A positioning method for near-character errors in text
A positioning method and a near-word technology, which can be used in text database query, unstructured text data retrieval, electronic digital data processing, etc., and can solve problems such as speed problem, word segmentation result accuracy, text-like near-word error, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
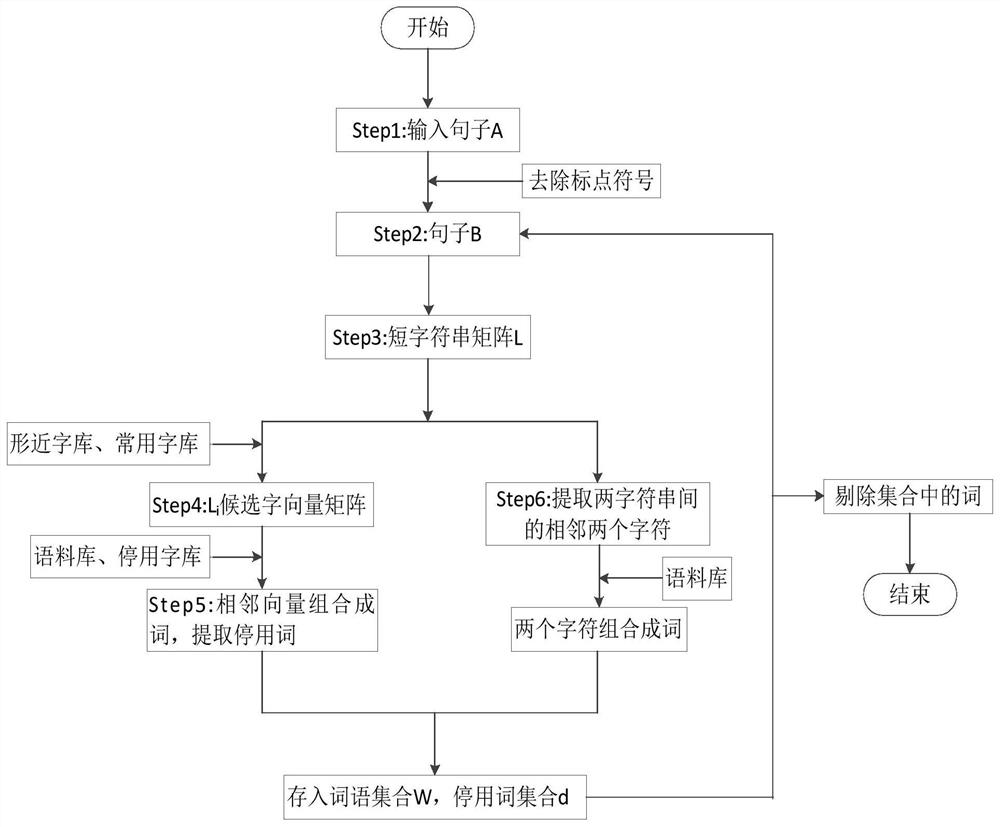
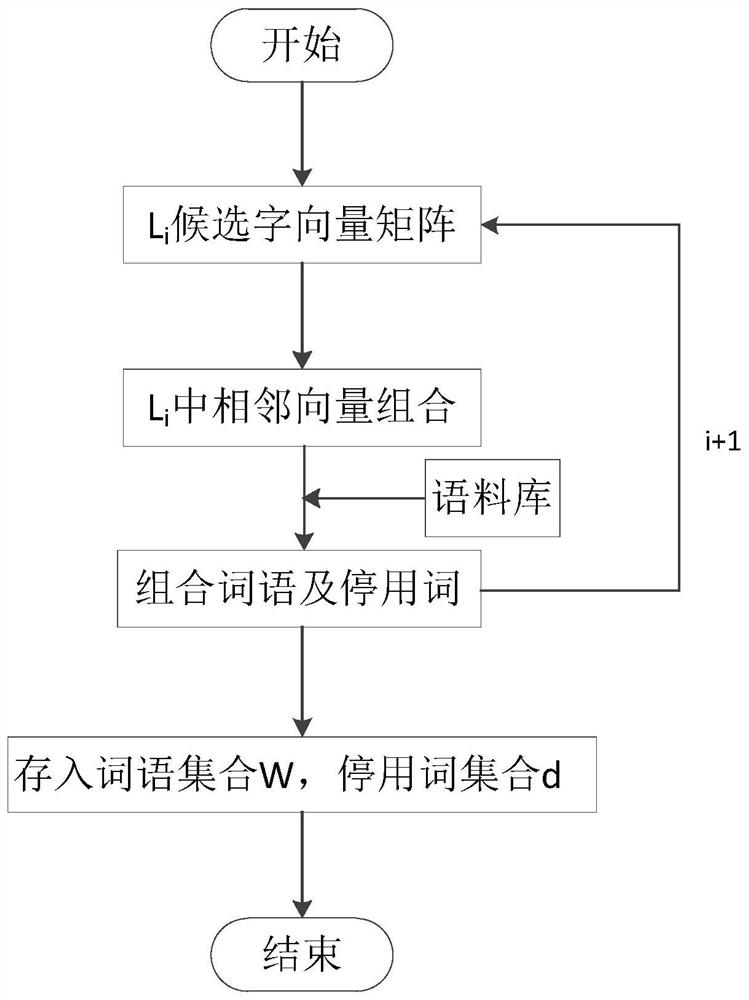
[0022] Embodiment 1: as Figure 1-2 As shown in Fig. 1, a method for locating errors in the form of text, firstly divide the long sentence into n short sentences with a length of m, and then use the Chinese character form library to find the corresponding form of each word in each short sentence Words, and form a candidate word vector with the original character, use the commonly used character library to remove the uncommon words in the vector, and form a candidate matrix with the candidate word vectors of all words, so as to obtain the candidate word matrix of each short sentence; The adjacent vectors in a matrix are bundled into words, and the correct words combined are added to the word set w, and the vectors that cannot be combined into words are extracted and the stop words are added to the stop word set d; Extract the words in the connecting part of a short sentence and combine them. If there are words, add them to the set w; finally, compare the words in the set w and ...
Embodiment 2
[0040] Embodiment 2: a kind of positioning method for text shape near word error, the concrete steps of described method are as follows:
[0041] Step1. Establish a database, which includes font library X, corpus Y, commonly used font library Q, and disabled thesaurus T.
[0042] Step2, select the sample sentence A to be processed, such as 'I can't believe my eyes. ’ The wrong character is sunny (eye).
[0043] Step3. Sentence A is preprocessed, and the punctuation marks in the sentence are removed to obtain a new character string. B='I can't believe my eyes' n=11 is the length of character string B.
[0044] Step4. Divide B='I can't believe my eyes' with length m=5, g={n / m}, (n / m) means the smallest integer not less than this number, then g=3 , then L=[L 1 L 2 L 3 ]=['I can't believe it','Believe in my own eyes','Sunny'],L 1 , L 2 length 5, L 3 has a length of 1.
[0045] Step5, find out L respectively 1 , L 2 , L 3 The candidate word vector matrix, such as L 1 T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com