A Chinese Text Classification Method Based on Correlation Learning Between Categories
A text classification and correlation technology, applied in the field of Chinese text classification algorithm research, can solve the problems of large amount of algorithm operation and long operation time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
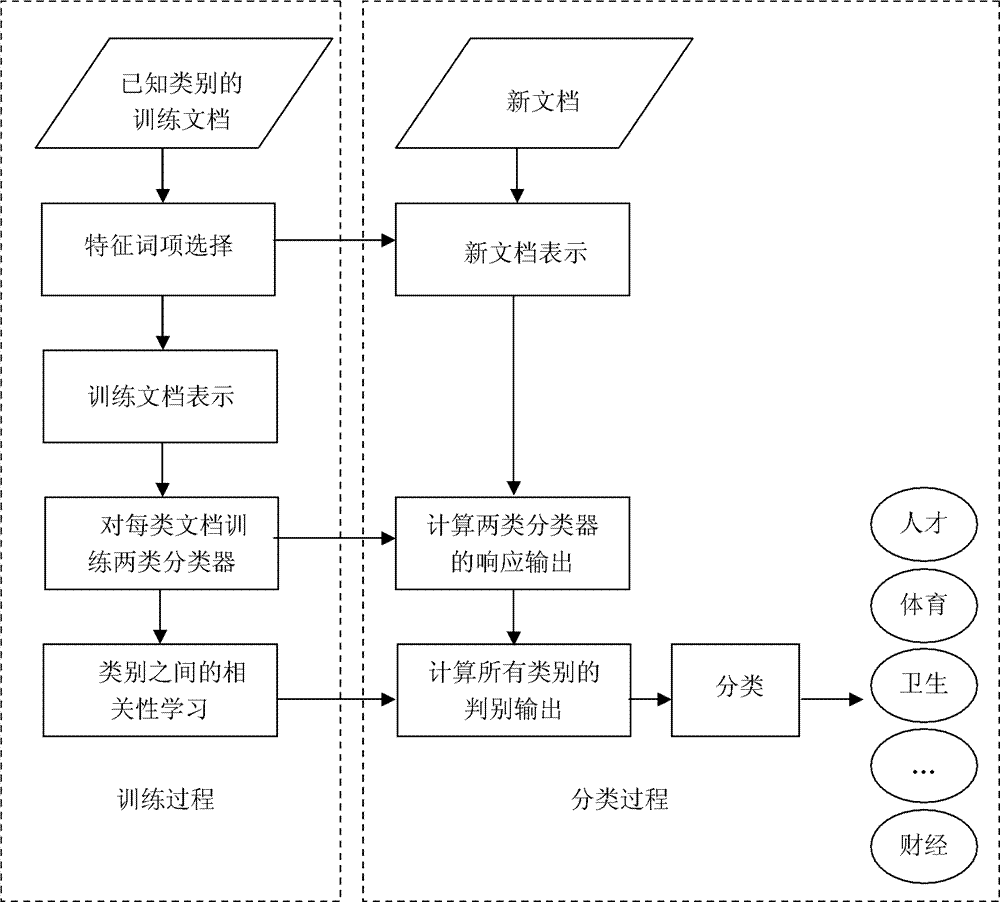
[0076] Such as figure 1 As shown, the Chinese text classification method based on correlation learning between categories includes the following steps:
[0077] (1) Training process:
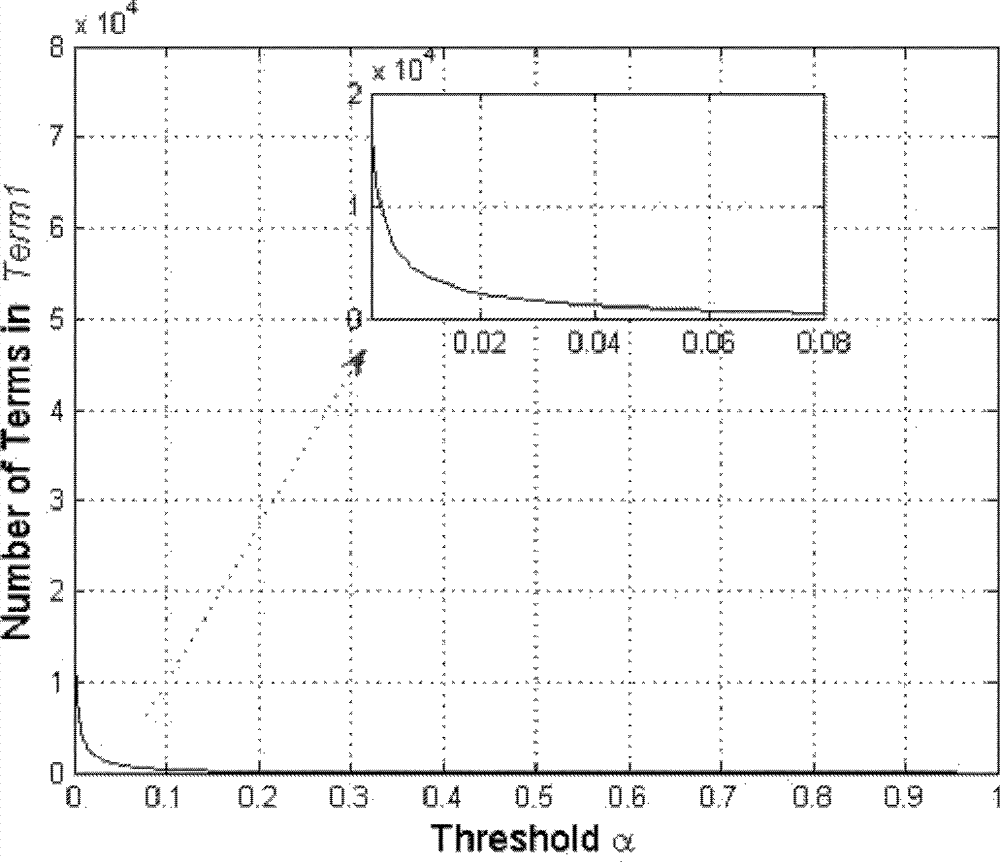
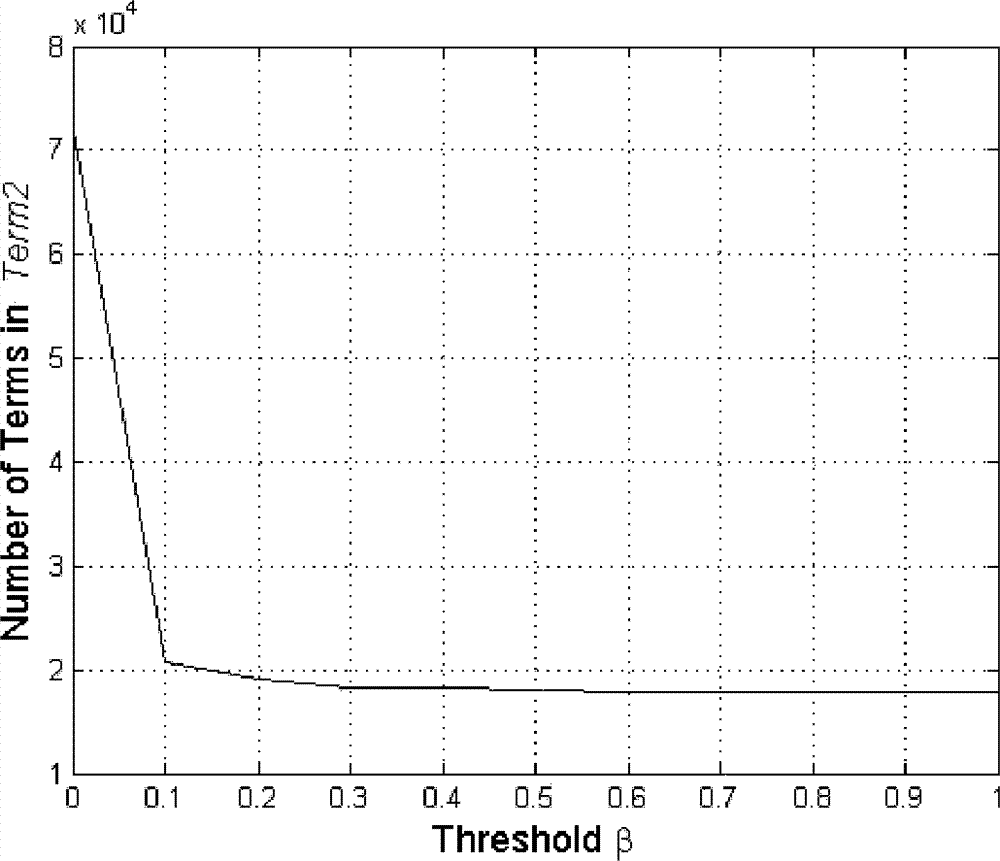
[0078] (1-1) Feature selection: For all Chinese terms, there is a standard dictionary, which contains a complete set of terms, and all terms in the set form a term index according to the order of the phonetic sequence. The goal of feature selection is to select representative terms from the dictionary to form feature terms, and also to form feature indexes based on the phonetic sequence. The specific process is: read in all the training documents, and segment the documents. After the training document is segmented, the word frequency of each term is counted sequentially according to the index order of the terms in the dictionary. Select the frequently appearing terms in the training documents to form a feature subset after rough selection, and further determine the representative terms after ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com