


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Fusion method based on end-to-end speech recognition model and language model
A technology of speech recognition model and language model, which is applied in speech recognition, speech analysis, instruments, etc., can solve the problem that the algorithm is not self-adaptive, and achieve the effect of improving the effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
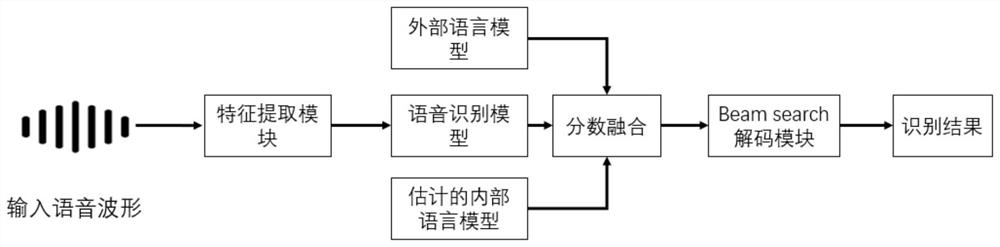
[0027] like figure 1 , figure 2 , image 3 A fusion method based on an end-to-end speech recognition model and a language model is shown, and the selected speech recognition model used in this implementation consists of a Conformer encoder, an additive attention mechanism, and an LSTM decoder. Among them, the Conformer encoder consists of 12 layers, each layer has a width of 512 dimensions, and the number of self-attention mechanisms of the encoder is eight. Use random dropout during training to prevent the model from overfitting. The decoder is composed of a two-layer long short-term memory network, and the width of each layer is 2048. The language model uses the RNN language model, which consists of a three-layer LSTM network. The width of the hidden layer of the LSTM network is 2048 dimensions. During the training process, random discard is used to prevent the model from overfitting. In this example, the Chinese general data set is used to train the speech recognition ...
Embodiment 2
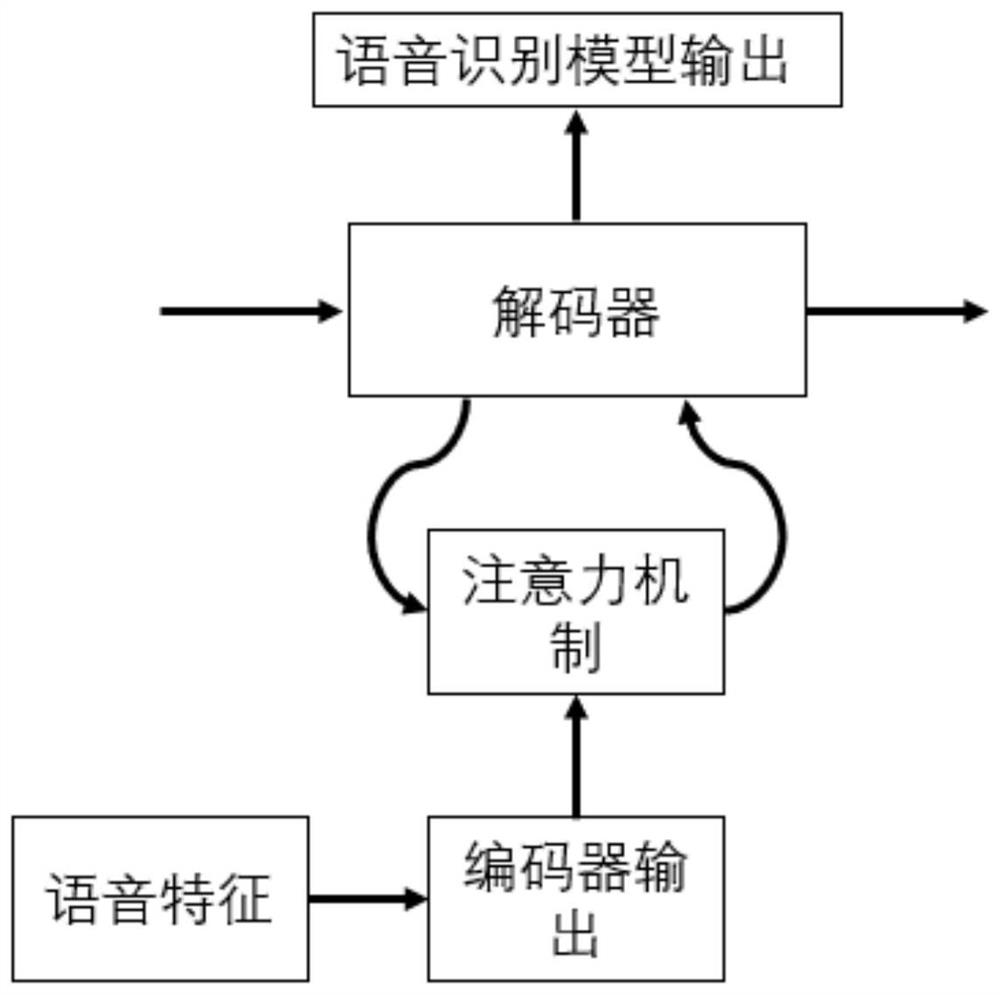
[0055] The training end-to-end speech recognition model used in this implementation can be expressed as the following structure. The speech to be recognized is extracted into a feature sequence and then input into the encoder of the speech recognition model. After being encoded by the encoder, it is output to the attention mechanism module and saved for use. . The decoder uses an autoregressive method and an integrated attention mechanism to calculate the prediction output at the current moment. The specific formula is as follows:
[0056] H=Conformer(X)
[0057]
[0058] q i =FNN 1 (s i )
[0059] c i =Attention(H,q i )
[0060]
[0061] Among them, X=[x 1 ,x 2 ,…,x t ,…,x T ] is the audio feature sequence to be identified, where x t represents the audio feature of the t-th frame, and X∈R T×d , T is the audio sequence length, d is the feature dimension; H=[h 1 ,h 2 ,…,h t ,…,h T ] is the output encoded by the encoder, h t is the encoded output correspo...
