Networked multi-agent system distributed optimization control method based on reinforcement learning
A multi-agent system and optimal control technology, applied in program control, comprehensive factory control, electrical program control, etc., can solve problems such as complex system model, low system identification accuracy, and high cost
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0033] The present invention adopts following technical scheme:
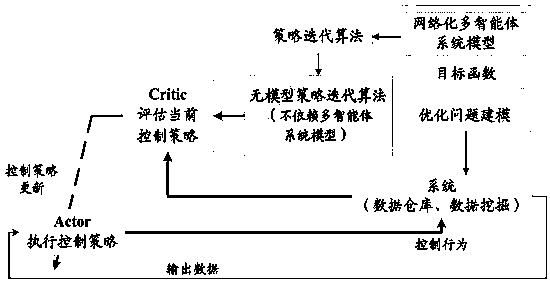
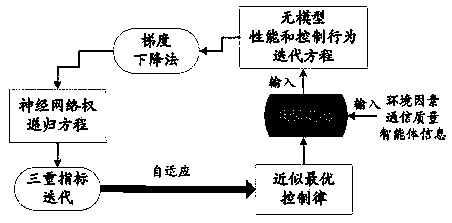
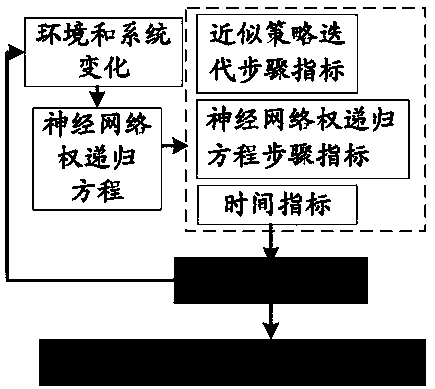
[0034](1) Solving the optimal control problem based on IRL and Off-policy. In this part, we intend to solve the optimal control problem involving the completely unknown model of the networked multi-agent system for both situations with and without a leader. Based on the previous research results, the IRL technology and the off-policy strategy iterative reinforcement learning method are integrated, and extended to the optimal consensus control of the multi-agent system whose system model is completely unknown. Note that the existing iterative reinforcement learning method based on IRL and off-policy strategy optimizes the control problem, and the object is a single system whose system model is completely unknown, while the agents in the multi-agent system are coupled with each other and have distributed characteristics. , so this extension is not a direct and simple extension, and there are many scientific proble...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com