Acoustic model training method and device, computer equipment, and storage medium
An acoustic model and training method technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problem of time-consuming and costly acoustic models, and achieve cost-saving and performance-improving effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0025] figure 1 It is a flowchart of the acoustic model training method provided by Embodiment 1 of the present invention. This embodiment is applicable to the situation where the acoustic model is obtained through training. The method can be executed by an acoustic model training device, which can use software and / or hardware way to achieve. Such as figure 1 As shown, the method specifically includes:
[0026] S101. Acquire supervised speech data and unsupervised speech data, wherein the supervised speech data is speech data with manual annotation, and the unsupervised speech data is speech data with machine annotation.
[0027] Specifically, the supervised speech data may be pre-labeled speech data manually, or pre-purchased manually-labeled speech data, or both. Unsupervised voice data can be obtained from online products on the Internet, for example, from anonymous user traffic such as Baidu search or Baidu input method. These unsupervised voice data have not been manua...
Embodiment 2
[0043] figure 2 It is a flow chart of the acoustic model training method provided by Embodiment 2 of the present invention. Embodiment 2 is further optimized on the basis of Embodiment 1. Such as figure 2 As shown, the method includes:
[0044] S201. Acquire supervised speech data and unsupervised speech data, wherein the supervised speech data is speech data with manual annotation, and the unsupervised speech data is speech data with machine annotation.
[0045] S202. Filter and screen the unsupervised voice data by means of confidence filtering.
[0046] The unsupervised voice data obtained directly from online products on the Internet usually have low-quality data, such as incomplete voice data, voice data with unclear noise, or commonly used voice data with low utilization value, etc. . Confidence filtering means may include, for example, user portraits, text features, or acoustic likelihoods. Through confidence filtering means, relatively high-quality voice data is ...
Embodiment 3
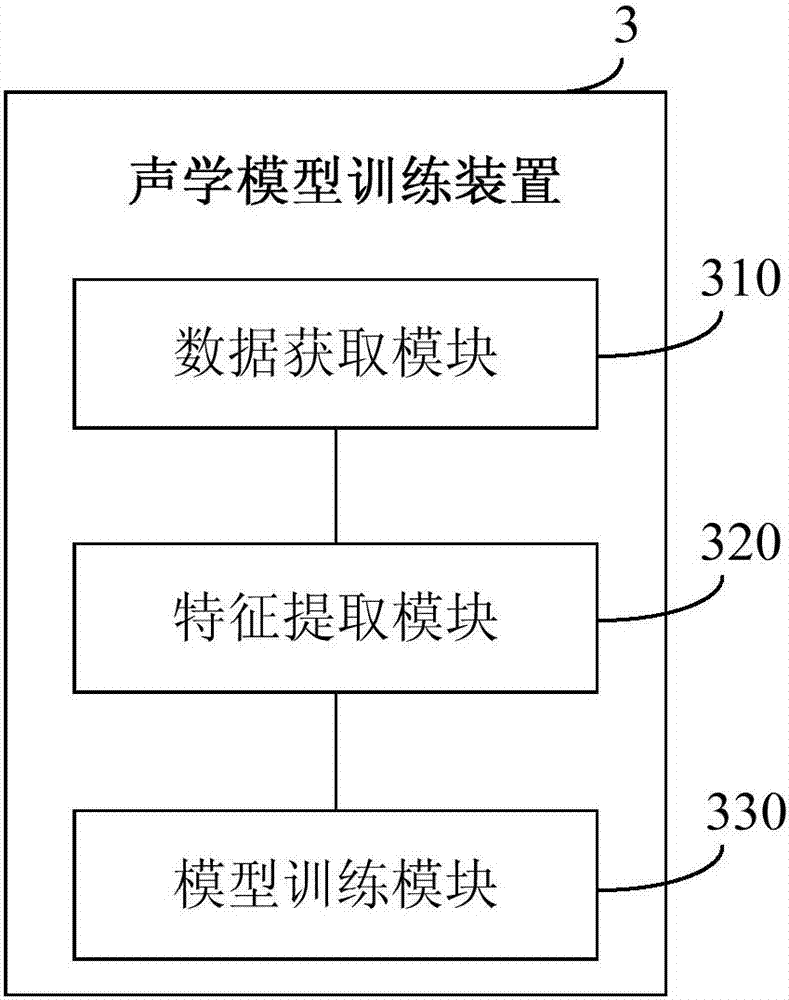
[0052] image 3 It is a structural schematic diagram of the acoustic model training device in Embodiment 3 of the present invention. Such as image 3 As shown, the acoustic model training device 3 includes:
[0053] The data acquisition module 310 is used to obtain supervised voice data and unsupervised voice data, wherein the supervised voice data is voice data with manual annotation, and the unsupervised voice data is voice data with machine annotation;
[0054] A feature extraction module 320, configured to extract voice features from the supervised voice data and unsupervised voice data;
[0055] The model training module 330 is used to use the network structure of deep learning to perform multi-task learning of supervised learning tasks and unsupervised learning tasks on the voice features of the supervised voice data and unsupervised voice data, so as to train and obtain acoustic Model.
[0056] In a preferred embodiment, the network structure of the deep learning in...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com