A data query processing method
A processing method and data query technology, applied in the field of data query statistics, can solve the problems of consuming system resources and long data processing time, and achieve the effect of saving computing resources and avoiding long waiting
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
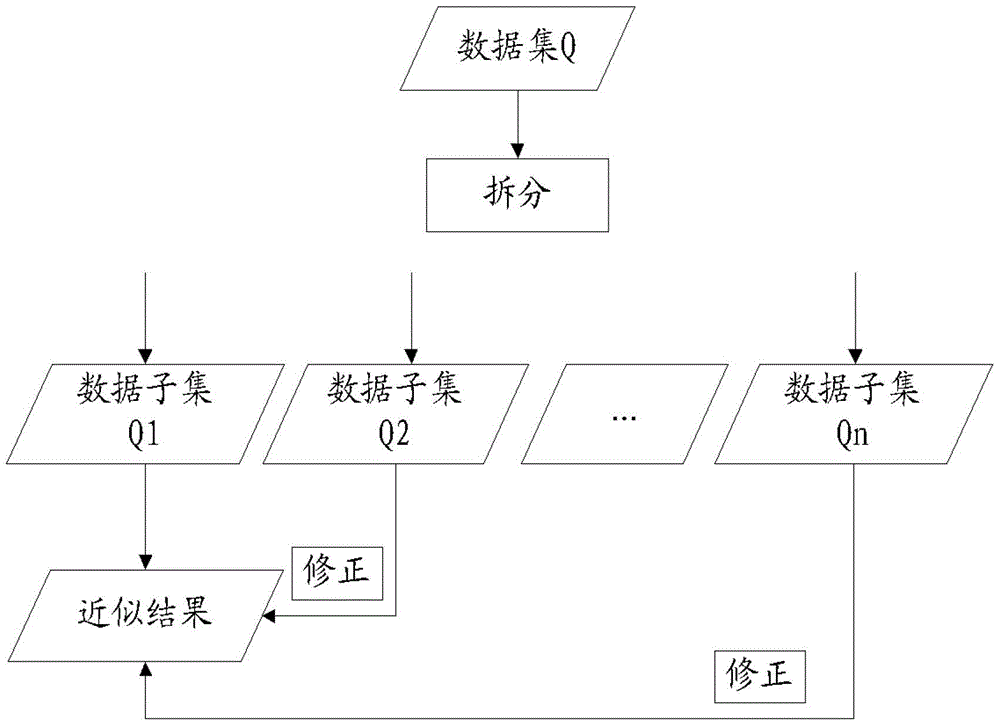
[0069] The scenario is to count the consumption data of all customers of a large e-commerce website. The website has more than ten million customer data and one billion consumption records. When it is necessary to count data such as the total consumption of customers within a certain period of time, partial statistics can be used to continuously revise the statistical results.
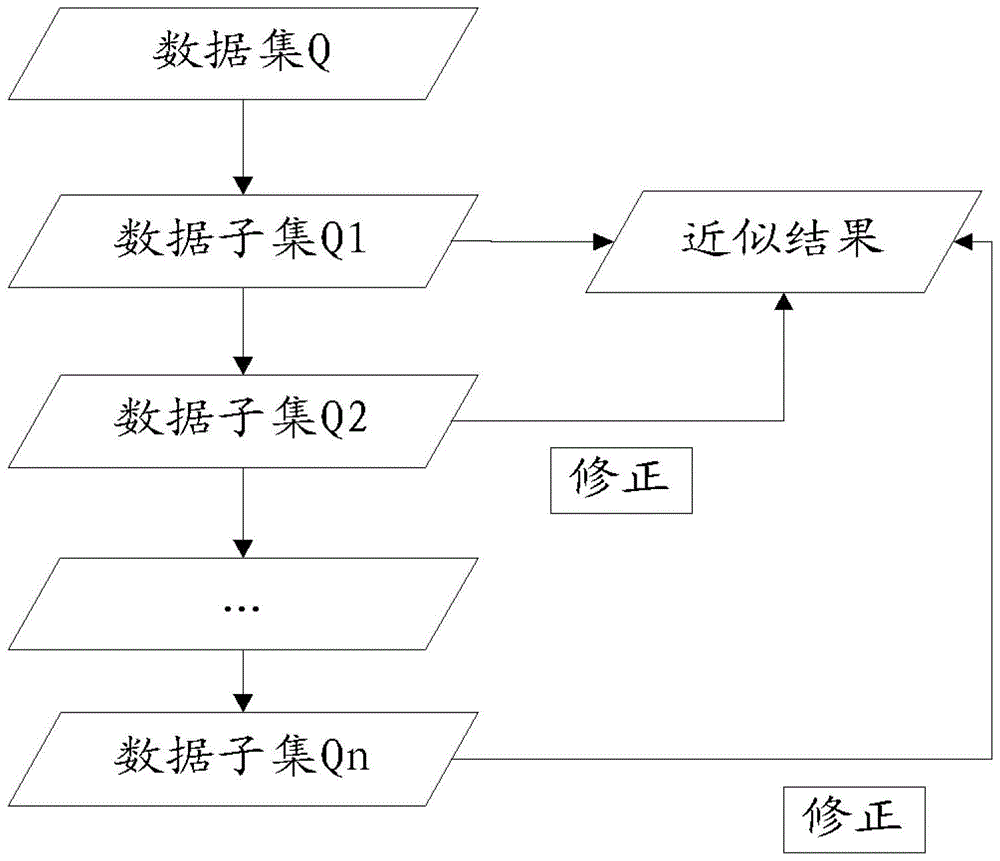
[0070] First, the consumption records are split according to the size of the data volume. After the statistics of the first data subset are completed, the data of the total consumption of some of the customers that have been counted (that is, the data in the first data subset) can be obtained; After the second data subset is processed, the results of the total consumption of the customers of the first two data subsets can be obtained. In this way, each data subset is processed one by one, and the statistical results are continuously revised until all data processing is completed, and the final statist...
