


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
A video positioning method and device, model training method and device
A video positioning and video technology, applied in video data query, video data retrieval, metadata video data retrieval, etc., can solve the problems of high computing requirements, time-consuming and labor-intensive, human-subjective deviation of labeling information, etc., and achieve good universality Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
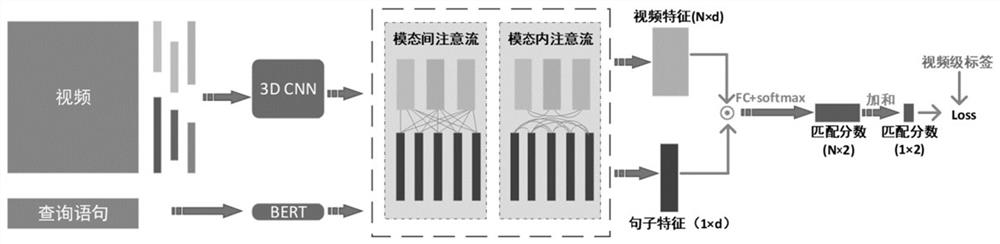
[0076] This embodiment proposes a video positioning method. figure 1 It is a flow chart of a video positioning method provided by the embodiment of the present invention. like figure 1 As shown, the method includes S10-S70.
[0077] S10: Use a multi-scale time sliding window to divide the segment to obtain a plurality of video clips, where there is an overlap between the setting ratio between adjacent video clips.
[0078] Alternatively, a multi-scale time sliding window is used in the division of the video clip, and the length of the time sliding window is [64, 128, 256, 512] frame; and the adjacent video clip maintains an overlap of 80%. Take the sliding window with a size of 64 frames as an example. The first video clip starts from the first frame to the 64th frame, and the second video clip starts from 12.8 frames to 75.8 frames to end, in this type. This ensures that the overlap between adjacent video clips reaches 80%. It should be noted that the frame is taken upward when t...
Embodiment 2
[0137] This embodiment provides a model training method for training the video positioning model constituting the video positioning method described in the first example. figure 2 It is a flow chart of a model training method according to an embodiment of the present invention. like figure 2 As shown, the method includes S01-S03.
[0138] S01: Build a training data set, the training data set includes multiple video-statement pairs; a video that makes a video and query statement, a video of a video, a video and query statement, a video that does not match? - The statement is labeled as a claim.
[0139] Alternatively, for a video to be queried, if the supplied natural language query statement does not match the video, the corresponding video-statement is considered to be a sample; if the supplied natural language query statement is matched to the video The corresponding video-statement is considered to be a sample.
[0140] Alternatively, during the training, the normal samples and...
Embodiment 3
[0155] Figure 4 A structural diagram of a video positioning device provided by the embodiment of the present invention. The apparatus is used to implement the video positioning method provided by the embodiment, including: video division module 410, feature extraction module 420, modal focus flow acquisition module 430, first feature update module 440, an modal focus flow acquisition Module 450, the second feature update module 460 and the similarity calculation and positioning module 470.
[0156] The video division module 410 is used to use a multi-scale time sliding window to divide the location of the video to obtain a plurality of video clips, where there is an overlap between the adjacent video clips.
[0157] Feature extraction module 420 is used to characterize each video clip and a query statement, and will result in the original feature of each video clip. R Decomposition is key R K , Query characteristics R Q And value characteristics R V , The original feature of each...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com