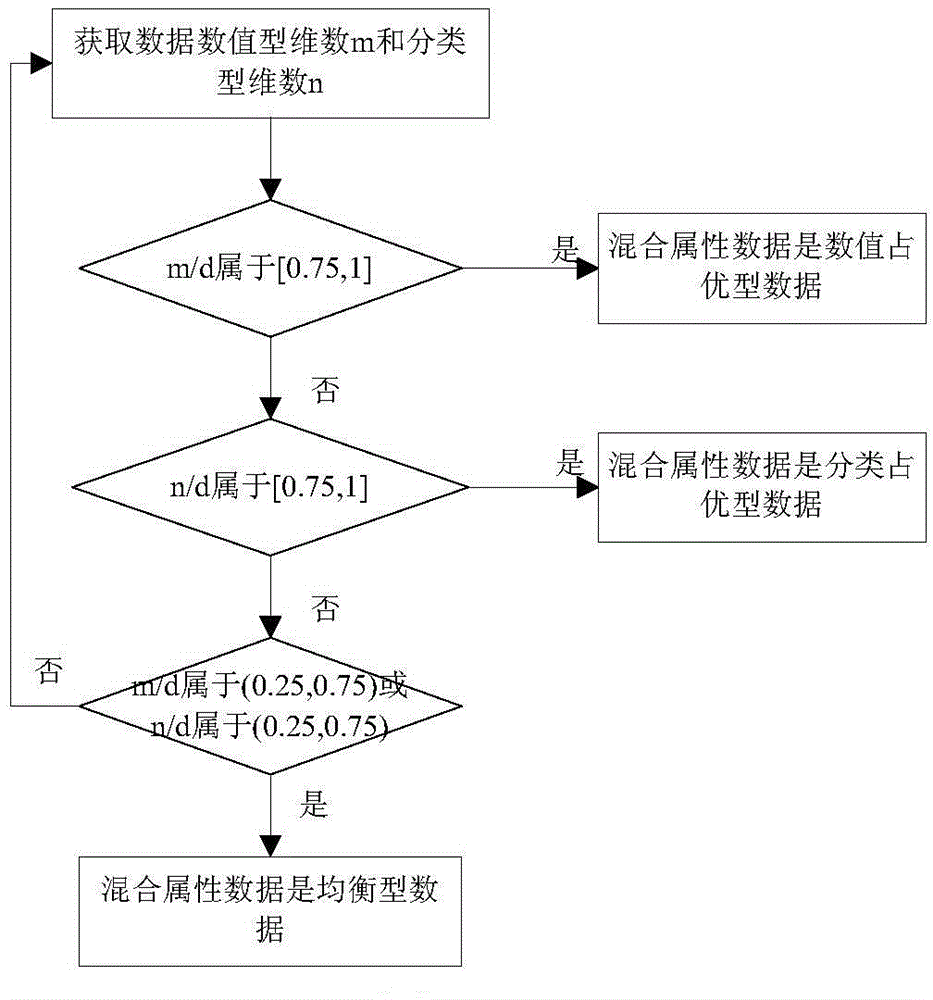
[0077] S1: Determine the domin...
Embodiment 2
[0152] The clustering method of this embodiment is completed based on the following experimental platform: the experimental platform includes a PC, the operating system is Windows 7, and the integrated development environment is Microsoft Visual C++2010. The hardware conditions are: CPU is Intel Core I52.6GHz, memory is 4GB.
[0153] In order to verify the performance of the new algorithm PSO-PD_HDC (that is, the hybrid attribute data clustering algorithm based on density search and fast partition), five real data sets are used, which are all from UCI and its learning library (Machine Learning Repository ), the specific information is shown in Table 3.
[0154] table 3
[0155]
[0156] The clustering method (PSO-PD_HDC clustering), IWKM algorithm, SBAC algorithm, K-prototypes algorithm and KL-FCM-GM algorithm of this embodiment are used to cluster the above data sets respectively.
[0157] Among them, the parameters in the experiment are set as α1=α2=1.8, the inertia wei...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com