


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Large scale key word matching method
A keyword matching and keyword technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve the problems of non-randomness, affecting HASH-AV keyword matching efficiency, and high false alarm rate, achieving The effect of reducing the high rate of false positives, improving retrieval efficiency, and improving matching efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
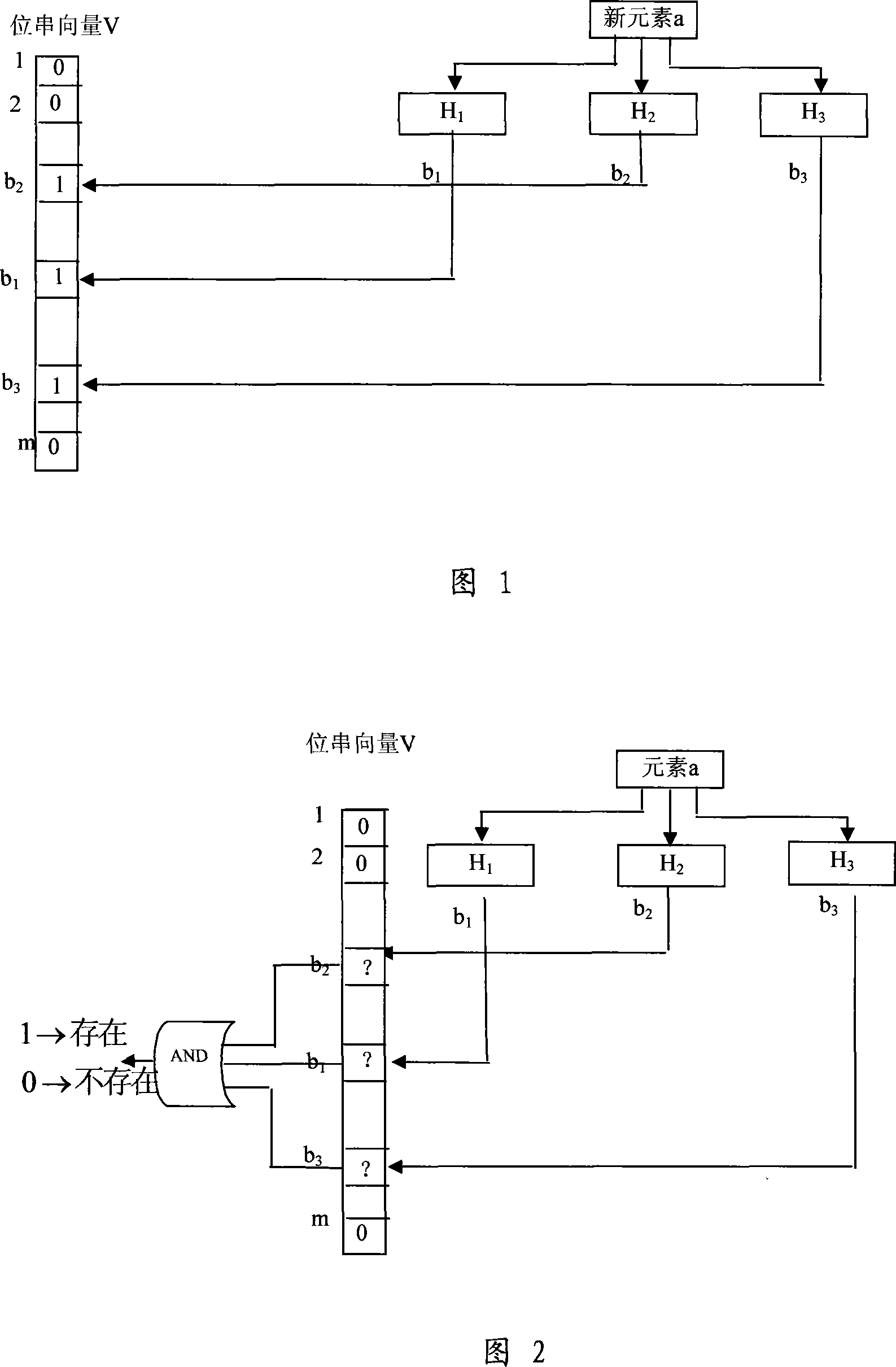
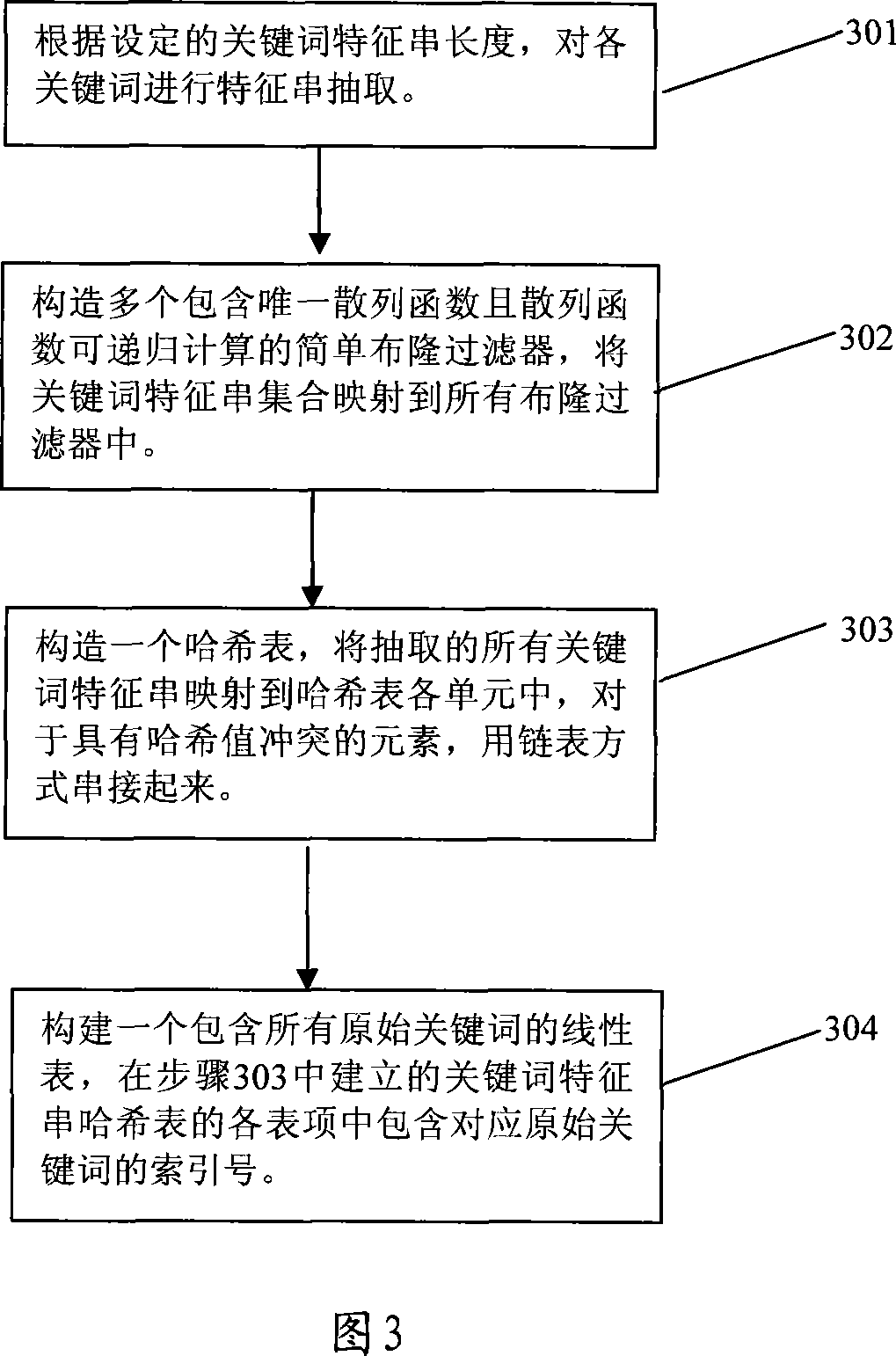
[0041] Suppose there are K original keywords to be searched, expressed as P={P 1 , P 2 ,...,P k}. In practical applications, the lengths of the original keywords to be searched are not equal. In order to facilitate the parallel matching of multiple keywords, the present invention needs to cut all keywords to equal length, that is, to select a keyword substring length value W, and for each original keyword P in the set P i , cut it into a keyword substring M of W byte length i . This cropped keyword substring M of W byte length i Keyword feature strings called raw keywords. By extracting each keyword feature string M i The composed set is the set M of keyword feature strings. Note that when selecting the length of the keyword feature string, the value of W cannot be greater than the length of the shortest keyword in the original keyword set. The simplest clipping method is to take the W byte prefix or suffix of each keyword as the keyword feature string of the original...
