


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A method and system for region extraction of news text based on xlnet
A region and text technology, applied in the computer field, can solve problems such as inability to model, loss of model performance, and inability to learn contextual information at the same time, and achieve the effect of high regional extraction quality and complete modeling
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
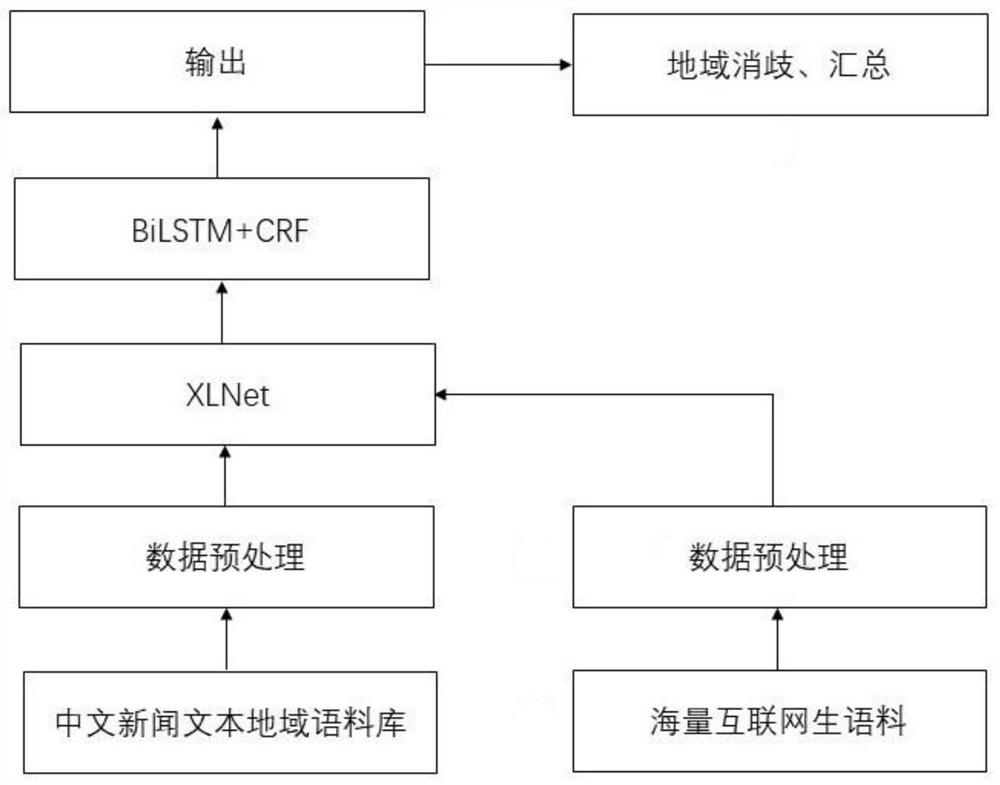
[0028] like figure 1 As shown in the figure, a method for extracting news text regions based on XLNet includes the following steps:
[0029] S1. Pre-training: Use crawler technology to obtain massive unlabeled raw corpus from the Internet, and after denoising and preprocessing the unlabeled raw corpus, input it into the XLNet pre-training model for pre-training;
[0030] S2. Training: a. Under the BIOES labeling framework, manually annotate a regional corpus of Chinese news texts with labels to be used as model training corpus. b. Perform a general data preprocessing process on the model training corpus. c. The latter data is input into the XLNet pre-trained model pre-trained in the step S1 for encoding, d. The encoded hidden state is input into the BiLSTM+CRF model for identification, and the output layer outputs the identified regional entity;
[0031] The data preprocessing in steps S1 and S2 includes cleaning the unlabeled data, that is, removing useless text, and perform...
Embodiment 2
[0057] A system for regional extraction of news text based on XLNet, including a regional entity recognition module, an entity splicing module, a regional disambiguation module and a regional aggregation module. The regional entity recognition module is composed of an XLNet pre-training model and a BiLSTM+CRF model. Described XLNet pre-training model utilizes Internet unmarked data to complete pre-training and is used for coding of text to be recognized, and described BiLSTM+CRF model is used to carry out text region recognition to described text to be recognized after encoding to obtain regional subject, and described BiLSTM+CRF model The entity splicing module splices the regional entities according to the location information of the regional entities in the text, and the regional disambiguation module is used to match the regional entities with the artificially constructed provincial / city secondary same place name knowledge base Mapping to achieve disambiguation, and the reg...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com