A Method of Webpage Text Extraction
A web page and text technology, applied in the computer field, can solve problems such as low performance, spam information, and small problems, and achieve the effects of improving work efficiency, high analysis efficiency, and accurate results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
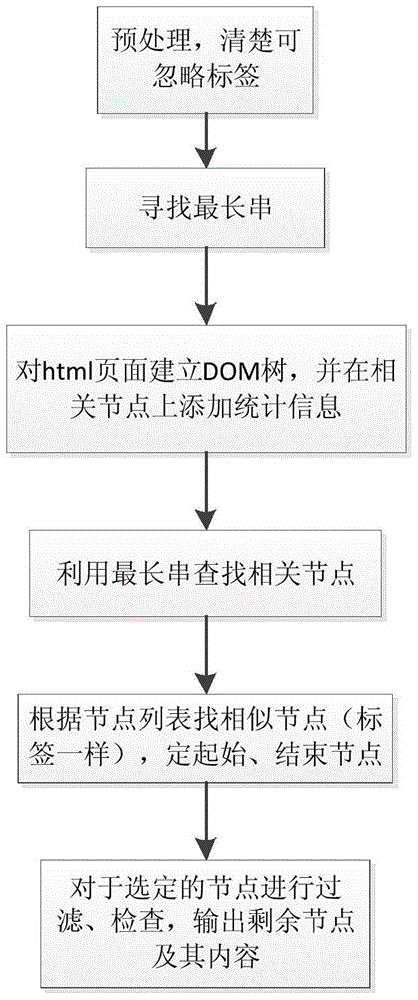
[0032] The specific embodiments of the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0033] A web page contains information such as text title, text source, text release time, text, author, etc. The web page may also include a large number of advertisements, spam, etc., and the "longest string" in news web pages mostly appears in the text. features to find a paragraph in the text area and obtain its corresponding label features, and then use the found label features to search forward, backward, and bidirectionally for similar label nodes. This process is referred to as "label clustering".
[0034] A method for extracting the text of a webpage, according to searching for "longest string" to search for iconic nodes to realize the extraction of news webpage text content, said method comprises the following steps: 1, deleting the negligible label in the said webpage and the negligible label in the Content; II, looking ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com