Unbalanced data set oversampling method based on genetic algorithm and k-means clustering
A genetic algorithm and data set technology, applied in the field of computer data mining, can solve the problems of reduced prediction accuracy, model overfitting, fuzzy overlapping of sample boundaries, etc., to reduce risks, distribute evenly, and improve the recognition rate.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
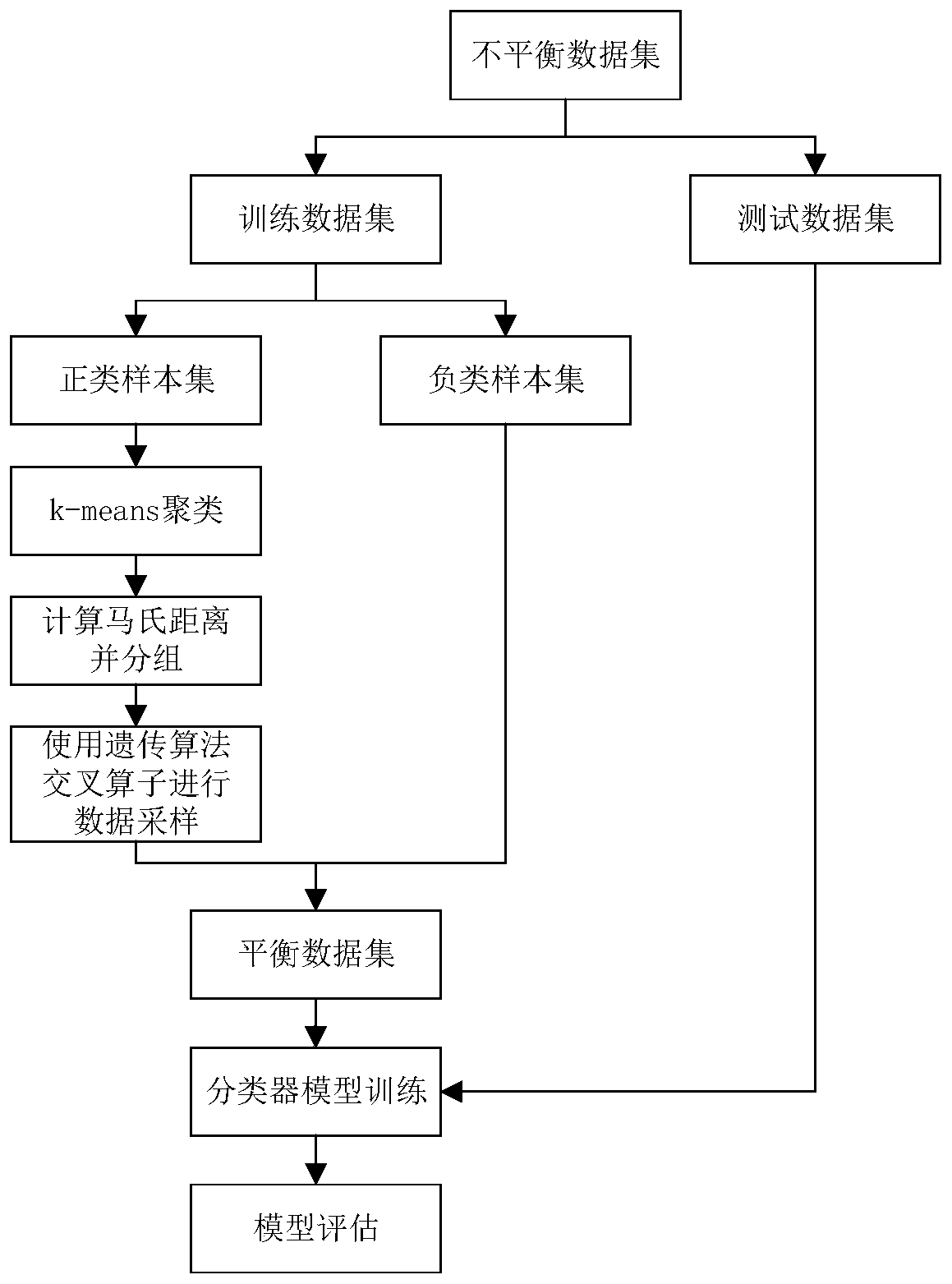
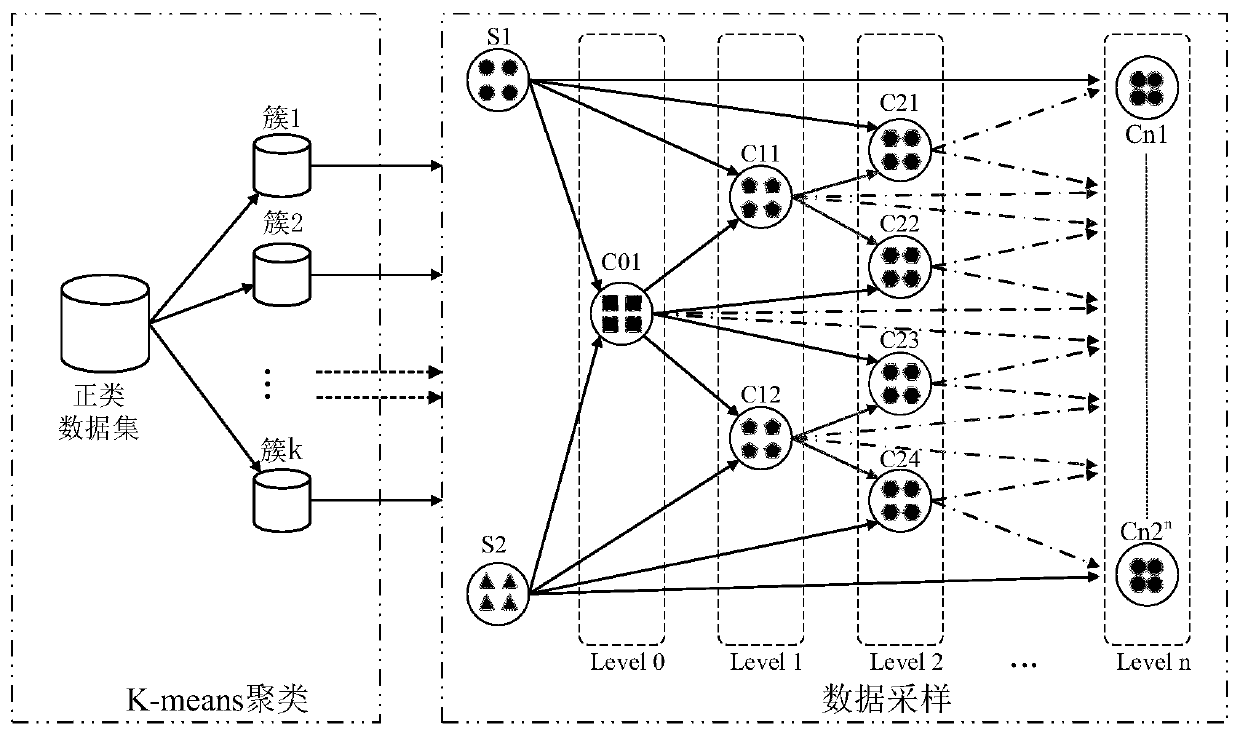
Embodiment
[0082] 1. Simulation environment
[0083] In this embodiment, the Python 3.5 programming language and KEEL software are used for testing. The experimental environment is a 64-bit Windows operating system, and the hardware configuration is Intel(R) Core i5-7300HQ CPU@2.50GHz, 8G memory.
