Matrix multiplication acceleration method for general multi-core dsp
A matrix multiplication and matrix technology, applied in the field of matrix multiplication acceleration oriented to general multi-core DSP structure, can solve problems such as difficult to meet processor DSP
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

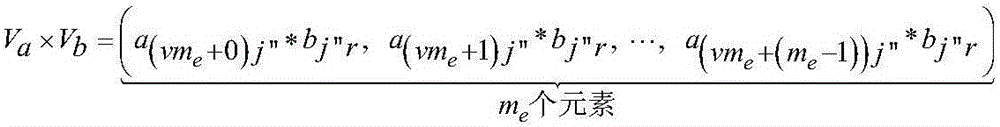
Examples
Embodiment Construction
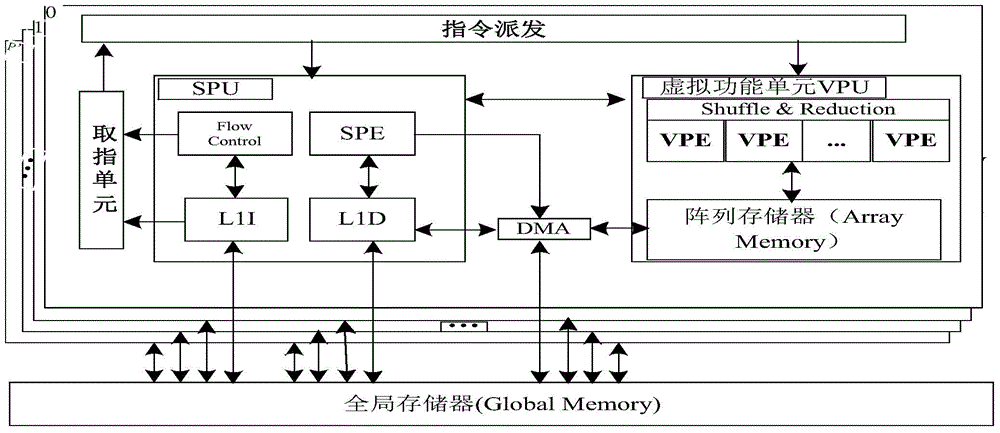
[0118] figure 1 It is a general multi-core DSP architecture;
[0119] in figure 1 Among them, each single-core DSP is composed of SPU and VPU. The SPU is composed of L1I (Level 1 Instruction) Cache, L1D (Level 1 Data) Cache, SPE (Special Processing Unit), scalar register and flow controller. L1I is used for instruction cache; L1D is used for data caching; SPE is used for some instruction flow control, configuration of vector units and main communication tasks; VPU includes AM (Array Memory), vector registers and multiple concurrently executable VPE (Virtual Processing Unit), AM is mainly used for array buffering, and the vector SIMD unit composed of multiple VPEs is mainly used for numerical operation acceleration.
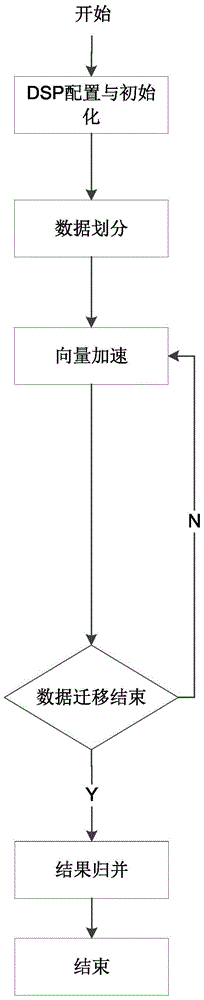
[0120] figure 2 It is the overall flow chart of the matrix multiplication acceleration method for general multi-core DSP of the present invention
[0121] The steps of the present invention are as follows:
[0122] The first step is DSP configuration and initialization...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com