Improved lexical semantic similarity solution algorithm
A technology of lexical semantics and similarity, applied in the field of semantic network, can solve problems such as errors, complex methods, and large amount of calculations
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

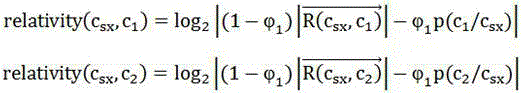
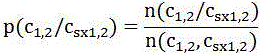
Examples
Embodiment Construction
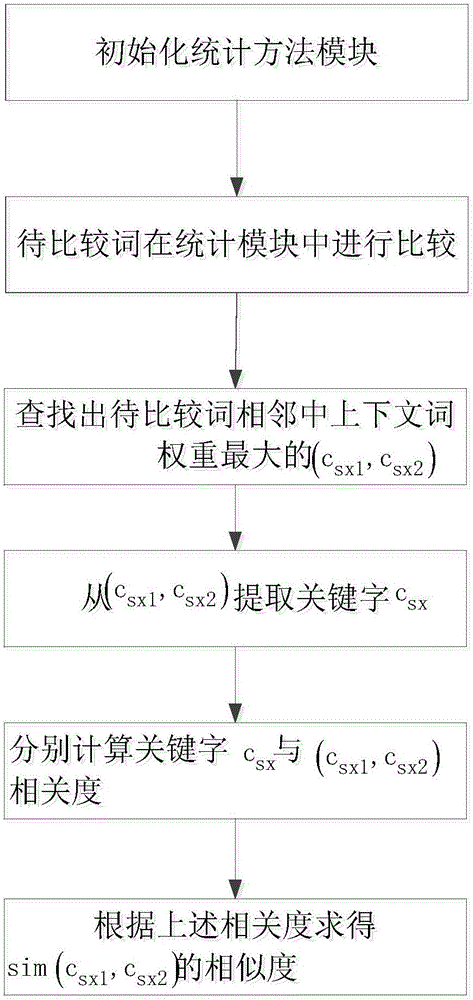
[0016] To solve the word (c 1 , c 2 ) between the semantic similarity problem, combining figure 1 The present invention has been described in detail, and its specific implementation steps are as follows:
[0017] Step 1: Initialize the statistical method module, which can be corpora such as "Word Dictionary", "Ci Lin", "HowNet", "Baidu Encyclopedia" and so on.
[0018] Step 2: the word to be compared (c 1 , c 2 ) into the initial statistical method module.
[0019] Step 3: Find the words to be compared in the statistics module (c 1 , c 2 ) the context word with the greatest weight in the adjacent context (c sx1 ,c sx2 ).
[0020] Find the word to be compared (c 1 , c 2 ) corresponding to the context word with the largest weight in the corpus (c sx1 ,c sx2 ), the specific calculation process is as follows:
[0021] Context words are searched according to constraints. For example, in Chinese, part-of-speech pairs with relatively strong context constraints include: ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com