Method for calculating similarity of XML documents
A document similarity and similarity technology, applied in the database field, can solve problems such as high time complexity, loss of infrequent paths, loss of structural information, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0055] Embodiment 1: The specific method of constructing the BPC model based on the XML document tree is described as follows:
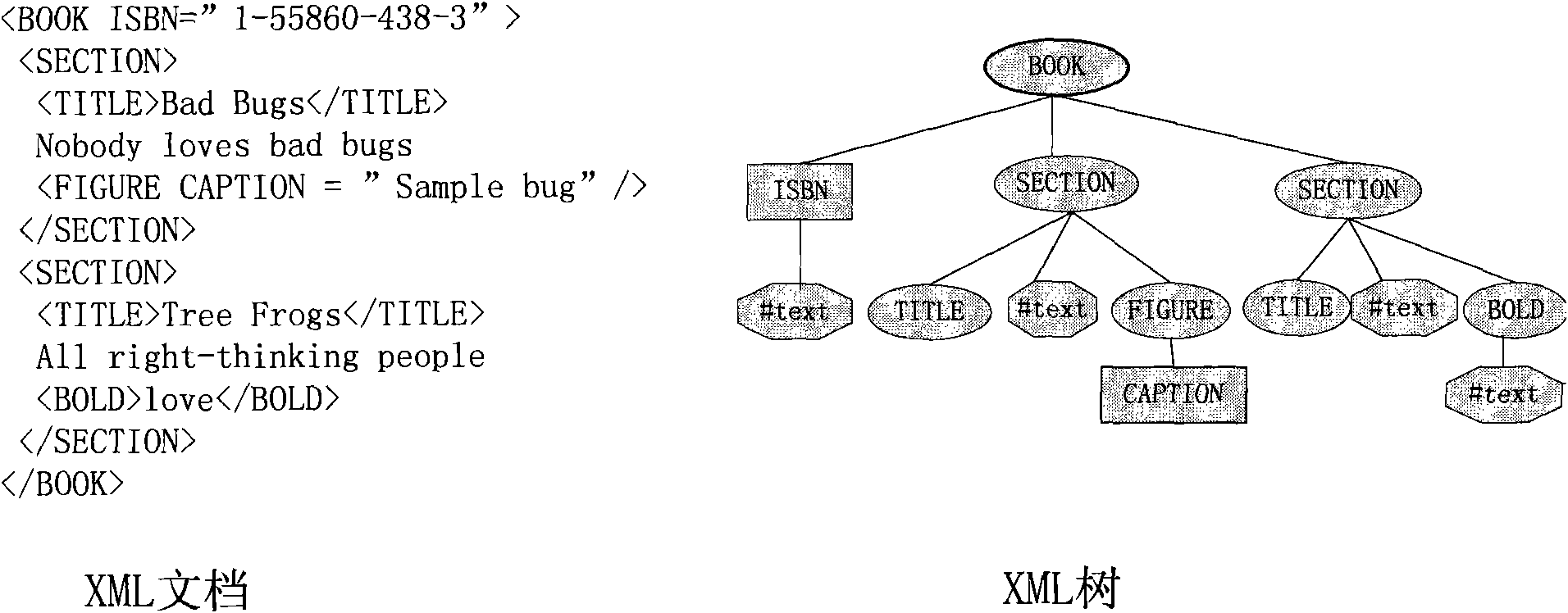
[0056] 1. According to the present invention, an XML document is defined as an XML document tree, and a BPC model is established for each node on the basis of the document tree. figure 1 shows an XML document and its corresponding XML document tree, Table 1 starts with figure 1 Take the document tree as an example to list the BPC models of each node.
Embodiment 2
[0057] Embodiment 2: A specific method for calculating document similarity based on the N-Gram idea is described as follows:
[0058] Algorithm 1. The method CreateGram that generates i+1-Gram items based on two adjacent i-Gram items
[0059] input: item 1 , item 2 / *Two adjacent i-Gram items represented by positive integers* /
[0060] t / *radix t* /
[0061] Output: item / *(i+1)-Gram item represented by a positive integer* /
[0062] ①.item:=item 1 ×t+item 2 %t;
[0063] ②. RETURN item;
[0064] ③. Algorithm ends
[0065] The algorithm generates (i+1)-Gram items based on two adjacent i-Gram items. The base t in the algorithm is the total number of different labels in the two path constraints to be compared plus 1. For the same path constraint, the base t is introduced. When i≠j, it can be guaranteed that the integer field where the i-Gram item is located and the integer field where the j-Gram item is located have no intersection.
[0066] Algorithm 2. The...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com