Embodiment 2
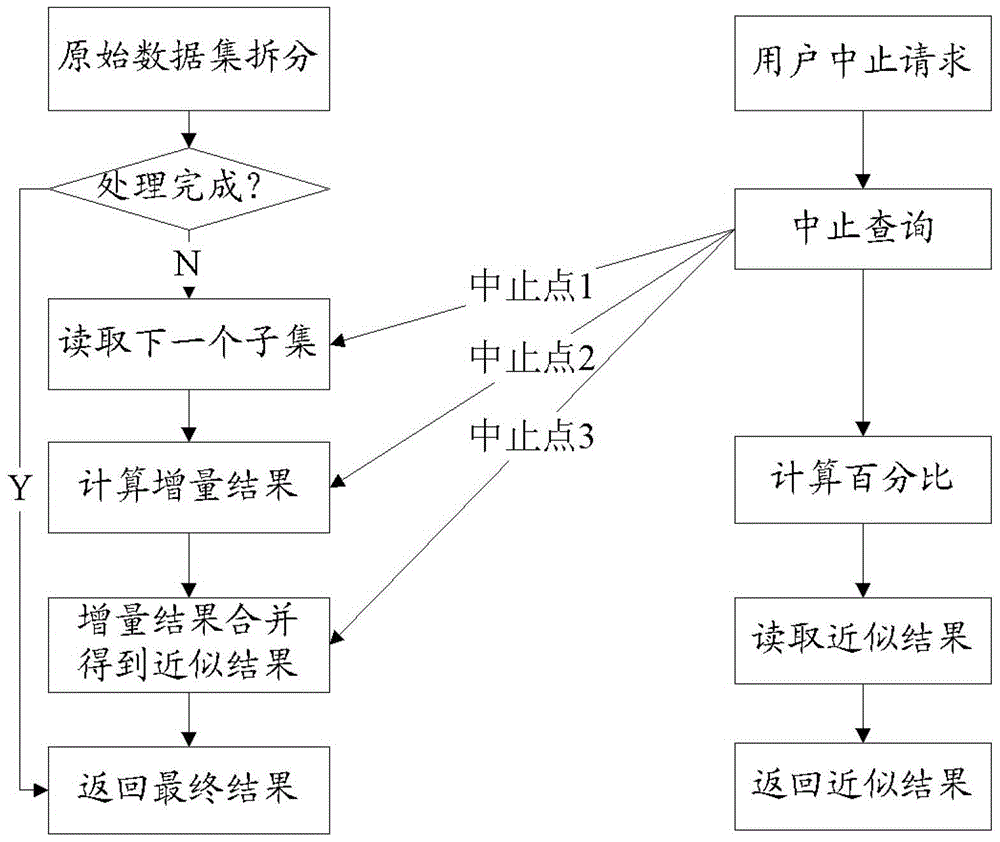
[0073] The scenario is to count the average monthly call time of users of a mobile communication operator in a certain year. First, all the call records of the operator in the current year are divided into 12 data subsets in units of months. The query process is as follows: After the system queries the call records in January (the first data subset), suppose 1 Monthly average user talk time R 1 is 300 minutes, then the approximate monthly average call time of users is T 1 is 300 minutes, and the query progress percentage is 1 / 12*100%=8.3%; the system continues to query, after querying the call records in February (the second data subset), it is assumed that the average call duration R2 of users in February is 460 minutes, then the approximate monthly average call time of users is T 2 =T 1 +Δ2=T 1 +(R 2 -T 1 ) / 2=300 minutes+(460 minutes-300 minutes) / 2=380 minutes, the query progress percentage is 2 / 12*100%=16.7%; ) call records, assuming that the average call duration R3...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com