


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Voice synthesis model training method and device, electronic equipment and storage medium
A technology of speech synthesis and training method, applied in the field of artificial intelligence and computer intelligent speech, can solve the problems of poor synthesis effect and insufficient pronunciation of finals, and achieve the effect of improving human-computer interaction experience, reducing pronunciation problems, and improving user stickiness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
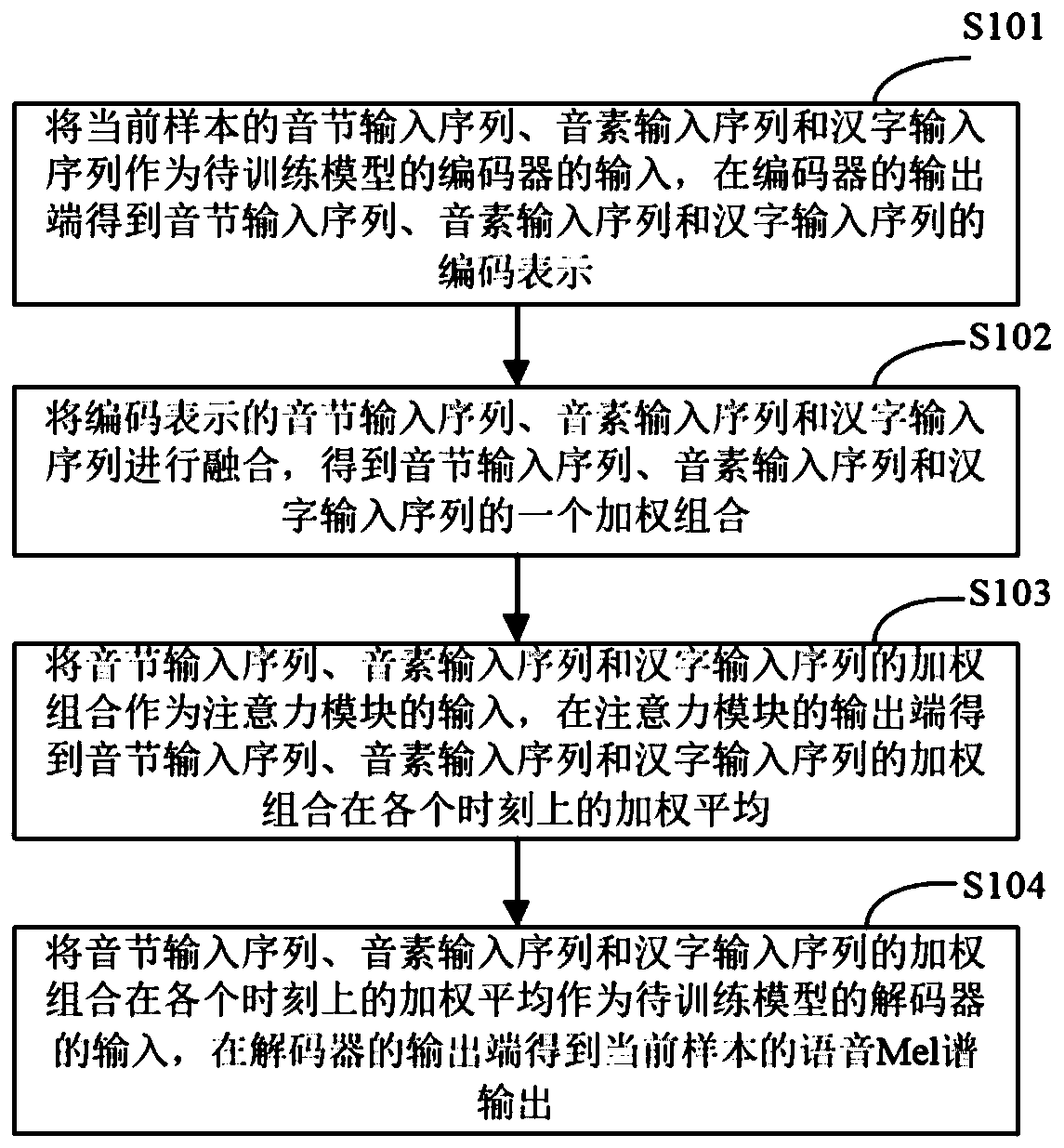
[0051] figure 1 It is a schematic flowchart of a speech synthesis model training method provided in Embodiment 1 of the present application. The method can be executed by a speech synthesis model training device or an electronic device, and the device or electronic device can be implemented by software and / or hardware. This device or electronic equipment can be integrated in any intelligent equipment with network communication function. Such as figure 1 As shown, the training method of the speech synthesis model may include the following steps:
[0052] S101. Use the syllable input sequence, phoneme input sequence and Chinese character input sequence of the current sample as the input of the encoder of the model to be trained, and obtain the encoded representations of the syllable input sequence, phoneme input sequence and Chinese character input sequence at the output end of the encoder.