Embodiment approach
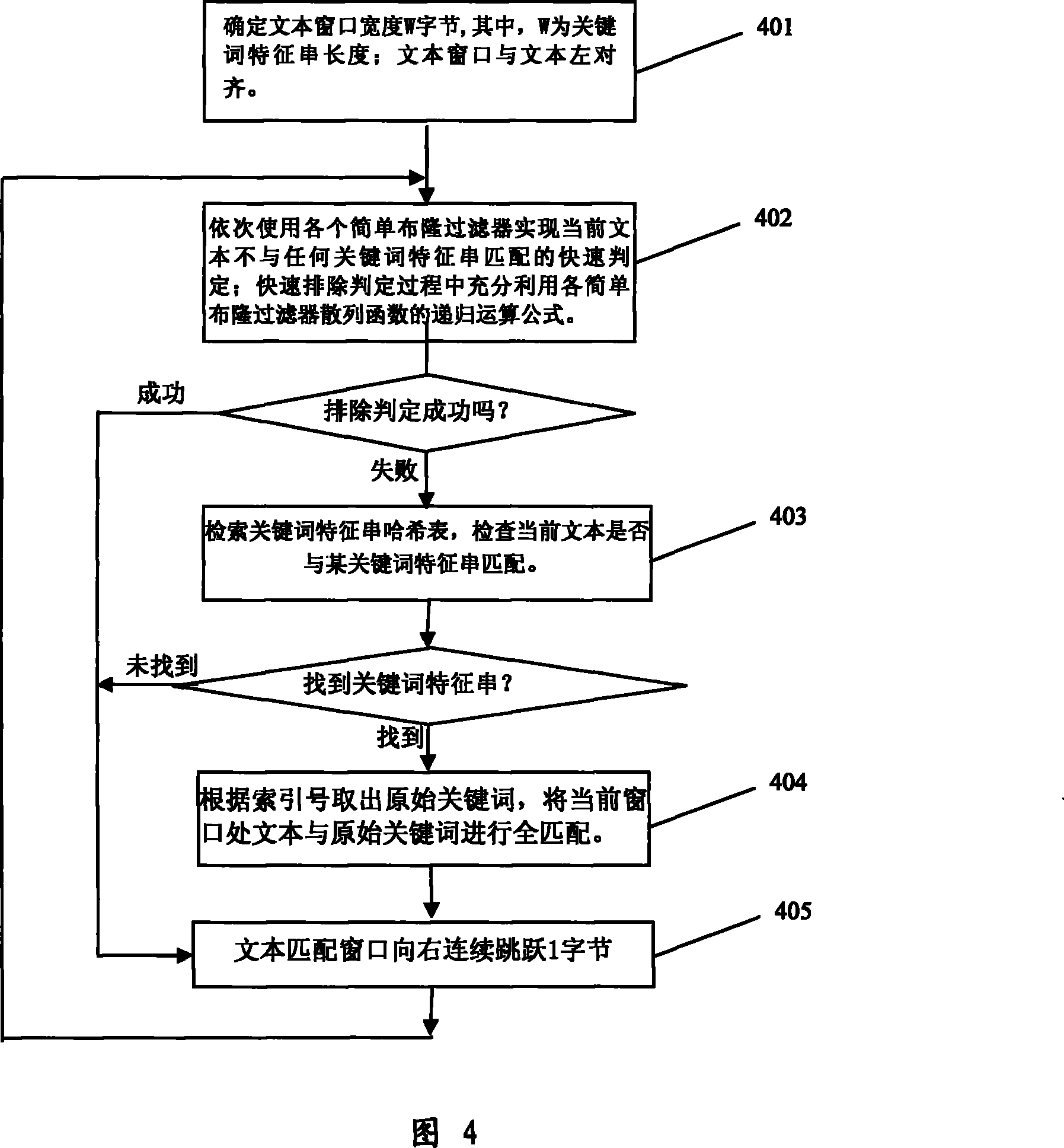
[0055] When implementing the present invention, the step A1 of the preprocessing stage A described in the present invention can adopt the following preferred implementation mode: for keyword set P={P 1 , P 2 ,...,P k} for each keyword P i , the extracted keyword feature string M i is the keyword substring with the least number of occurrences in the entire keyword set.
[0056] The following method can be used to make the extracted keyword feature string M i is the keyword substring with the least number of occurrences in the entire keyword set:
[0057] a) Establish a hash table for storing all possible keyword substrings with a length of W;
[0058] b) for any length n i The original keyword P i , can be divided into (n i -W) keyword substrings with a length of W, for each segmented keyword substring, first judge whether it has appeared in the keyword substring hash table: if not in the hash table, create a new The keyword substring table entry, and the counter value...
Embodiment 2
[0071] The entire technical solution of the present invention will be further described below through an embodiment.
[0072] Suppose the keyword set is P={abcdefahijk, abcopqrst, wyzopqhijk}, and the text to be matched is bcgilmnommlmloptrstuvabc.
[0073] According to the pretreatment process of the inventive method as follows:
[0074] First, the length of the keyword feature string is determined and the keyword feature string corresponding to each keyword is cut out. Here, the keyword length is selected to be 6 bytes, and the characteristic strings of each keyword are selected according to the principle of the least occurrence of keyword substrings. The finally obtained keyword characteristic string set is M={bcdefg, copqrs, pqhijk} (note that the minimum There may be multiple keyword substrings for the occurrence principle, and one of them can be randomly selected in practical applications).
[0075] Then, start to construct three simple Bloom filters based on the set M...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com