Multi-speaker voice synthesis method based on variational auto-encoder
An autoencoder and speech synthesis technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problems of low efficiency, high recording cost, and only the speech of a single speaker can be synthesized.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0070] The technical scheme of the present invention will be further described below in conjunction with the accompanying drawings.
[0071] The present invention proposes a multi-speaker speech synthesis method based on a variational autoencoder, which includes a training stage and a synthesis stage;
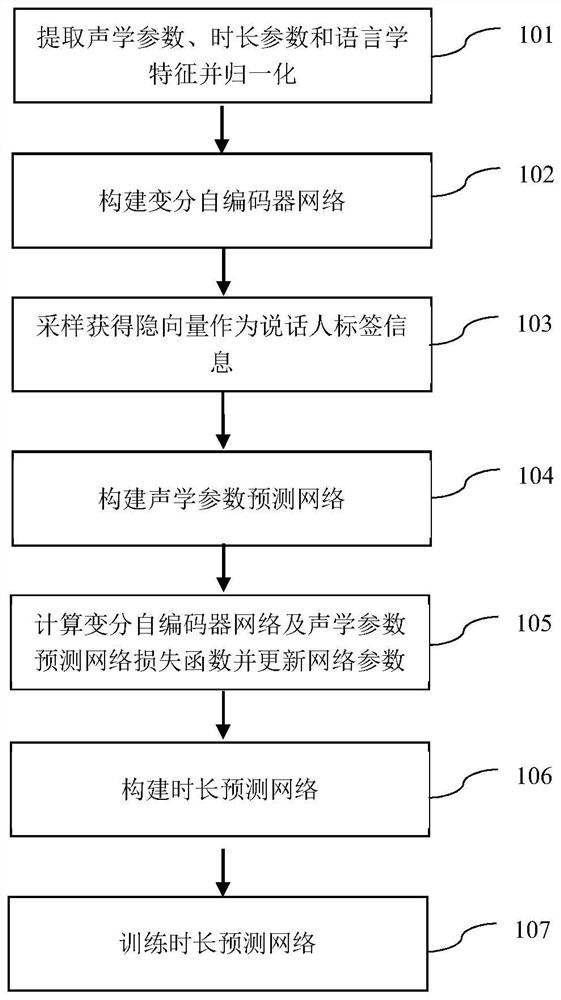
[0072] Such as figure 1 As shown, the training phase includes:
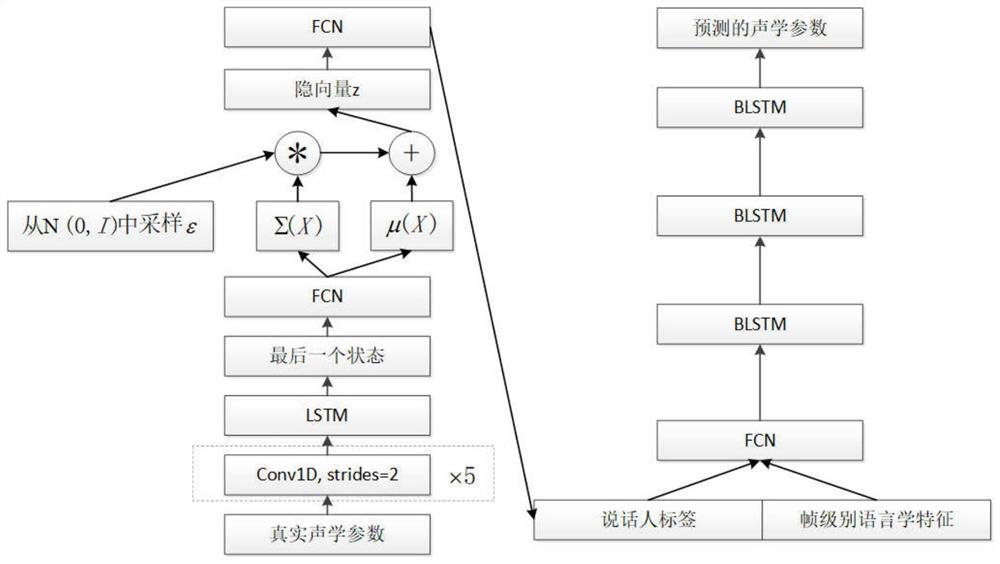
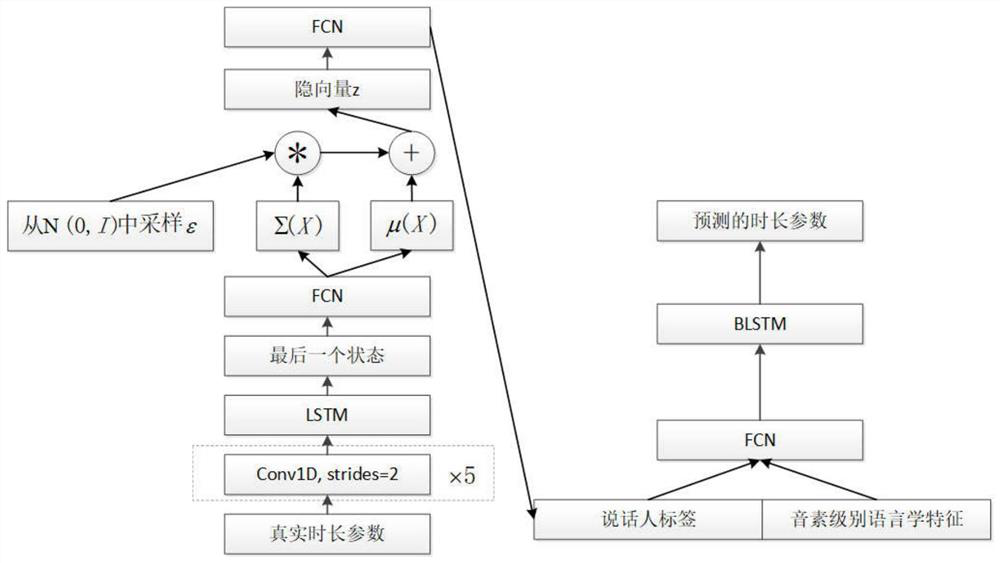
[0073] Step 101) Extracting frame-level acoustic parameters, phoneme-level duration parameters and frame-level, phoneme-level linguistic features from the recorded speech signals containing multiple speakers, and normalizing them respectively.
[0074] The frame-level acoustic parameters have a total of 187 dimensions, including: 60-dimensional Mel cepstral coefficients and their first-order and second-order differences, 1-dimensional fundamental frequency parameters and their first-order and second-order differences, 1-dimensional aperiodic parameters and their First-order and second-order difference, 1-dimensi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com