[0053] In a specific embodiment of the present application, the electronic device can...
Embodiment 2
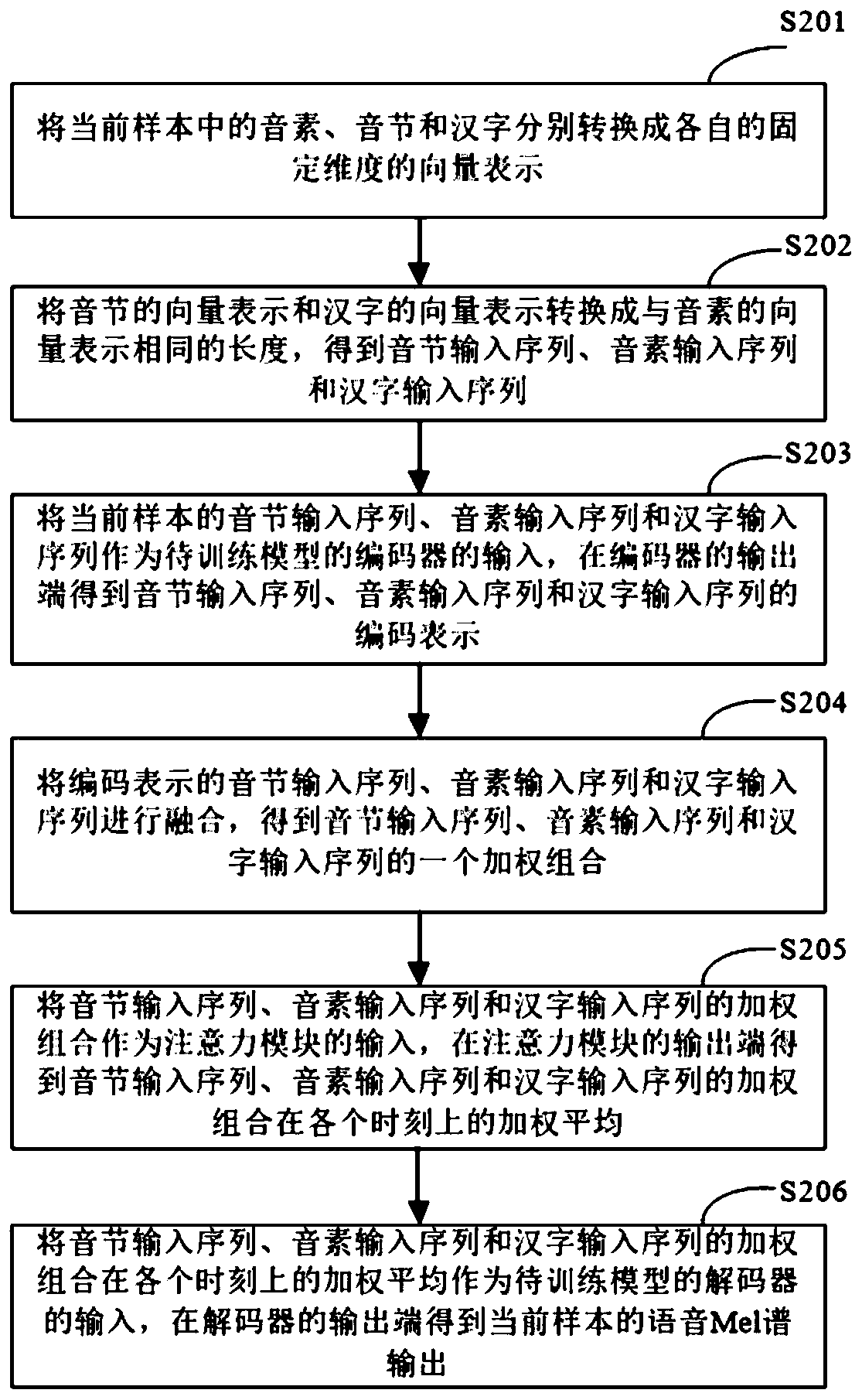
[0063] figure 2 It is a schematic flowchart of the training method of the speech synthesis model provided in the second embodiment of the present application. Such as figure 2 As shown, the training method of the speech synthesis model may include the following steps:
[0064] S201. Convert the phonemes, syllables and Chinese characters in the current sample into their respective fixed-dimensional vector representations.
[0065] In a specific embodiment of the present application, the electronic device may convert the phonemes, syllables and Chinese characters in the current sample into respective fixed-dimensional vector representations. Specifically, the electronic device may convert phonemes in the current sample into vector representations of a first length; convert syllables and Chinese characters in the current sample into vector representations of a second length; wherein the first length is greater than the second length.
