Deep-learning-based automatic audio annotation method
A deep learning and audio technology, applied in audio data retrieval, audio data indexing, speech analysis, etc., can solve the problems of inability to fully describe audio details, inability to achieve automatic labeling, low accuracy, etc., to improve the efficiency of audio labeling, Improve the effect of labeling accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0042] The present invention will be further described in detail below in conjunction with test examples and specific embodiments. However, it should not be understood that the scope of the above subject matter of the present invention is limited to the following embodiments, and all technologies realized based on the content of the present invention belong to the scope of the present invention.
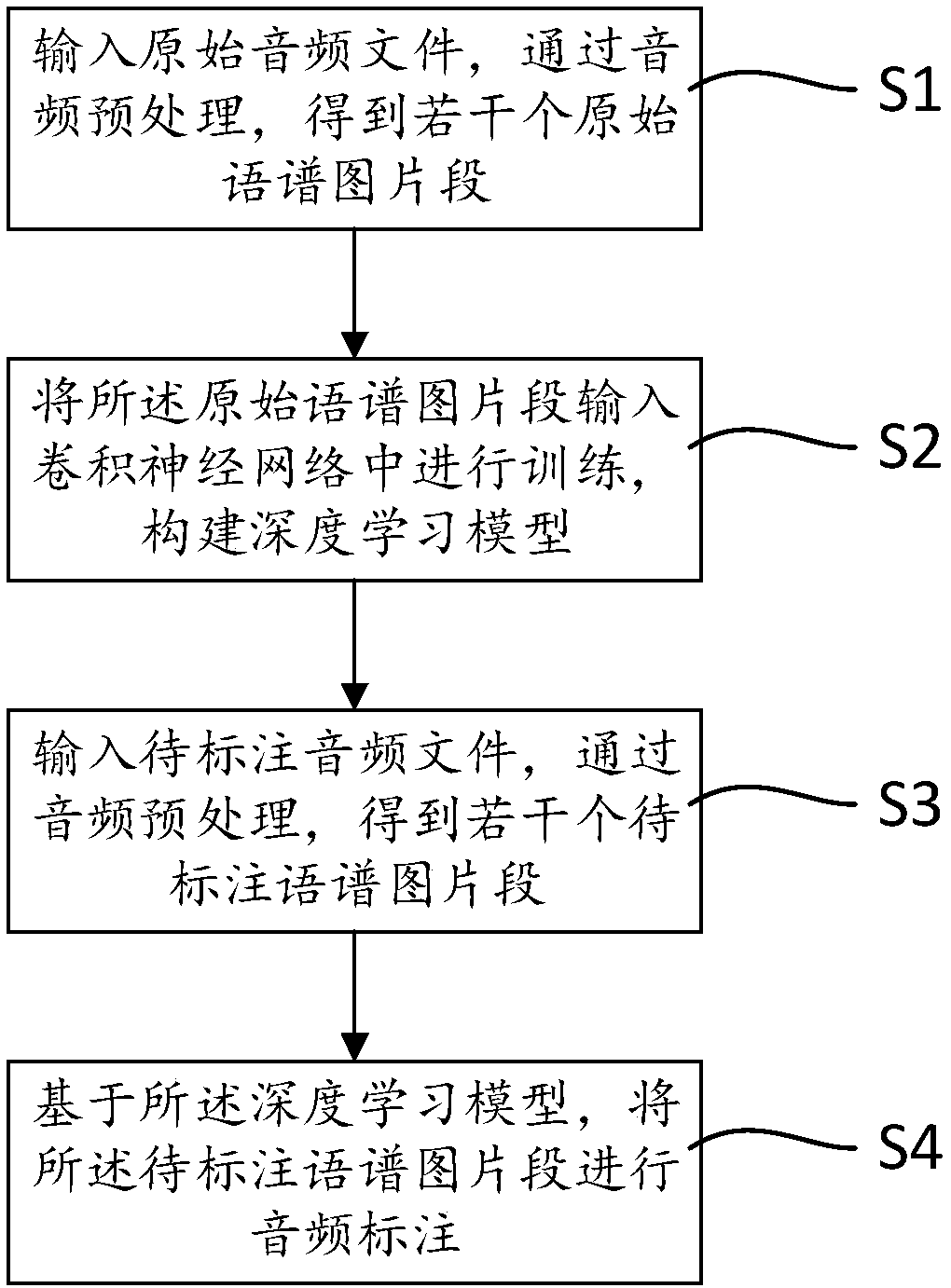
[0043] see figure 1 , an audio automatic labeling method based on deep learning, including the following implementation steps:
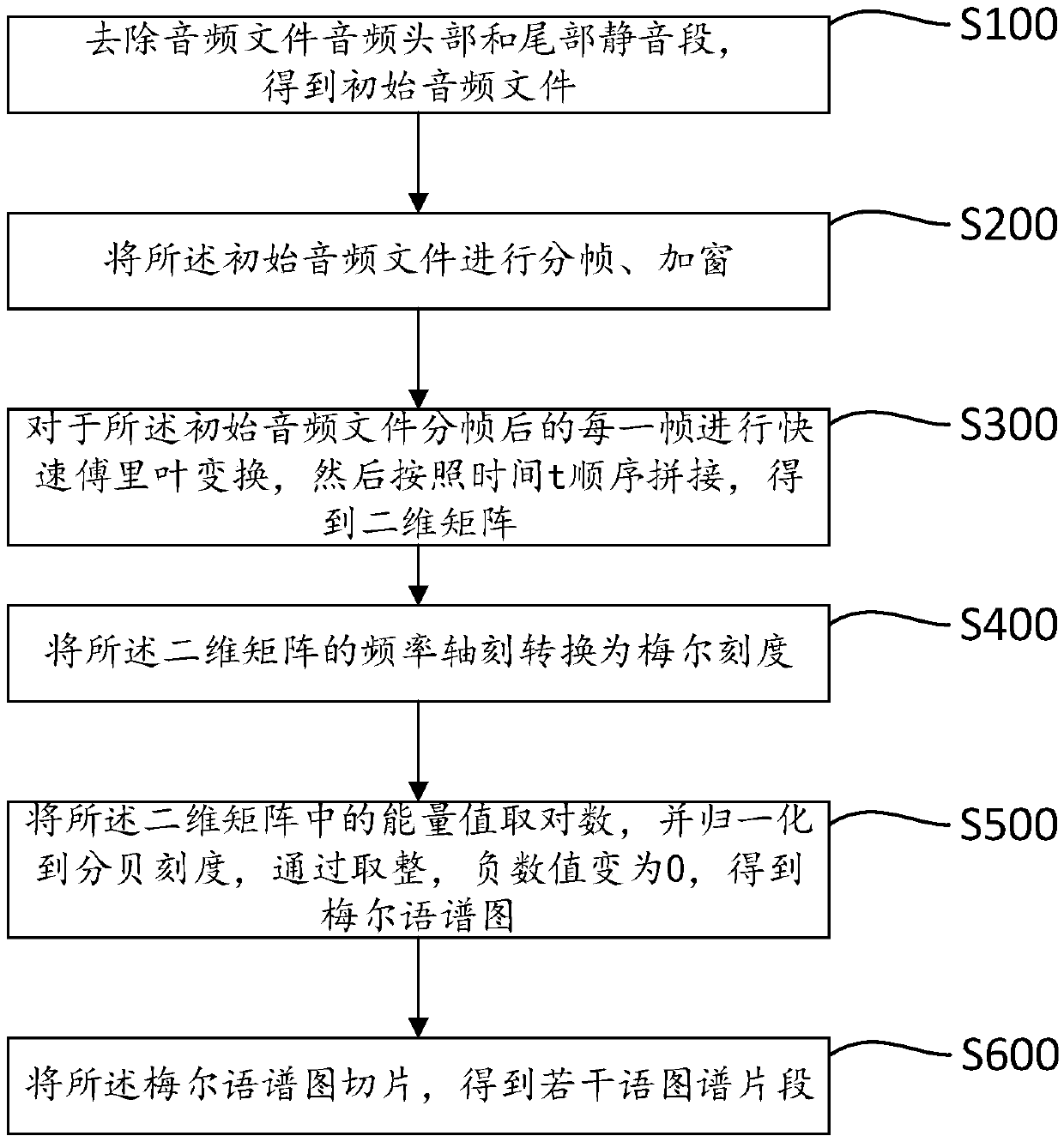
