Multi-target voice enhancement method based on SCNN (Stacked Convolutional Neural Network) and TCNN (Temporal Convolutional Neural Network) joint estimation
A joint estimation and speech enhancement technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problem of unsatisfactory speech enhancement performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
specific Embodiment approach
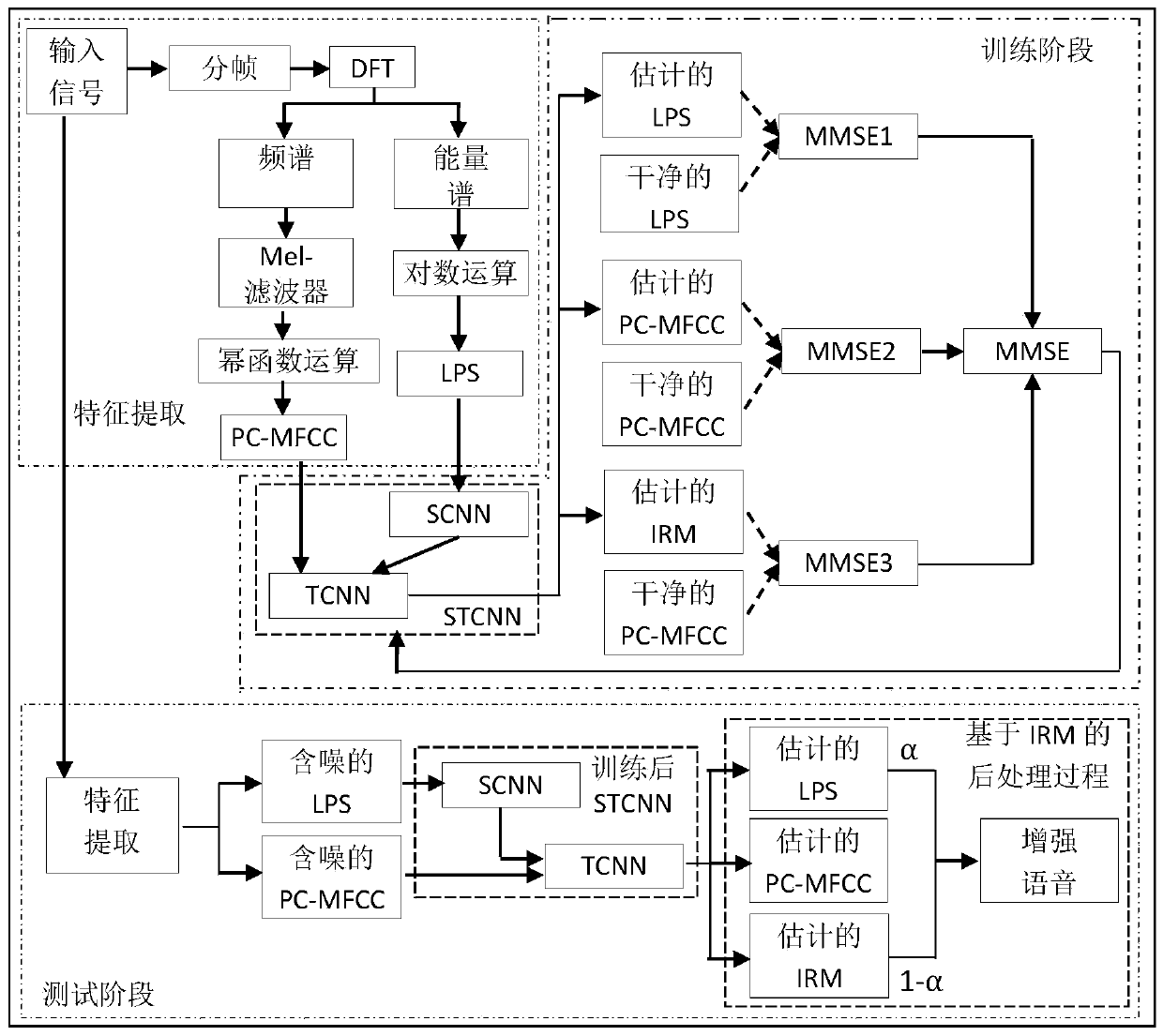
[0034] Such as figure 1 Shown, the present invention provides a kind of new speech enhancement method based on multi-objective learning, comprises the following steps:
[0035]Step 1, the input signal is subjected to windowing and framing processing to obtain the time-frequency representation of the input signal;
[0036] (1) First, time-frequency decomposition is performed on the input signal;
[0037] The speech signal is a typical time-varying signal, and the time-frequency decomposition focuses on the time-varying spectral characteristics of the components of the real speech signal, and decomposes the one-dimensional speech signal into a two-dimensional signal represented by time-frequency, aiming to reveal How many frequency component levels are contained in a speech signal and how each component varies with time.
[0038] First, the original speech signal y(p) is preprocessed in Equation (1), the signal is divided into frames, and each frame is smoothed by Hamming wind...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com