[0066] S202. Convert the syllable vecto...
Embodiment 3
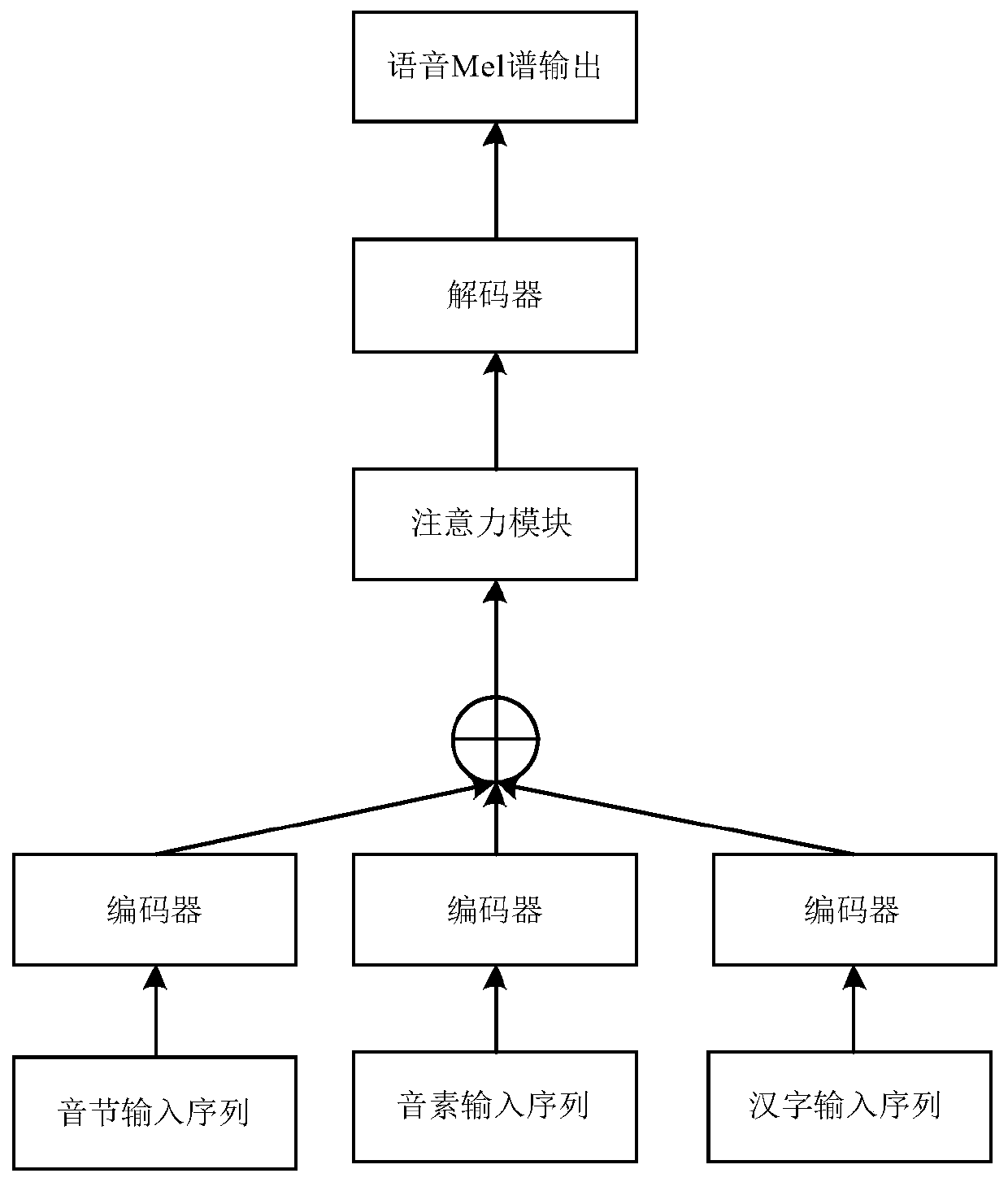
[0080] Figure 4 It is a schematic structural diagram of a training device for a speech synthesis model provided in Embodiment 3 of the present application. Such as Figure 4 As shown, the device 400 includes: an input module 401, a fusion module 402 and an output module 403; wherein,
[0081] The input module 401 is configured to use the syllable input sequence, the phoneme input sequence and the Chinese character input sequence of the current sample as the input of the encoder of the model to be trained, and obtain the syllable input sequence, the An encoded representation of the phoneme input sequence and the Chinese character input sequence;
[0082] The fusion module 402 is configured to fuse the syllable input sequence, the phoneme input sequence, and the Chinese character input sequence represented by the code, to obtain the syllable input sequence, the phoneme input sequence, and the Chinese character input sequence A weighted combination; the weighted combination o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com