A training method combining face recognition data equalization and enhancement
A face recognition and training method technology, applied in the field of image classification based on deep learning, can solve the problems of data difference and real scene, data imbalance, etc., to achieve low loss convergence value, high balance, and fast training convergence. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
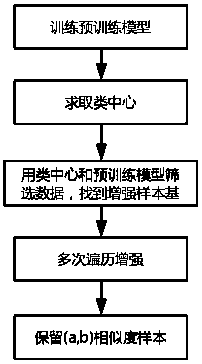
[0043] A training method combining face recognition data equalization and enhancement, such as figure 1 shown, including the following steps:
[0044] S1. Generate a training pre-model using the photos contained in all the cluster label ids of the dataset;
[0045] S2. Screen out the enhanced sample picture bases in all clustering label ids of the data set; the enhanced sample picture bases are pictures whose quality meets certain conditions in each clustering label id;
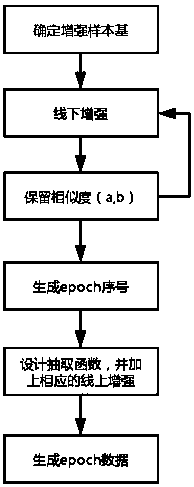
[0046] S3. Perform offline enhancement on the enhanced sample image base, and filter out the similarity between each cluster label id in the enhanced sample image base after offline enhancement and the cluster center of the cluster label id in the similarity interval (a, b) between n sample pictures;
[0047] S4. Design a data equalization method to perform data equalization on the sample image;
[0048] S5. Perform online enhancement on the sample image after data equalization.
[0049] Working principle...
Embodiment 2
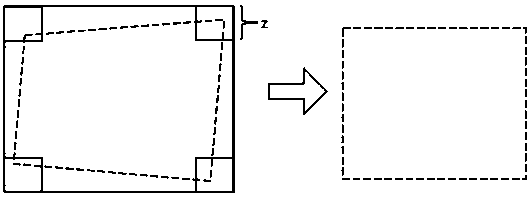
[0051] In order to better realize the present invention, further, in combination with figure 2 As shown, the S2 specifically includes the following steps: S2.1. Use the pre-model generated by S1 to determine the class center of each class of cluster label id of the data set;
[0052] S2.2. According to the cluster center determined by the cluster label id of each category, select the pictures whose similarity with the cluster center is higher than the parameter t in the corresponding cluster label id.
[0053]Working principle: The class center of each cluster label id is determined through the pre-training model. For example, the glint dataset has 180,000 cluster label ids, that is, a matrix of 180000×512 is generated and saved. The calculation formula of each class center is as follows: emb_i=model(img_i)
[0054] mid_emb=(emb_0+emb_1+....emb_n) / nmid_emb.shape:1×512;
[0055] After the class center of each cluster label id is determined through the pre-training model, we ...
Embodiment 3
[0058] In order to better realize the present invention, further, the parameter t can be adjusted according to the size of the data set and actual requirements.
[0059] Working principle: Through the similarity parameter t, the pictures similar to the class center in the data set can be screened out, because the offline enhancement belongs to the category of large-scale enhancement, only the data near the class center is selected for selection, and the similarity parameter t is set for screening , can remove some outlayers and some data at the edge of the class; after many experiments in the present invention, the value of the parameter t is selected to be 0.65, but if the selected data sets are different, and the requirements for the accuracy of the experiment are different, The specific value of the similarity parameter t can be adjusted up and down independently.
[0060] Other parts of this embodiment are the same as those of Embodiment 1-2 above, so they will not be repe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com