


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Method and system for synchronizing super large text data to search engine
A text data and search engine technology, applied in the field of big data processing, can solve the problems of ElasticSearch search service engine difficulties, inconsistent forms, server downtime, etc., to avoid inability to edit and check, simplify operation methods, and improve use efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
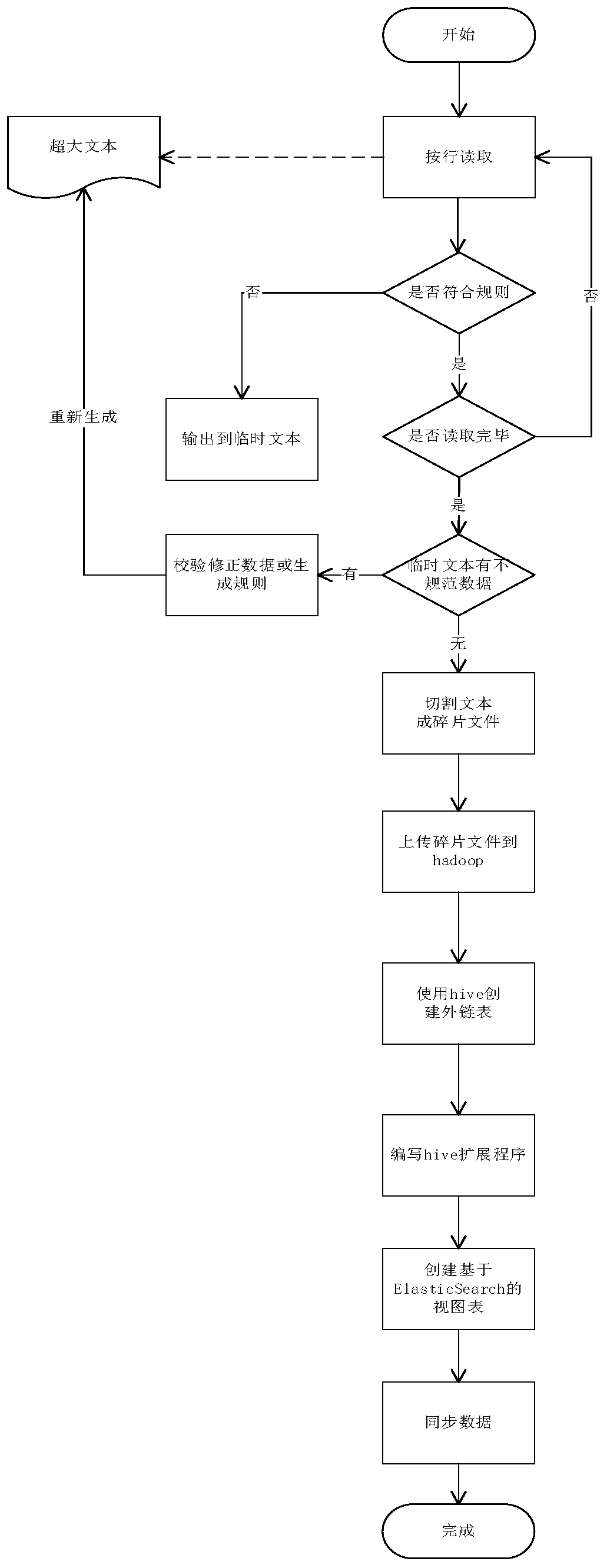
[0049] This embodiment provides a method for synchronizing super-large text data to a search engine, such as figure 1 shown, including:
[0050] Step 1: Normalize the large text data to be synchronized.
[0051] Step 101: Read and verify the super-large text data to be synchronized line by line, and judge whether each line conforms to the rules. If it is judged that there is line data that does not conform to the rules, create a temporary file, and output the line data that does not conform to the rules to the temporary text;
[0052] Step 102: receiving the edit processing of the temporary file by the user, and obtaining row data conforming to the rules;
[0053] Step 103: Verifying the super-large text data line by line, using the edited line data in the temporary text to replace the non-compliant lines in the super-large text data;
[0054] Step 104: Repeat the above steps until all the data conform to the rules;
[0055] The rules are formulated jointly by the data gen...
Embodiment 2
[0069] According to the method described in embodiment one, the present embodiment provides a kind of super large text data synchronously to the system of search engine, comprises ElasticSearch server cluster, computer equipment and Hadoop distributed file system cluster,
[0070] The computer device includes a memory, a processor, and a computer program stored on the memory and operable on the processor. When the processor executes the program, the following steps are implemented: normalizing the super large text data to be synchronized; The normalized super-large text data is line-cut, multiple fragment files are obtained, and the multiple fragment files are uploaded and synchronized to the Hadoop distributed file system cluster in batches;
[0071] The Hadoop distributed file system cluster stores the plurality of fragment files to the external link list of hive, creates a view table corresponding to the data of hive and the open source search engine, synchronizes the data i...
Embodiment 3
[0085] This embodiment provides a Hadoop distributed file system cluster for synchronizing super-large text data,
[0086] Receive the fragmented files of super large text data; store the multiple fragmented files in hive's external linked list, create a view table corresponding to hive and ElasticSearch data, synchronize the data in the external linked list to the view table, and specify in the view table The server node of ElasticSearch to be synchronized to realize the synchronization of super large text data to the search engine.
[0087] The view table also specifies the server node address, port and corresponding index and document of ElasticSearch, and the primary key field in hive is mapped to _id in ElasticSearch.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com