Voice synthesis model training method and system, voice synthesis method and system, equipment and medium
A technology of speech synthesis and training methods, applied in speech synthesis, speech analysis, biological neural network models, etc., which can solve problems such as high cost, slow synthesis speed, and inability to meet order call requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
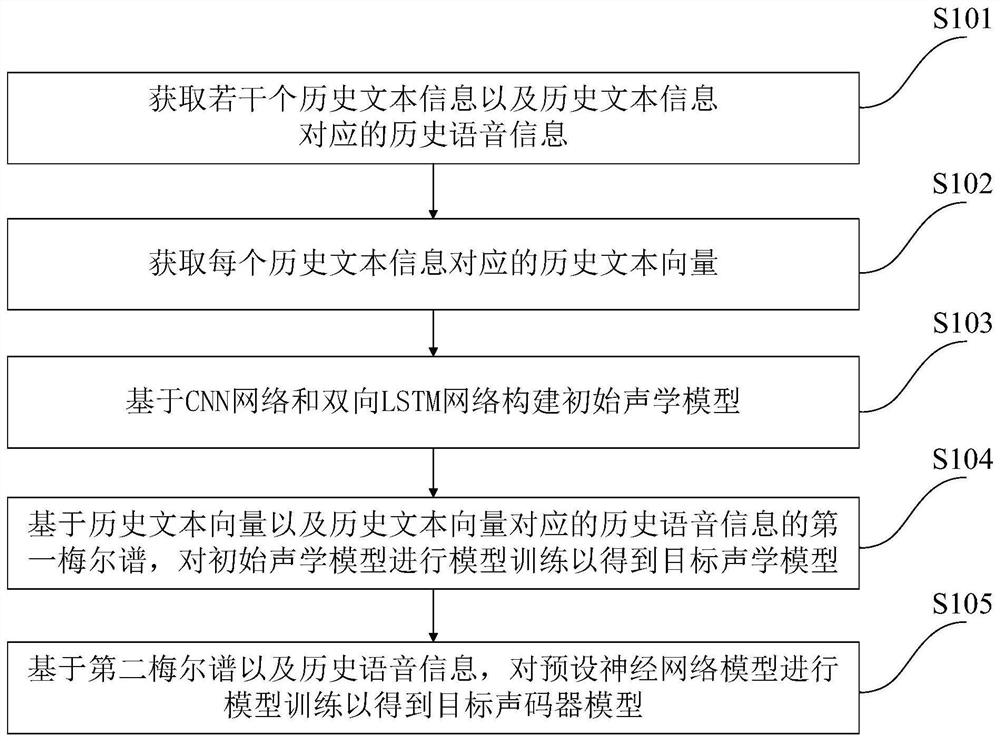
[0091] Such as figure 1 As shown, the training method of the speech synthesis model of the present embodiment includes:
[0092] S101. Obtain several pieces of historical text information and historical voice information corresponding to the historical text information;
[0093] Among them, the historical text information is obtained from the hotel customer service of the e-commerce platform and the call records of the hotel merchants; the historical voice information (historical audio files) corresponding to the historical text information is recorded in a recording studio by a special manual customer service. For example, a total of 10,000 16KHz historical audio files were recorded, with a total audio duration of about 10 hours, and the text corresponding to each audio was checked by a special manual.
[0094] S102. Obtain a historical text vector corresponding to each historical text information;
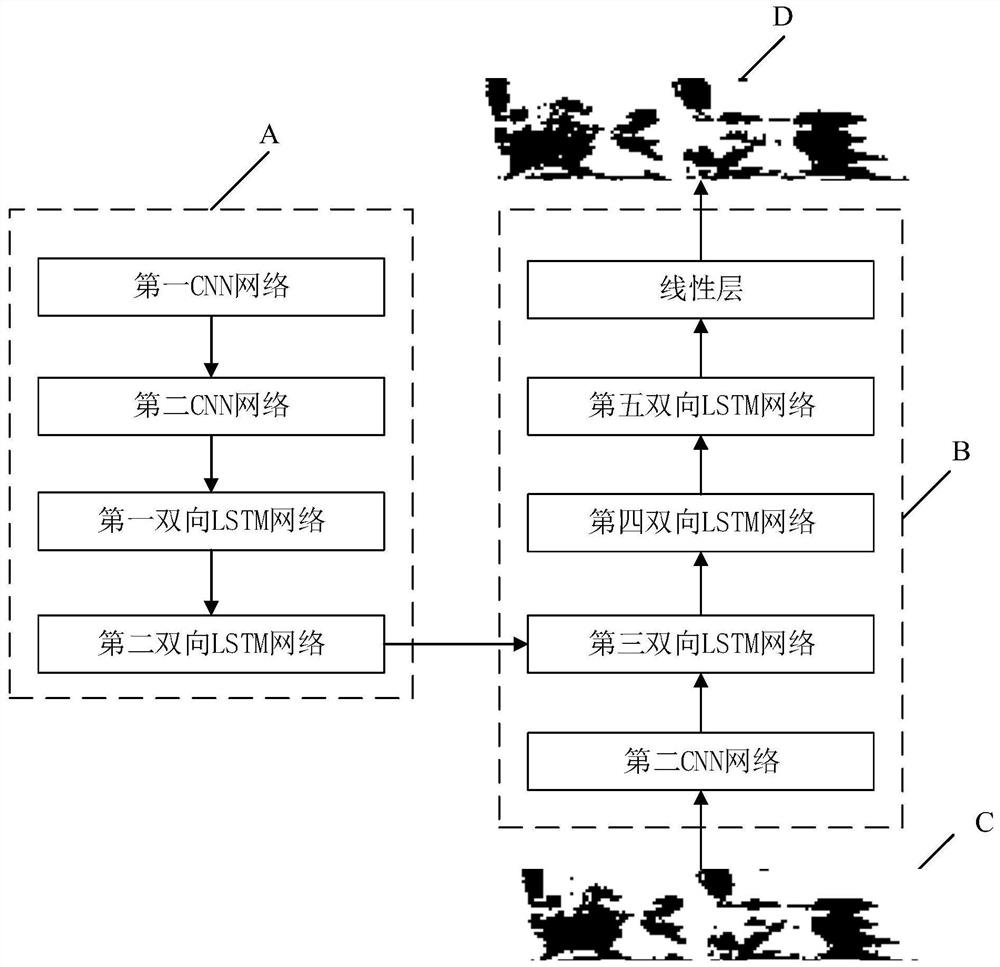
[0095] S103, constructing an initial acoustic model based on a CNN network...
Embodiment 2
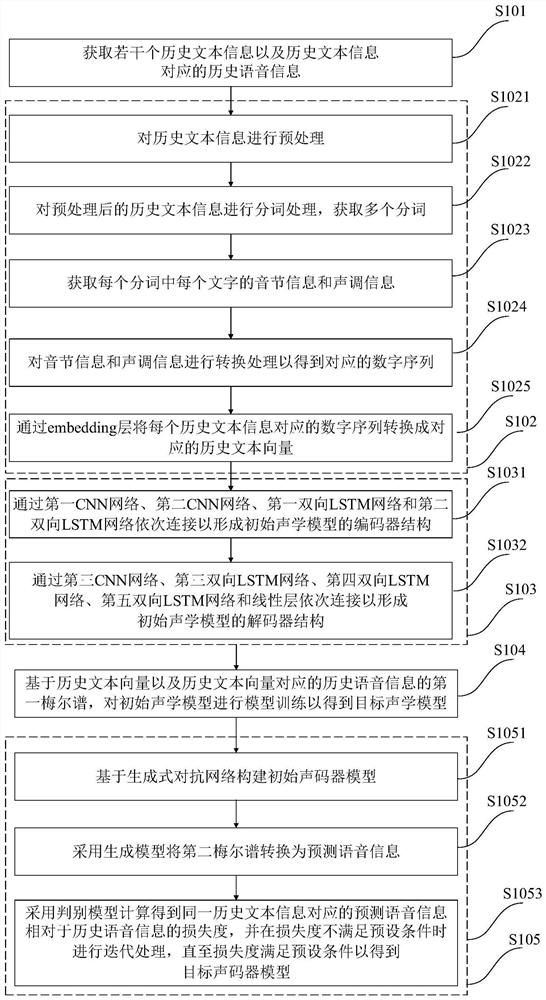
[0102] Such as figure 2 As shown, the training method of the speech synthesis model of the present embodiment is a further improvement to Embodiment 1, specifically:
[0103] Step S102 includes:
[0104] S1021. Preprocessing the historical text information;
