Voice decoding method based on mixed network
A technology of confusing network and speech decoding, applied in the field of speech decoding based on confusing network, to reduce the workload, reduce the network, and improve the decoding rate.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

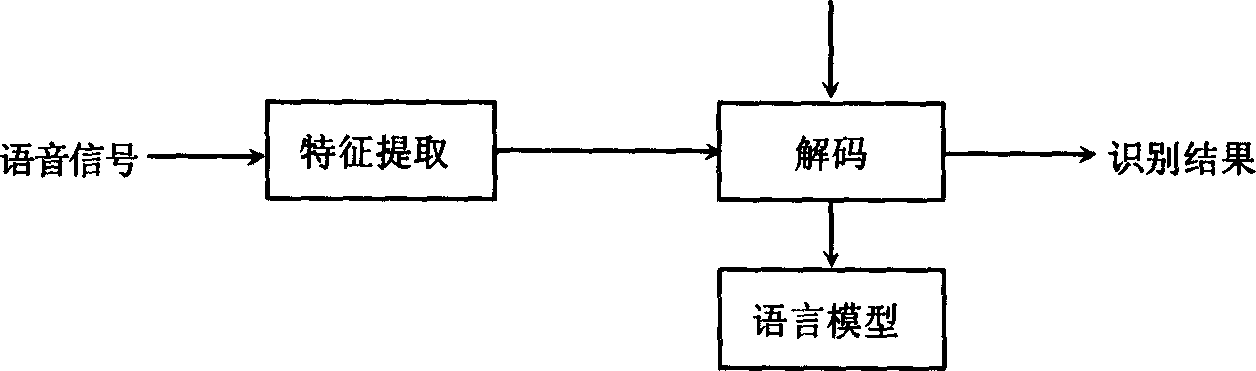
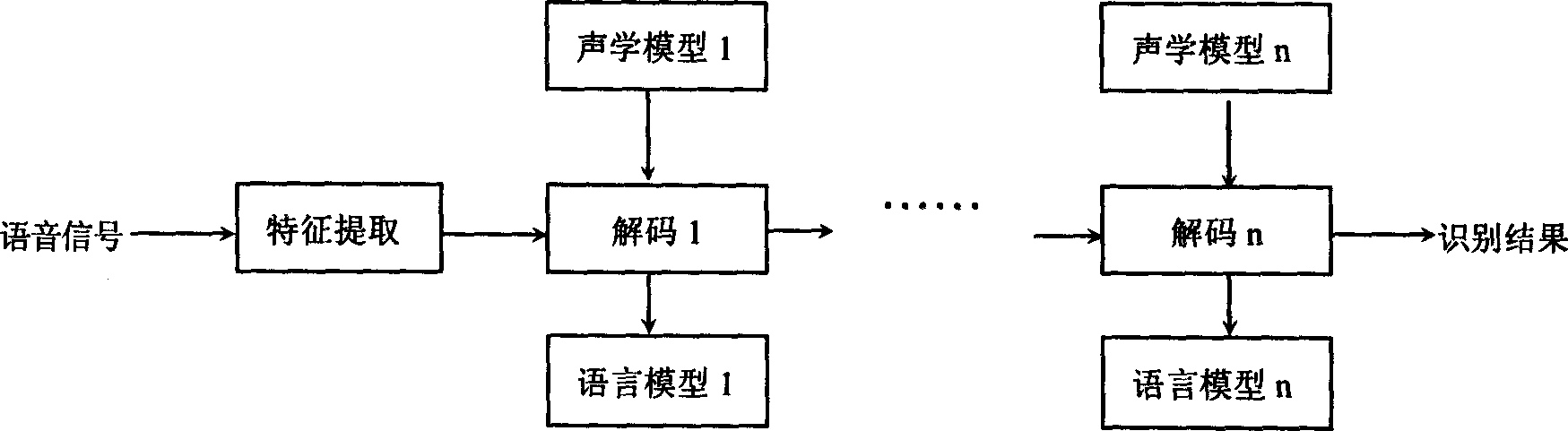
Examples
Embodiment Construction
[0035] The present invention will be further described below in conjunction with the accompanying drawings and preferred embodiments.
