Cross-modal generation method based on voice and face images
A face image and speech synthesis technology, applied in the field of deep learning, to achieve the effects of accelerated convergence, strong robustness, and scientific and reasonable design
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
[0026] The present invention will be further described in detail below through the specific examples, the following examples are only descriptive, not restrictive, and cannot limit the protection scope of the present invention with this.
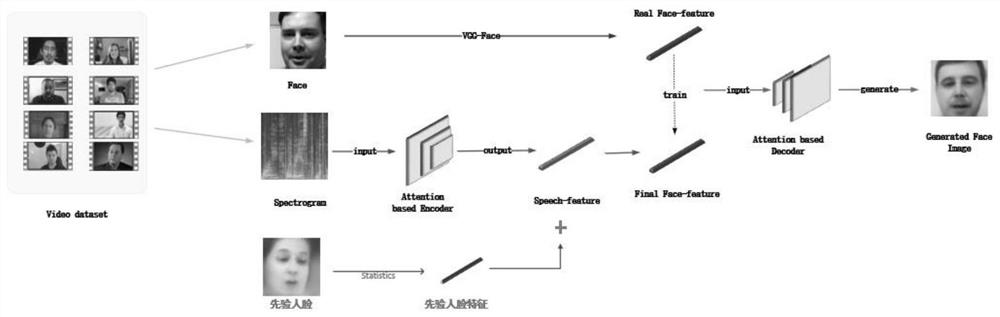
[0027] A transmembrane state generation method based on voice and face image, characterized in that: the method includes face reconstruction based on residual prior voice and personalized speech synthesis of residual prior human face image.
[0028] For Speech Reconstruction Face Model with Residual Prior, in order to alleviate the mismatch between speech and face in speech-based face generation, an end-to-end encoder-decoder structure based speech reconstruction face model is proposed , this structure complements the speech features in the speech extraction network with additional prior facial features. Two prior facial features (i.e. neutral and gender prior facial features) were explored according to gender. Furthermore, the encoder and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com