Embodiment 3
[0067] This implements a fusion method based on an end-to-end speech recognition model and a language model, including the following steps:
[0068] S1. Use speech and text pairs to train an end-to-end speech recognition model, and use text data to train an external language model; the end-to-end speech recognition model includes an encoder, a decoder, and an attention mechanism, and the decoder uses an attention mechanism Obtain the acoustic information processed by the encoder;
[0069] The encoder is a Conformer encoder, a BLSTM encoder or a Transformer encoder;
[0070] The decoder is an LSTM decoder or a Transformer decoder;
[0071] The attention mechanism is an additive attention mechanism, a position-sensitive attention mechanism, or a monotonic attention mechanism. The end-to-end speech recognition model can also be formed by combining the above modules.
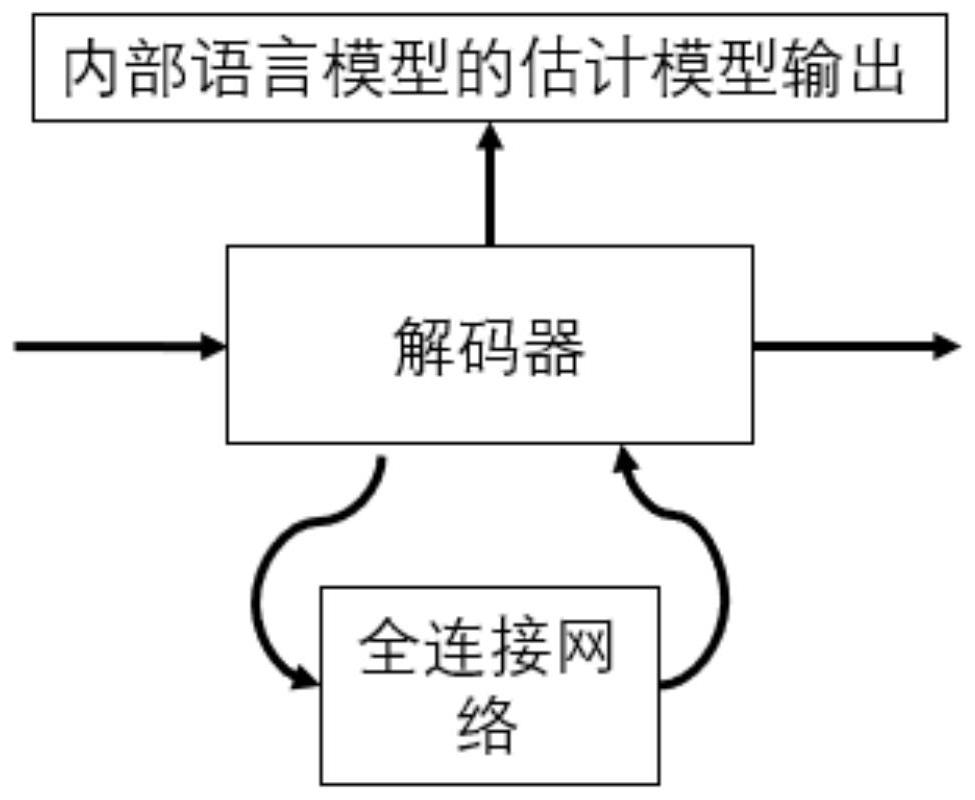
[0072] S2. Take out the decoder of the trained end-to-end speech recognition model separately, and replace the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com