Semi-supervised dimensionality reduction method for high dimensional data clustering
A high-dimensional data, semi-supervised technology, applied in the field of data processing, can solve the problems of dimensionality disaster, unsuitable cluster analysis dimension reduction method, data complexity, etc., to achieve improved discrimination ability, good interpretability, cluster analysis simple yet effective effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0038] In order to describe the present invention more specifically, the dimensionality reduction method of the present invention will be described in detail below in conjunction with the drawings and specific embodiments.
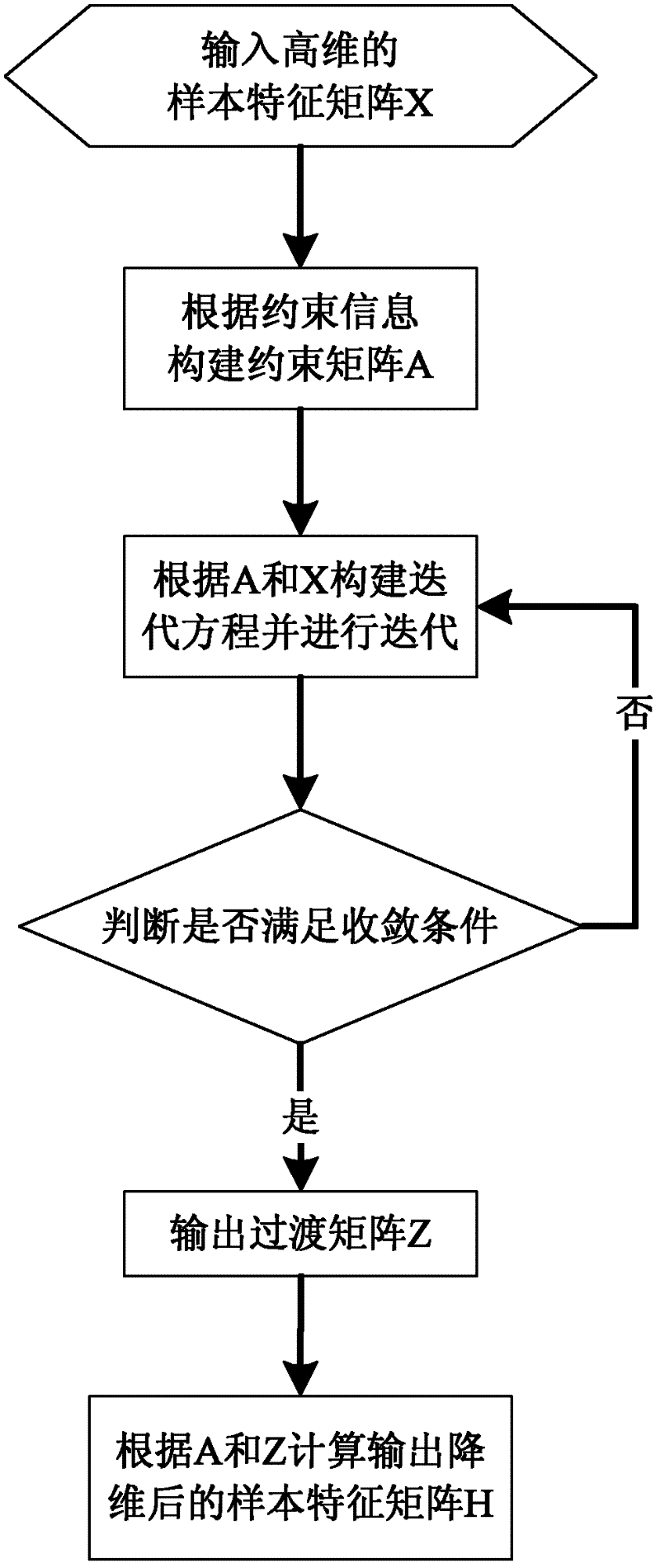
[0039] Such as figure 1 As shown, a semi-supervised dimensionality reduction method for high-dimensional data clustering, including the following steps:
[0040] (1) Construct sample feature matrix.
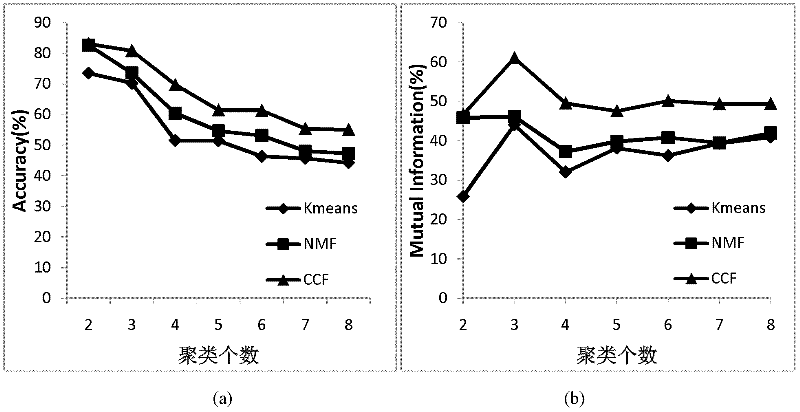
[0041] In this embodiment, the Yale face data set is taken as an example, and the statistical information of the data set is shown in Table 1.
[0042] Table 1: Yale face dataset statistics
[0043] data set Face image frame number Number of face categories number of image features Yale 165 15 1024
[0044] Among them, there are 165 frames of face images in the Yale face data set, and the 165 frames of face images are composed of 15 face images of people with different appearances (11 frames of face images for each person). ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com