[0044] S1. Input the original audio file, and obtain several original spectral image segments through audio preprocessing;
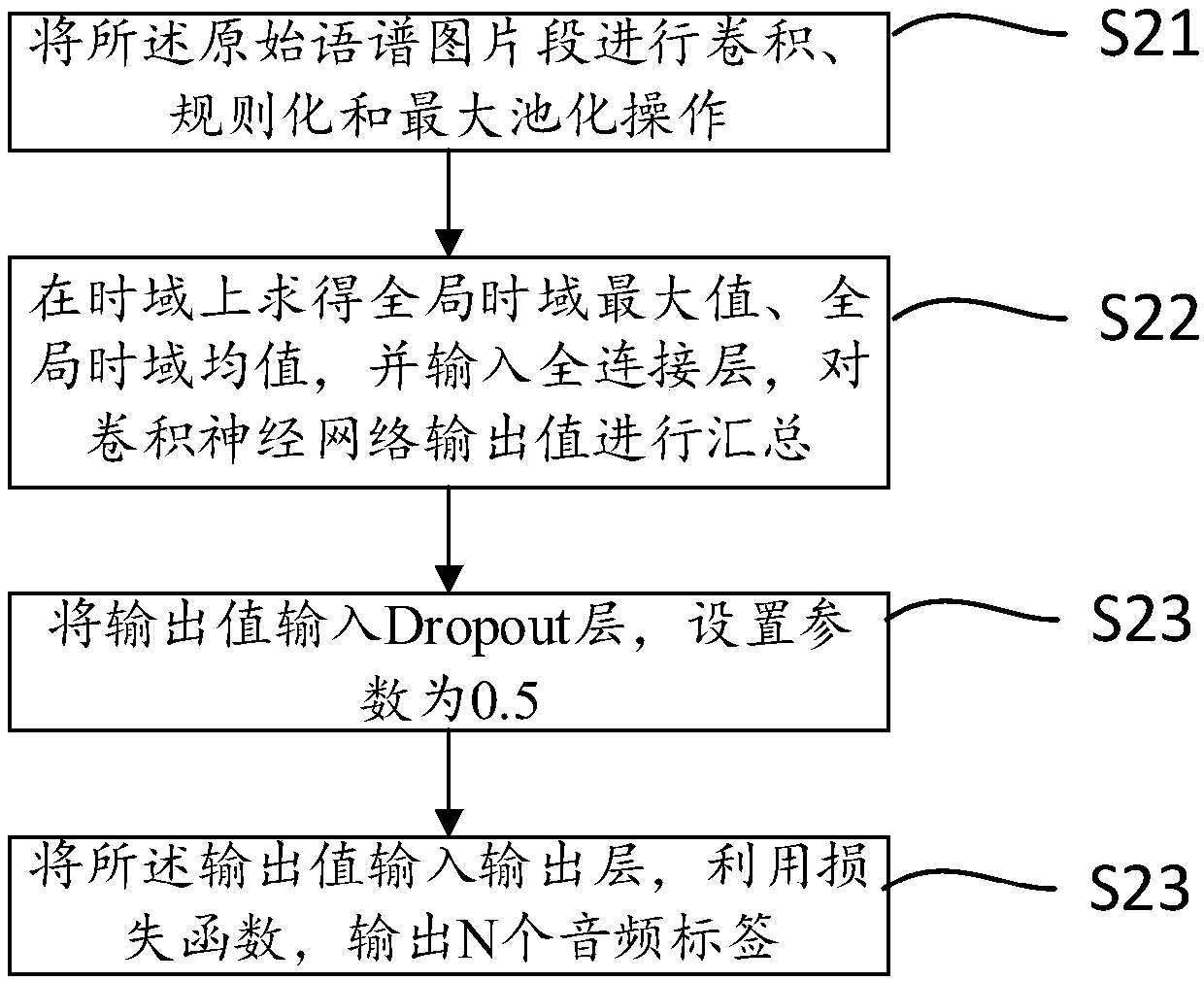
[0045] S2. Input the original spectrum image segment into the convolutional neural network for training to build a deep learning model;
[0046] S3. Input the audio file to be marked, and obtain several spectral image segments to be marked through audio preprocessing;
[0047] S4. Based on the deep learning model, perform audio ann...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com