Speech synthesis method, device and equipment and storage medium
A technology of speech synthesis and synthetic speech, which is applied in speech synthesis, speech analysis, instruments, etc., can solve the problems of single speech quality and low speech quality, and achieve the effect of high quality and close speaking style
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
preparation example Construction
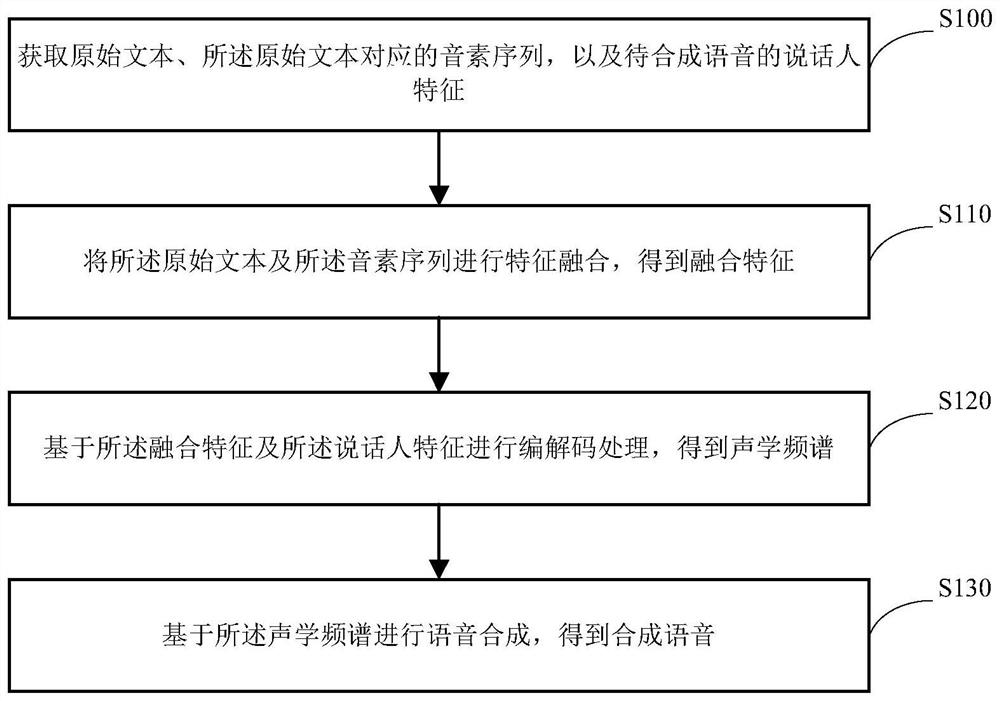
[0062] Next, combine figure 1 Described, the speech synthesis method of the present application may comprise the following steps:
[0063] Step S100: Obtain the original text, the phoneme sequence corresponding to the original text, and the speaker characteristics of the speech to be synthesized.
[0064] Specifically, before speech synthesis, it is necessary to obtain the original text to be subjected to speech synthesis. The original text may be text information in a single language, or may be text information in multiple languages, for example, the original text may be text information including two or more languages at the same time.
[0065] Further, considering the different pronunciation characteristics of different languages, the pronunciation characteristics of some languages may not be displayed in the form of text, for example, Chinese tone patterns, Japanese tone cores, Russian accents, etc. cannot be displayed in the form of word faces. , but can be displaye...
Embodiment approach
[0092] In an optional implementation manner, the specific implementation process of the above step S120 may include the following steps:
[0093] S1. Perform encoding processing on the fusion feature to obtain an encoded feature.
[0094] Specifically, the fusion feature can be encoded by the text encoder to obtain the encoded feature output by the text encoder.
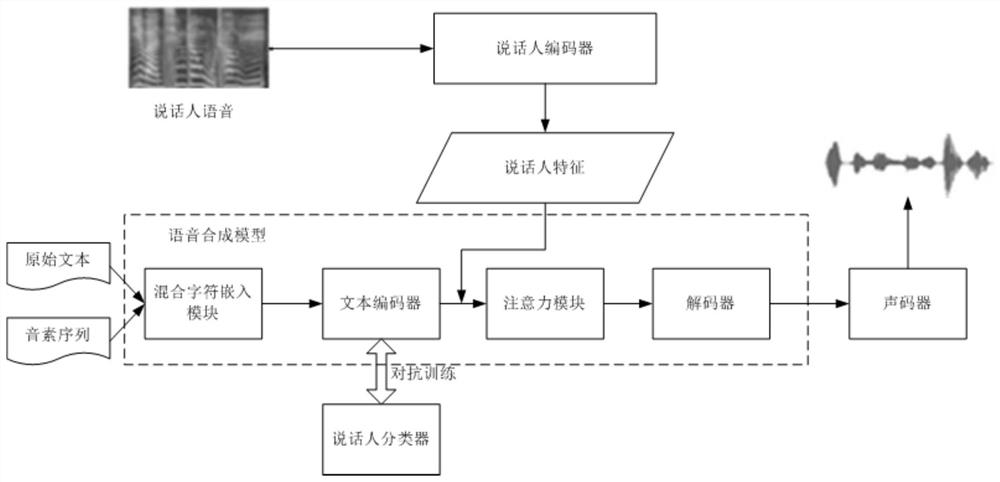
[0095] Further, considering that the existing end-to-end speech synthesis models all assume that the input is in a single language, the result is that when different languages are mixed in the input text, the existing models often synthesize wrong speech, or even skip it directly. word. At the same time, since it is difficult to obtain the speech of the same speaker in different languages, in order to prevent the model from erroneously learning the correlation between speaker characteristics and languages, resulting in the phenomenon of switching speakers in the synthesized speech, this embodiment provides a metho...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com