[0105] Preprocessing operations include removing garbled characters and non-standard punctuation marks in historical text information, and converting Chinese punctuation into English punctuation; considering that numbers have different pronunciations in different scenarios, the numbers are replaced with different Chinese characters according to the keywords of matching statistics; Among them, the number conversion rules in different scenarios are inconsistent. For example, "the house price is 318 yuan" should be converted to "the house price is 318 yuan", and "room number 318" should be converted to "room number 318".
[0106] S1022. Perform word segmentation processing on the preprocessed historical text information t...
Embodiment 3
[0140] The speech synthesis method in this embodiment is realized by using the speech synthesis model training method in Embodiment 1 or 2.
[0141] Such as Figure 6 As shown, when the target vocoder model includes a generative model, the speech synthesis method of the present embodiment includes:
[0142] S201. Obtain target text information;
[0143] S202. Generate a target text vector according to the target text information;
[0144] S203. Input the target text vector into the target acoustic model in the speech synthesis model, output the target mel spectrum according to the input target text vector through the target acoustic model and transfer it to the target vocoder model;
[0145] S204. Using the generative model in the target vocoder model, convert the target mel spectrum to obtain target speech synthesis information corresponding to the target text information.
[0146] In this embodiment, based on the speech synthesis model obtained through training, the targe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com