Text classification method based on TF-IDF matrix and capsule network
A TF-IDF, text classification technology, applied in the field of text classification based on TF-IDF matrix and capsule network, can solve problems such as large amount of calculation and poor interpretability, and achieve the effect of improving efficiency and reducing text features
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

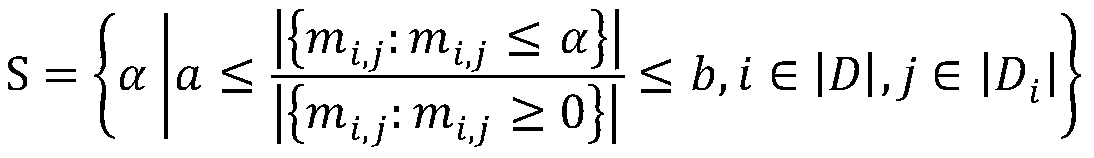
Examples
Embodiment 1
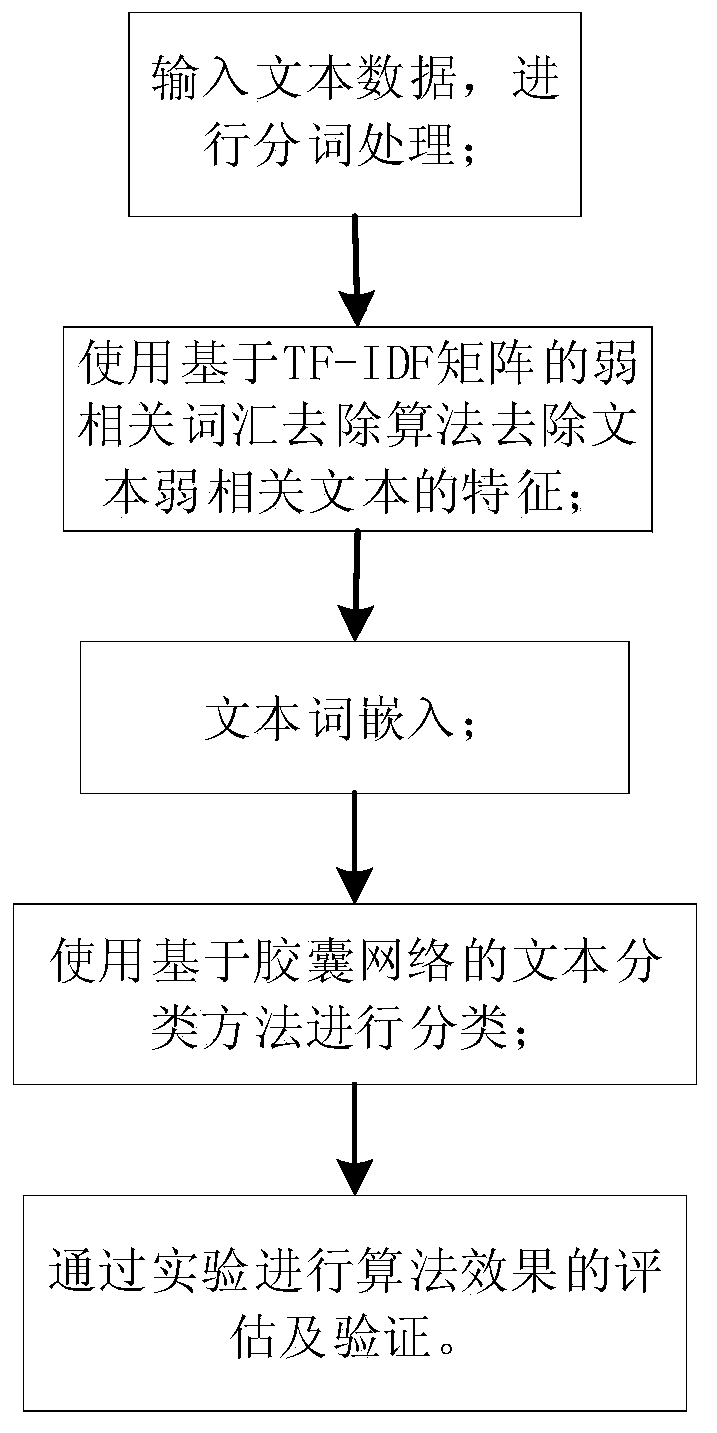
[0037] In order to achieve the above purpose, the embodiment of the present invention proposes a text classification method based on TF-IDF matrix and capsule network, see figure 1 , the method includes the following steps:
[0038] 101: Perform word segmentation processing on the input text data;
[0039] 102: Use the weakly related vocabulary removal algorithm of TF-IDF matrix to remove stop words from the text data, delete some words in the text data set D, and obtain a text data set D' with more obvious features after processing, as a classifier enter;
[0040] 103: Obtain text vector embedding through doc2vec algorithm processing;
[0041] 104: Use the obtained text vector embedding as the input of the capsule network-based text classification, and train the capsule network text classification model.
[0042] In one embodiment, step 101 performs word segmentation processing on the text data, and the specific steps are as follows:
[0043] For text data, when performin...