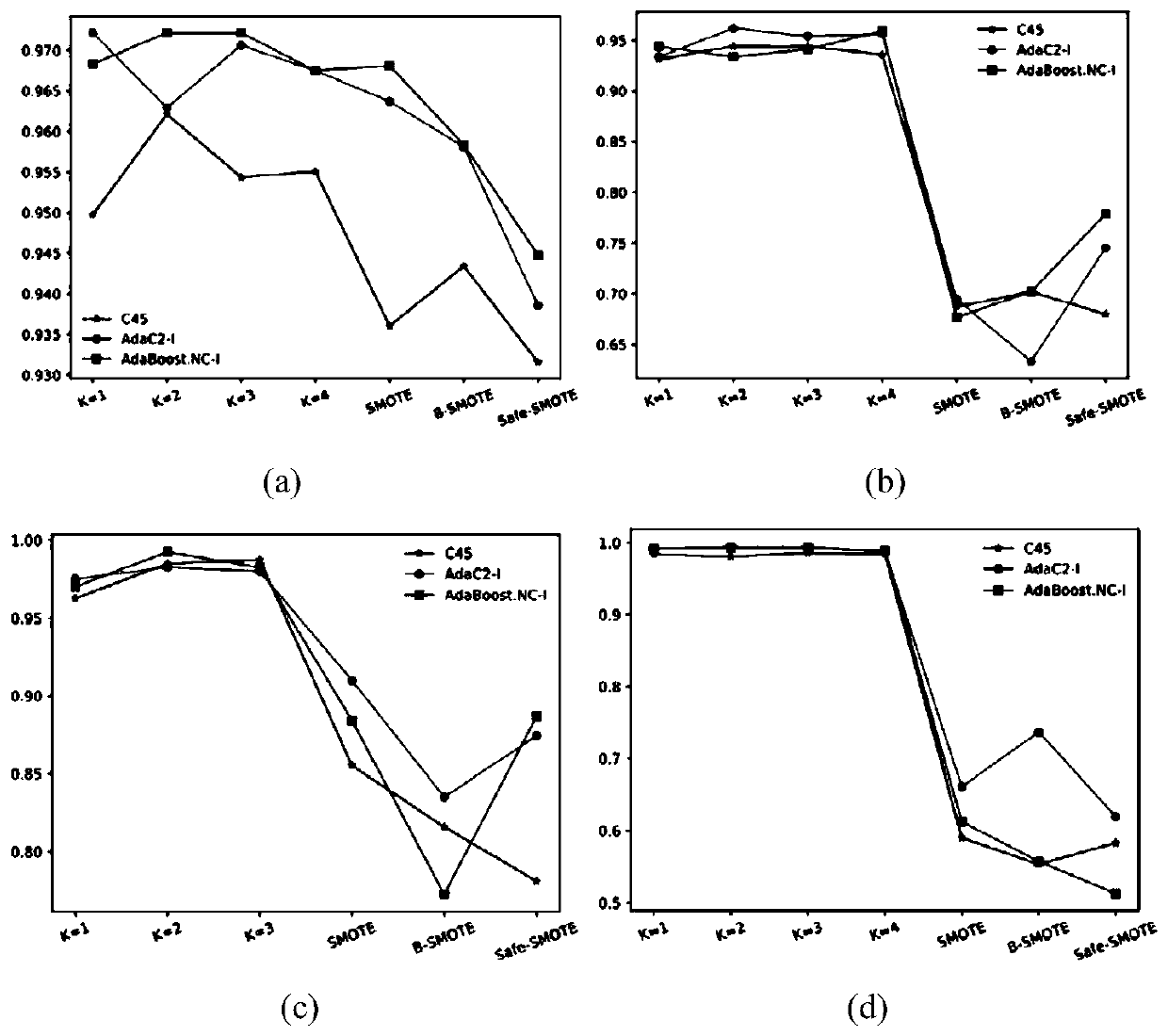
[0084] 2. Simulation content and result analysis
[0085] The data sets used in this example are all from the unbalanced data sets in the KEEL database, and their feature dimensions and unbalanced rates are different. The specific information is shown in Table 1 below.
[0086] Table 1 Experimental data set
[0087]
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com