Video face recognition method combining deep Q learning and attention model
An attention model and face recognition technology, applied in the field of video face recognition, can solve the problem of insufficient accuracy of video face matching
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

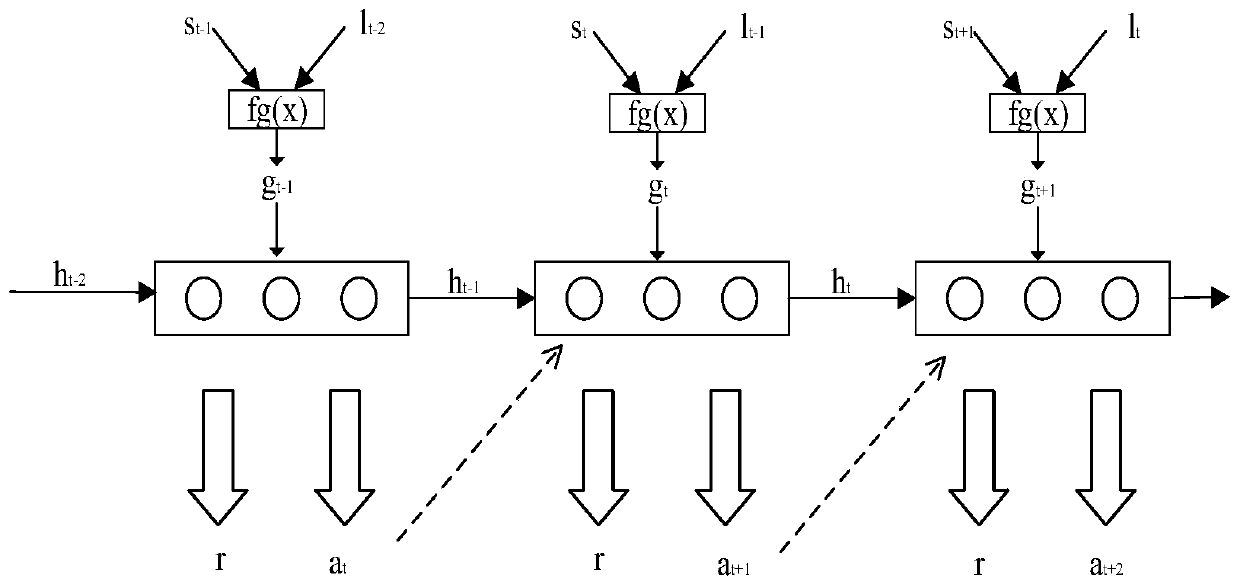
Examples
Embodiment
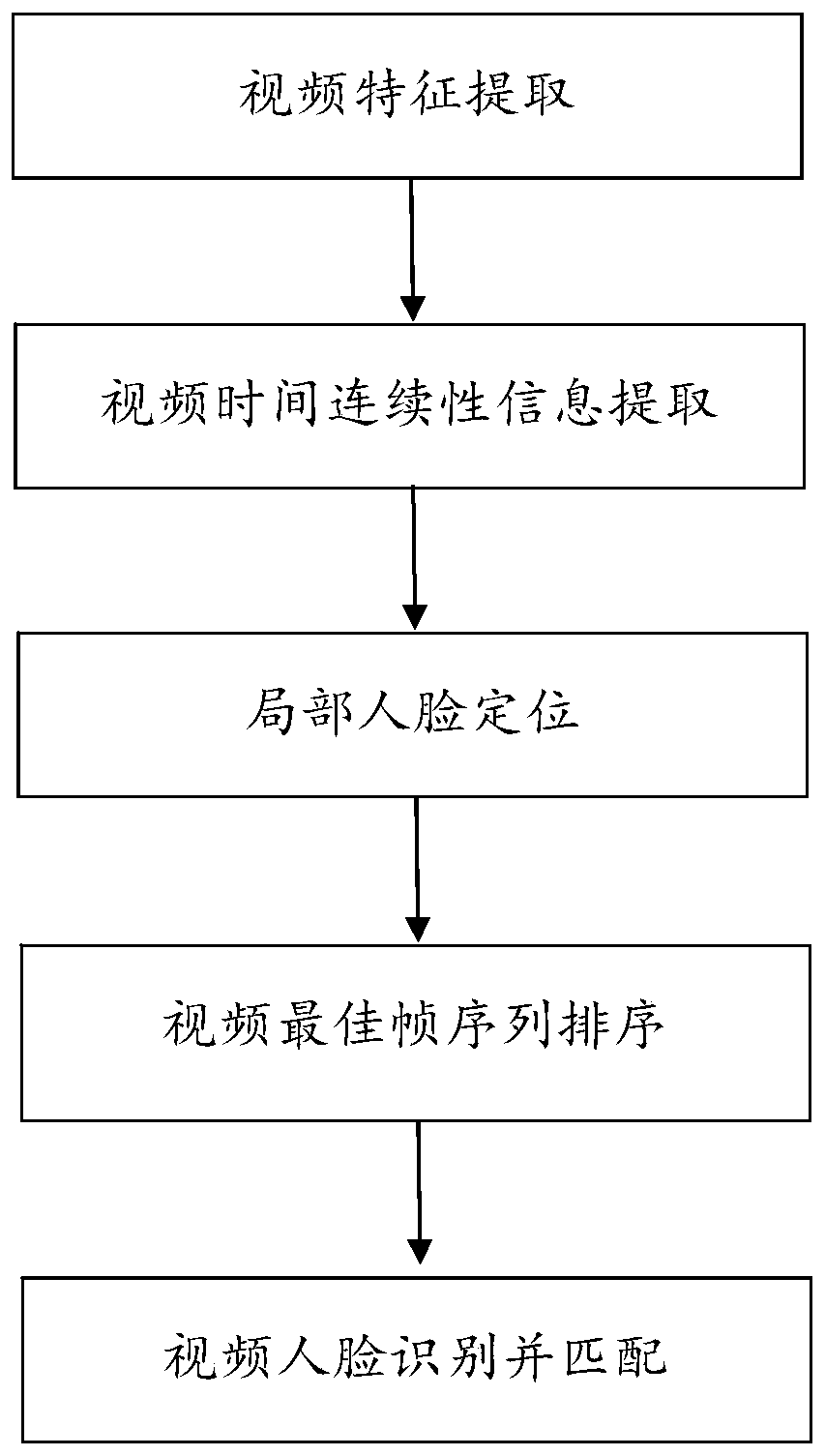
[0072] Video Face Recognition Approaches Combining Deep Q-Learning and Attention Models, as figure 1 As shown, it specifically includes the following steps:
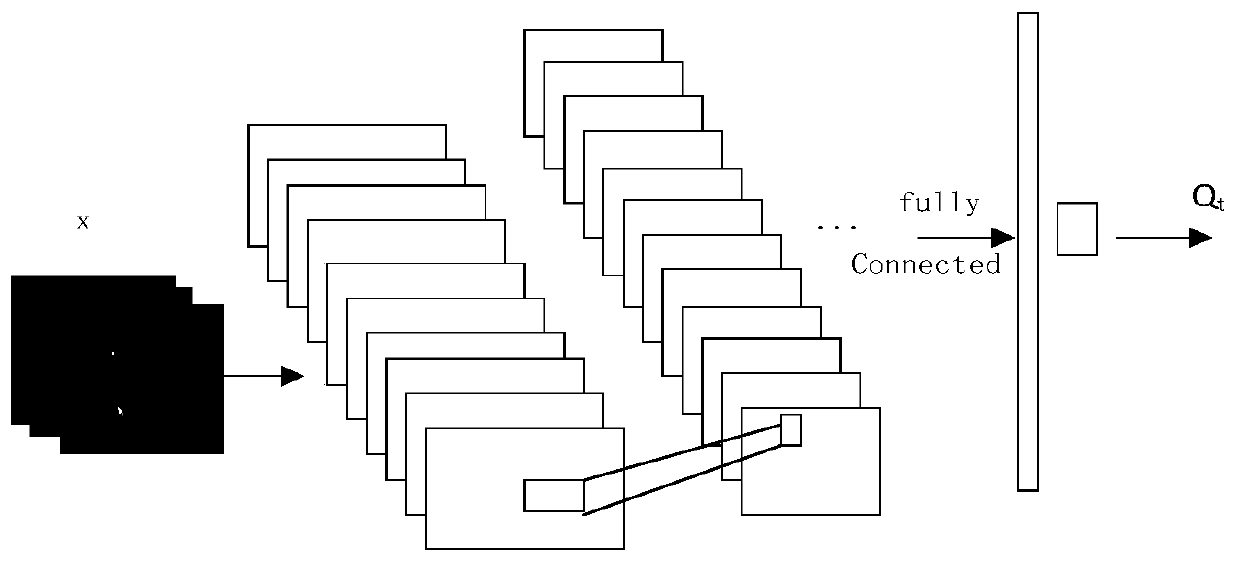
[0073] Step S1: Video feature extraction: Convolutional Neural Networks (CNN) is used to train video data, and different feature planes are extracted, which are combined into multi-dimensional features of the video.
[0074] In the step S1, use the labeled video sample data to train the convolutional neural network, use the trained convolution model to extract features from the video data, and each convolution kernel slides the calculated matrix representation on the input data It is called a feature surface. Multiple convolution kernels perform convolution calculations to generate multiple feature surfaces. Multiple sets of feature surfaces are combined to form multi-dimensional features of the video. There is no neuron connection between each feature surface. The previous layer The output of the characteristic surface...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com