Embodiment 2
[0056] The scheme in embodiment 1 is verified for feasibility below in conjunction with specific calculation formulas and examples, see the following description for details:
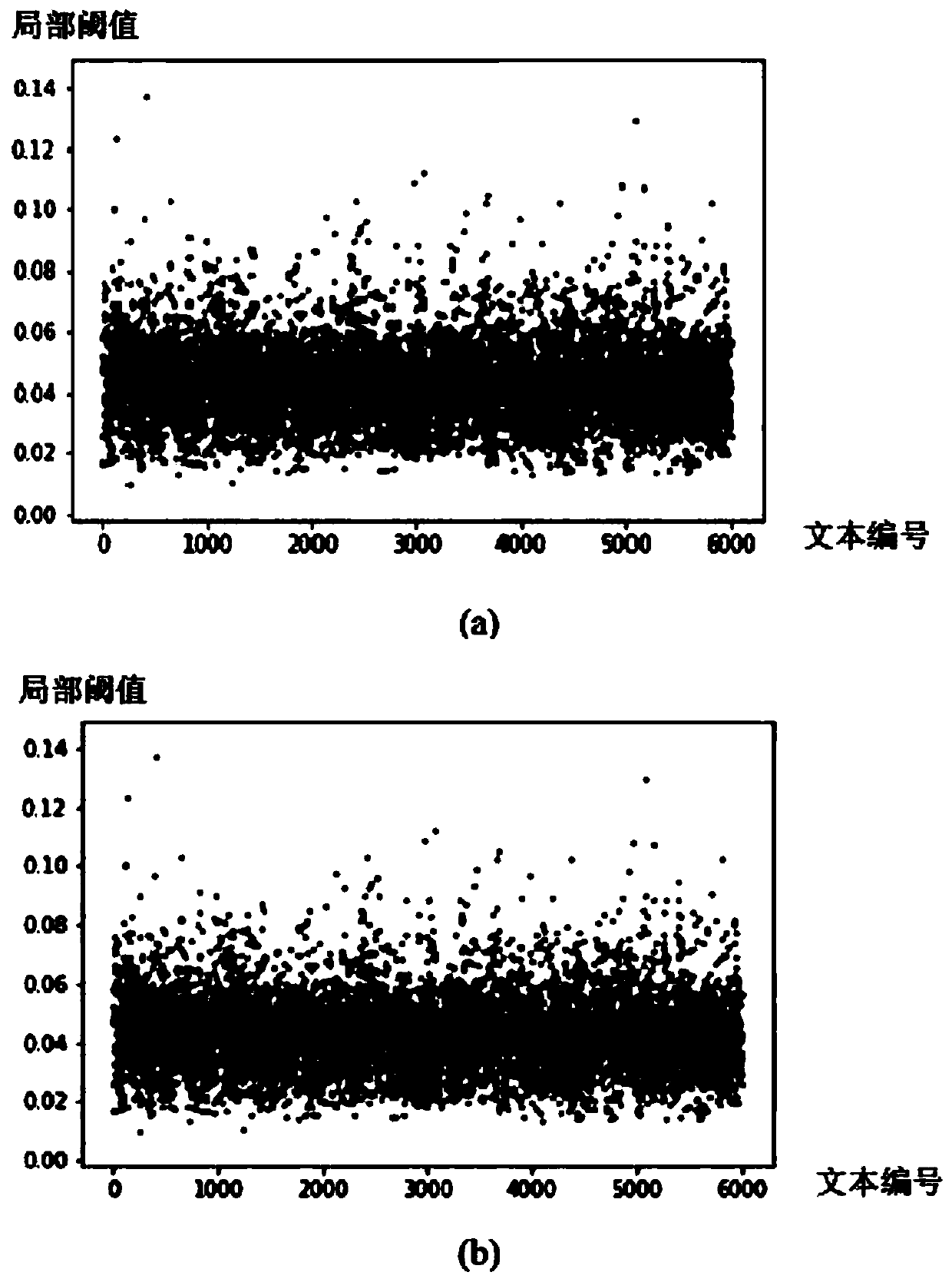
[0057] 201: Before classifying the text, the text data must be segmented first, separated by spaces, and the dictionary Dic corresponding to the text data set is constructed, and the words appearing in the text are not repeatedly counted. The constructed dictionary is included in the text Dic_n different words appearing in the data;
[0058] 202: The data obtained after word segmentation is used to remove stop words based on the weakly related vocabulary removal algorithm based on TF-IDF matrix, so as to reduce the storage space of text data and improve the operation efficiency of the algorithm, comprehensively analyze the TF-IDF matrix M, and obtain the satisfaction Conditional global threshold α;
[0059] Among them, all the values of the TF-IDF matrix M are sorted to obtain the threshold α that sa...
Embodiment 3
[0089] Below in conjunction with concrete example, data, the scheme in embodiment 1 and 2 is carried out feasibility verification, see the following description for details:
[0090] In the experiment of the weakly relevant vocabulary removal algorithm based on TF-IDF matrix, the final threshold value of each text is calculated, and the weakly relevant vocabulary set of each text is determined through the final threshold value, and all the words that appear in the text in this piece of text data are The vocabulary in the weakly related vocabulary set is deleted, the processed text data is retained, and finally all the processed text data are integrated to generate a new text data set.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com