Method and system for processing text based on DNA sequences
A DNA sequence and text processing technology, applied in the field of DNA sequence-based text processing methods and systems, can solve the problems of single functional tasks, inability to communicate with each other, and low execution efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
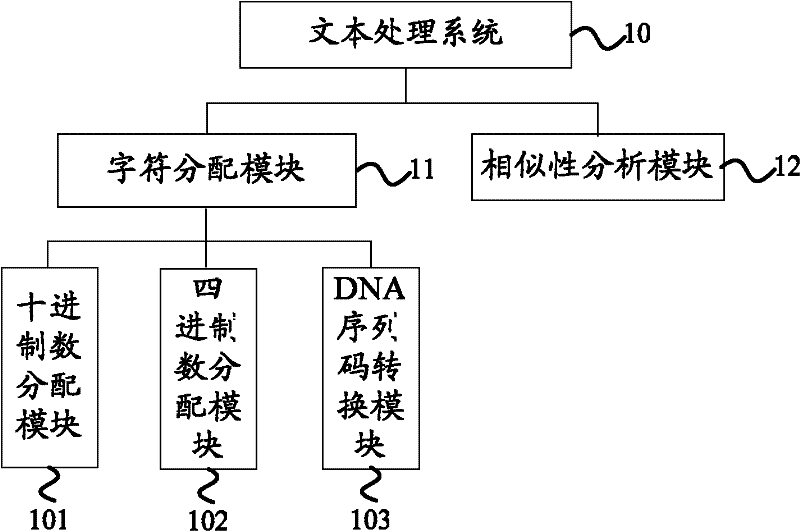
[0044] The technical solutions of the embodiments of the present invention will be further described below in conjunction with the accompanying drawings and specific embodiments. Example 1: Using figure 1 The character distribution module 11 in the shown text processing system 10 converts the characters in the text into DNA sequences according to the method of the present invention
[0045] Select a text containing about 7000 different characters, and contain a section of characters "Chinese Text Mining" in the text. According to the method of the present invention, it can be known that to represent all the characters in the text, the position of the quaternary number is required. The number is 7 digits; now take this section of characters in the text——"Chinese text mining" as an example, describe the process of converting the characters of this embodiment into DNA sequences in detail:
[0046] First use the decimal number allocation module 101 to distribute the decimal numbe...
Embodiment 2
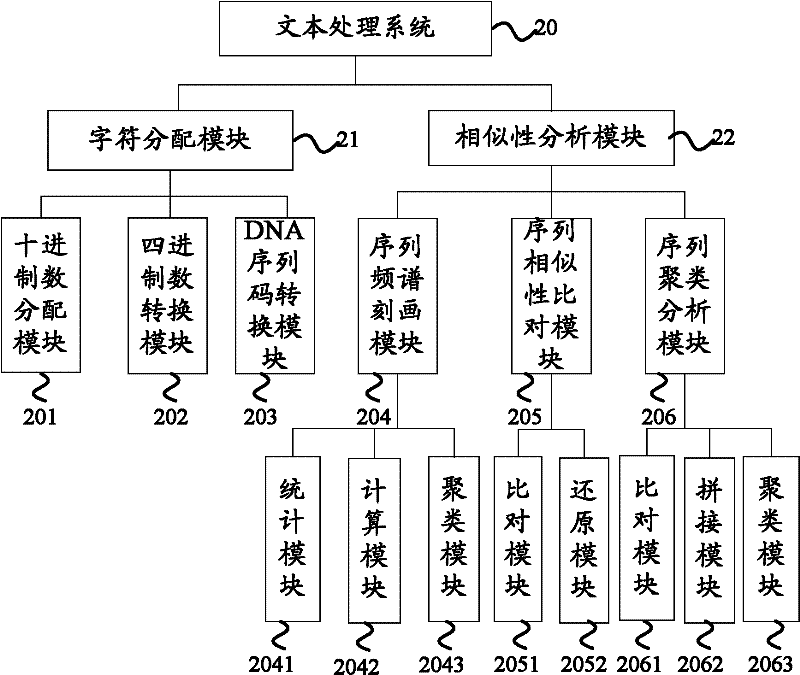
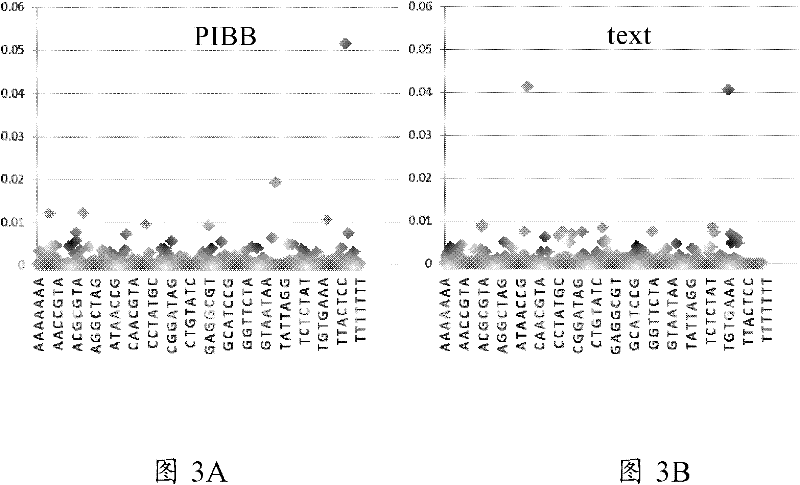
[0051] Example 2: Using figure 2 The shown text processing system 20 carries out spectral description to two or more texts according to the method of the present invention
[0052] Selected 20 texts recently published in the journal "Progress in Biochemistry and Biophysics" shown in Table 1 (referred to as 20 texts of PIBB) and shown in Table 2 with the keyword - "text mining" from CNKI ( The 20 texts selected by searching in the CNKI) text database (20 texts for short) are used as clustering objects:
[0053] Table 1
[0054]
[0055]
[0056] Table 2
[0057]
[0058] According to the method of embodiment 1, the total number of different characters in the 40 texts is first counted, which is 3243, and then the characters in the 20 texts of the PIBB are divided into characters according to the characters in the 20 texts of the PIBB using the decimal number distribution module 201 in the character distribution module 21. The decimal numbers are assigned in the order ...
Embodiment 3
[0081] Example 3: Using figure 2 The shown text processing system 20 performs sequence similarity comparison on two texts according to the method of the present invention
[0082] Randomly select two texts from the 40 texts in Example 2 above for sequence similarity comparison. The two selected texts are: "Application Research of Text Mining in Multicultural Communication Platform" (text_01) and "Protein Interaction "Research Progress in Text Mining of Function" (text_02), now take any two texts in text_01 and text_02 as an example to describe the sequence similarity comparison process in this embodiment in detail, and name a text from text_01 as "query text (Query.txt)", a piece of text from text_02 is named "Target Text (Subject.txt)"
[0083] The query text (Query.txt) is:
[0084] "Text mining based on concept lattice, text mining is to discover potential concepts and the relationship between concepts from unstructured texts. As an effective technology for discovering p...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com