Data classification method based on deep learning and graph establishment method
A technology of data classification and deep learning, applied in the field of article data classification of deep learning, can solve problems such as low efficiency, achieve the effect of reducing the amount of calculation and releasing storage space
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

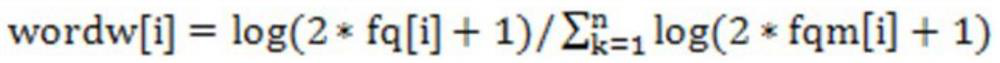
Examples
Embodiment 1
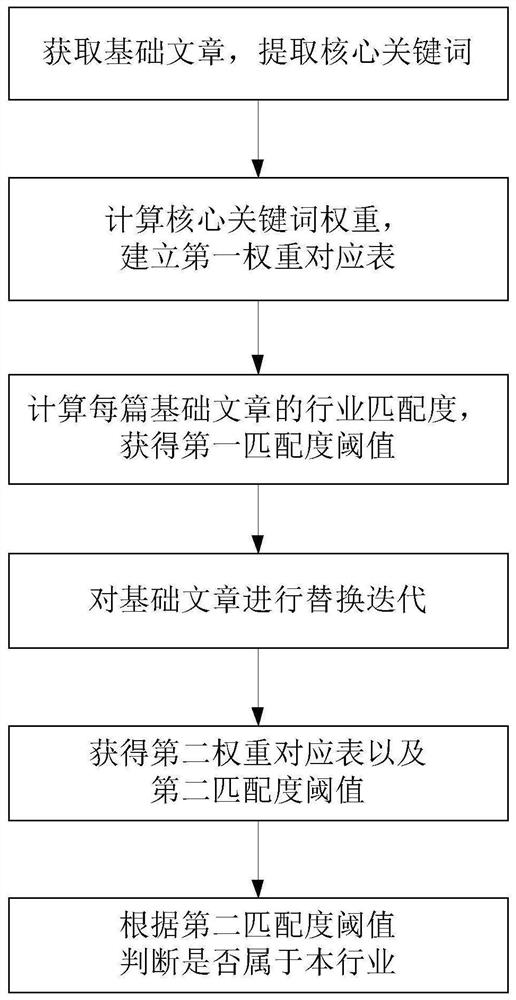
[0036] This application provides a data classification method based on deep learning. First, articles are randomly selected for model building, and then other articles are used to make the model self-learn, and the final article classification model is obtained through iteration, and the final article classification model is used for industry Judgment of the article. Specifically include the following steps:
[0037] Use crawler technology to collect data, use ElasTic Search cluster storage, and use Hanlp tokenizer for full-text retrieval. You can obtain several basic articles in the same industry from the data of industry websites, and use TextRank algorithm to extract several core keywords from several basic articles. word, calculate the weight value of the core keyword, and establish a first weight correspondence table according to the core keyword and the weight value.
[0038] Taking the forestry industry as an example, we selected 5,000 articles from China Forestry Info...
Embodiment 2
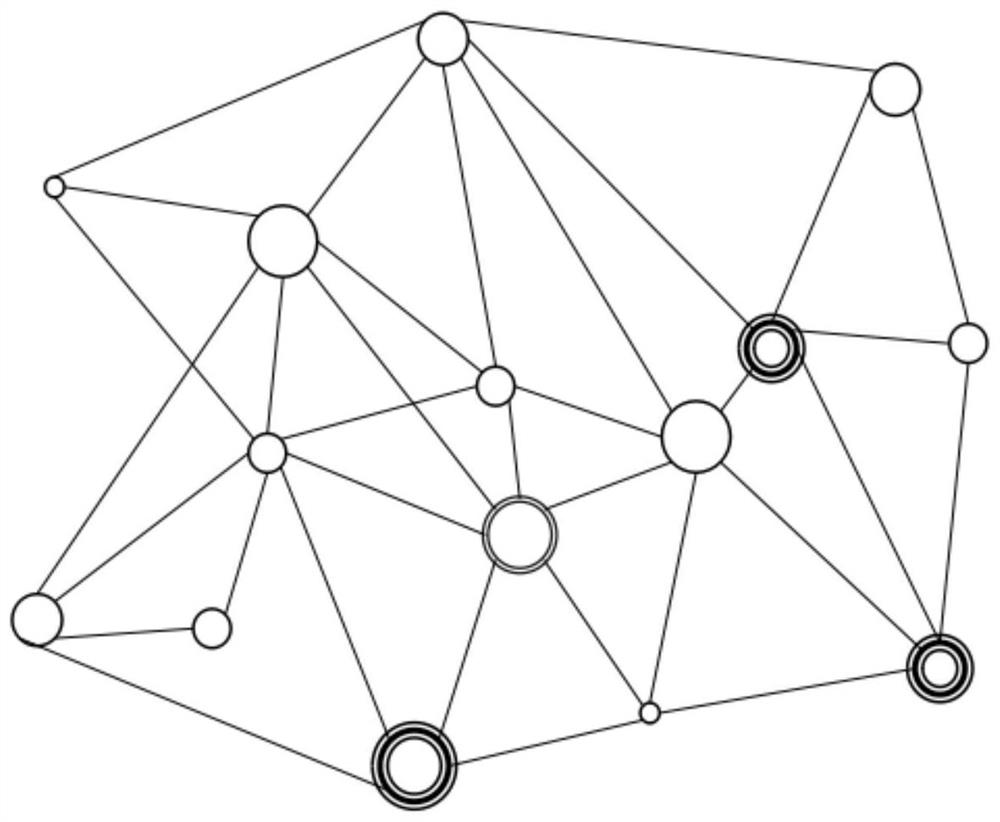
[0067] This embodiment provides a method for establishing a map, specifically a method for establishing a knowledge map of a target industry, using the article classification method in Example 1 to obtain article data of a certain industry, and build a knowledge map of the target industry based on the article data. Specifically include the following steps:
[0068] Article sampling is carried out according to the keyword correlation, sampled articles are obtained, several keywords in the sampled articles are extracted, and derivative words of keywords are obtained through mutual information entropy calculation, weight values of all keywords and derivative words are calculated, and Keywords and derived words are sorted according to weight value, and a topological relationship is established between keywords and derived words to form a network structure graph, thereby obtaining an industry knowledge map.
[0069] The method of calculating the weight value is as follows:
[00...
Embodiment 3
[0081] This embodiment provides an article classification device, including a memory and a processor, wherein the memory is used to store a data processing program, and when the data processing program is read and executed by the processor, it executes the method based on deep learning in Embodiment 1 of the right data classification method.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com