Speech synthesis playing method and device, and storage medium
A technology of speech synthesis and playback method, which is applied in the field of speech and can solve problems such as the inability to accurately predict the pronunciation of polyphonic characters
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
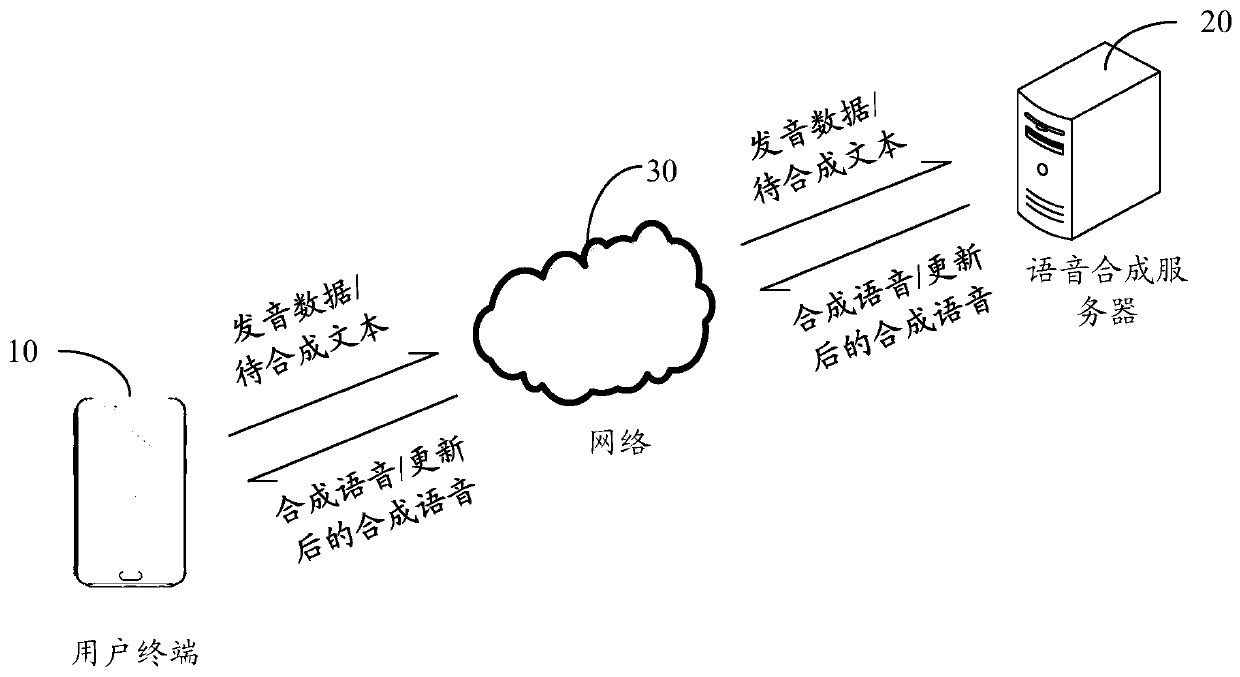
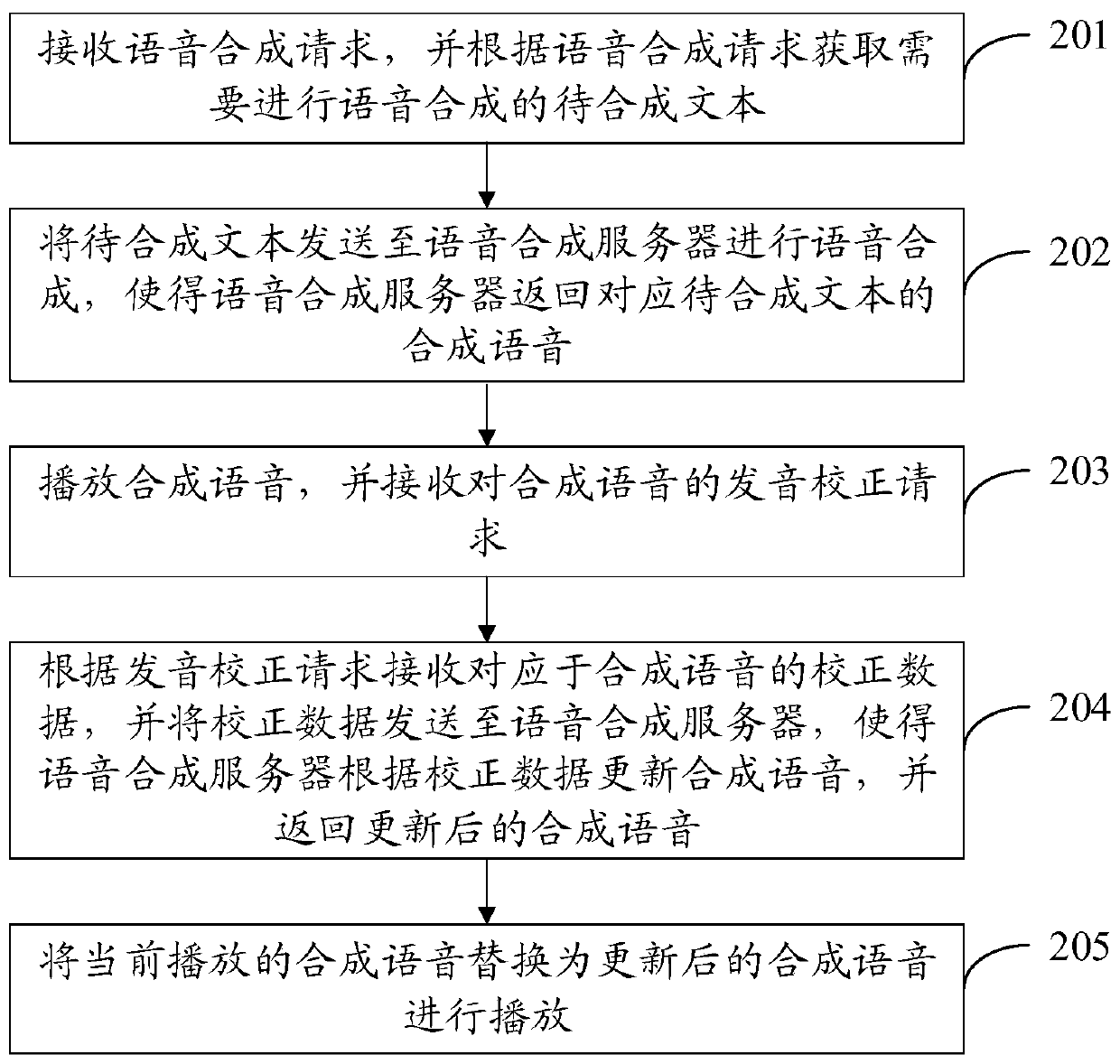
[0086] An embodiment of the present invention provides a speech synthesis playback method, which is suitable for a user terminal, including: receiving a speech synthesis request, and obtaining text to be synthesized that needs to be synthesized according to the speech synthesis request; sending the text to be synthesized to a speech synthesis server for speech Synthesize, so that the speech synthesis server returns the synthesized speech corresponding to the text to be synthesized; play the synthesized speech, and receive the pronunciation correction request for the synthesized speech; receive the correction data corresponding to the synthesized speech according to the pronunciation correction request, and send the correction data to the speech synthesis The server enables the speech synthesis server to update the synthesized speech according to the correction data, and return the updated synthesized speech; replace the currently played synthesized speech with the updated synthe...
Embodiment 2
[0171] An embodiment of the present invention also provides a speech synthesis playback method, which is suitable for a speech synthesis server, including: when receiving text to be synthesized from a user terminal, performing speech synthesis on the text to be synthesized according to a pre-trained speech synthesis model, and obtaining Synthesize voice; return the synthesized voice to the user terminal for playback, and receive the correction data corresponding to the synthesized voice returned by the user terminal; update the synthesized voice according to the correction data to obtain an updated synthesized voice; return the updated synthesized voice to the user terminal , so that the user terminal replaces the synthesized voice with the updated synthesized voice for playback.
[0172] Please refer to image 3 , the flow of the speech synthesis playback method can be as follows:
[0173] 301. When receiving text to be synthesized from a user terminal, perform speech synthe...
Embodiment 3
[0193] According to the methods described in the previous embodiments, examples will be given below for further description.
[0194] Such as Figure 4 As shown, the flow process of the speech synthesis playback method can be as follows:
[0195] 401. The user terminal receives the speech synthesis request, and extracts the text in the display content of the foreground application according to the speech synthesis request, obtains the extracted text, and divides the extracted text into multiple clauses according to the preset sentence segmentation strategy, and sequentially divides the divided text The obtained sentence is set as the text to be synthesized and sent to the speech synthesis server.
[0196] In the embodiment of the present invention, the user terminal may receive an externally input speech synthesis request in real time, thereby triggering speech synthesis, and converting the corresponding text into speech for output.
[0197] After receiving the speech synthe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com