Speech synthesis method and device and device for speech synthesis
A technology of speech synthesis and synthetic speech, applied in speech synthesis, speech analysis, speech recognition, etc., can solve problems such as synthetic speech noise, achieve the effect of improving hearing and sound quality, improving noise, and improving consistency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
preparation example Construction
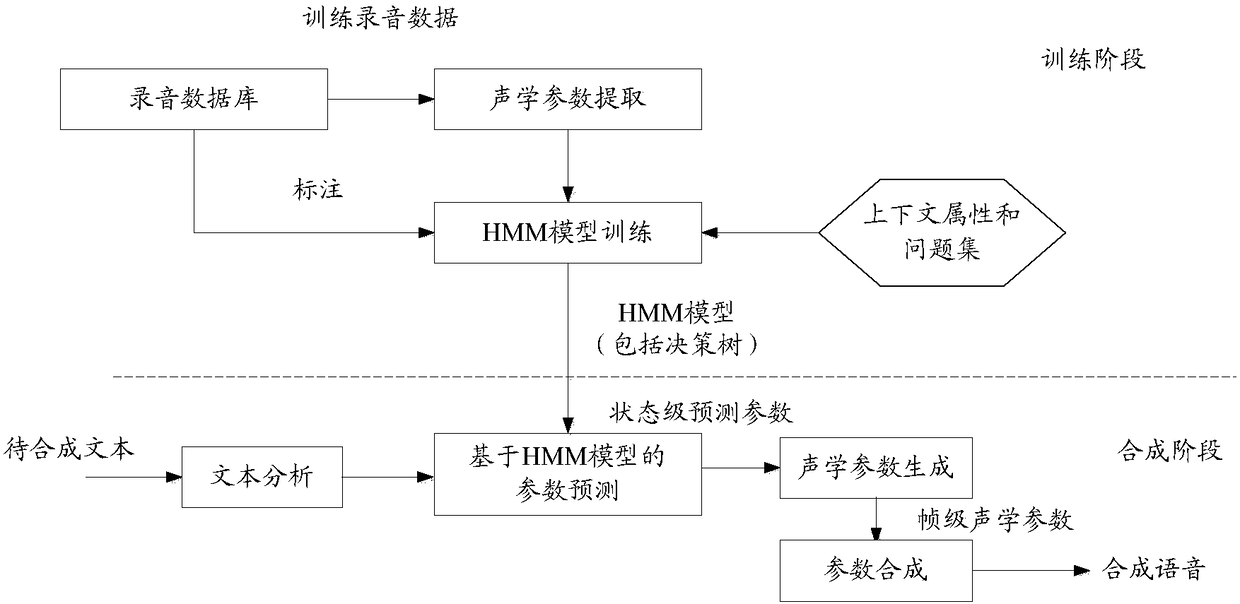
[0074] The embodiment of the present invention can be applied in the speech synthesis process based on HMM, refer to figure 1 , shows a flow chart of an HMM-based speech synthesis method of the present invention, which may specifically include: a training phase and a synthesis phase.
[0075] Wherein, in the training stage, the training recording data can be obtained from the recording database, and the parameters of the training recording data can be extracted to obtain the corresponding acoustic parameters. The acoustic parameters can include: at least one of the spectrum parameters, fundamental frequency parameters and duration parameters One, and, the training recording data can be labeled; optionally, labeling information can be generated based on the training recording data and its corresponding text, and the above labeling information can be used to indicate from which moment to which moment in the training recording data it is What modeling unit, what is the modeling u...
Embodiment 1
[0082] refer to image 3 , which shows a flow chart of the steps of Embodiment 1 of a speech synthesis method of the present invention, the method embodiment may specifically include the following steps:
[0083] Step 301, receiving text to be synthesized;
[0084] Step 302: During the speech synthesis process of the text to be synthesized, judge the corresponding state of the text to be synthesized or the voicing of the frame according to the spectral parameters, so as to obtain the corresponding voicing judgment result;
[0085] Step 303: Obtain the synthesized speech corresponding to the text to be synthesized according to the voicing determination result.
[0086] In the embodiment of the present invention, the text to be synthesized may be used to represent the text that needs to be converted into speech. In practical applications, one can follow the figure 1 In the processing flow of the synthesis stage, the speech synthesis of the text to be synthesized is performed ...
Embodiment 2
[0096] refer to Figure 4 , which shows a flow chart of the steps of Embodiment 1 of a speech synthesis method of the present invention, the method embodiment may specifically include the following steps:
[0097] Step 401, receiving text to be synthesized;
[0098] Step 402, during the speech synthesis process of the text to be synthesized, according to the HMM model, obtain the target spectrum leaf node matching the corresponding state of the text to be synthesized; wherein, the HMM model may include: a decision tree, the The decision tree may include: a spectrum decision tree, and the spectrum decision tree may include: a spectrum leaf node;
[0099] Step 403, according to the voicing probability of the target spectral leaf node, determine the voicing of the corresponding state of the text to be synthesized;
[0100] Step 404: Obtain the synthesized speech corresponding to the to-be-synthesized text according to the voicing determination result.
[0101] compared to im...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com