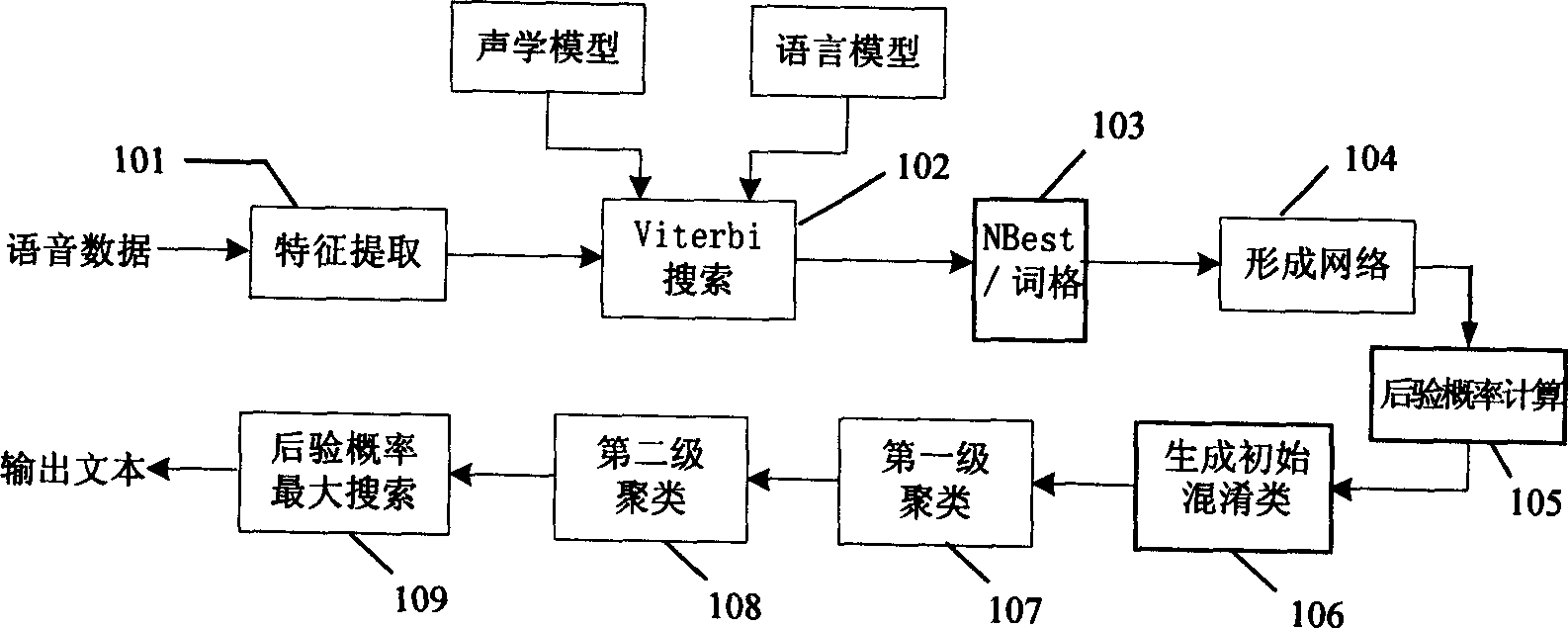
[0036] Such as image 3 As shown, the speech decoding method based on confusion network provided by the present invention comprises the following steps:
[0037] Step 101: Extract feature vector sequences from the input speech signal.
[0038] Step 102: Use the Viterbi-Beam search algorithm to decode the speech features for the first time, output the N-Best sentence or word lattice, and simultaneously obtain the acoustic layer probability score and language layer probability of each word in the N-Best sentence or word lattice Score.
[0039] Step 103: If the intermediate result of output in step 102 is NBest sentence, then it is compressed into directed network structure with merging algorithm, the flow process of this merging algorithm is as follows Figure 4 As shown, it is a prior art, so it will not be described in detail here. If the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com