


Quick Research
Generate reliable direction feasibility study reports for your R&D in just a few steps.

Technical Q&A
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

Find Solutions
As an expert in R&D theories, this can generate solutions to your technical problems instantly.

Evaluate Feasibility
Analyze your overall solution with one click, know your potential R&D risks in advance.

Monitor Landscape
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Parallelization optimization method for SM3 cryptographic hash algorithm
A technology of hash algorithm and optimization method, which is applied in the field of security password application, can solve the problems of not being able to make full use of non-vector processor computing resources, and cannot improve the operation speed of a single SM3 cryptographic algorithm, and achieve the effect of eliminating assignment operations and simplifying assignments
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
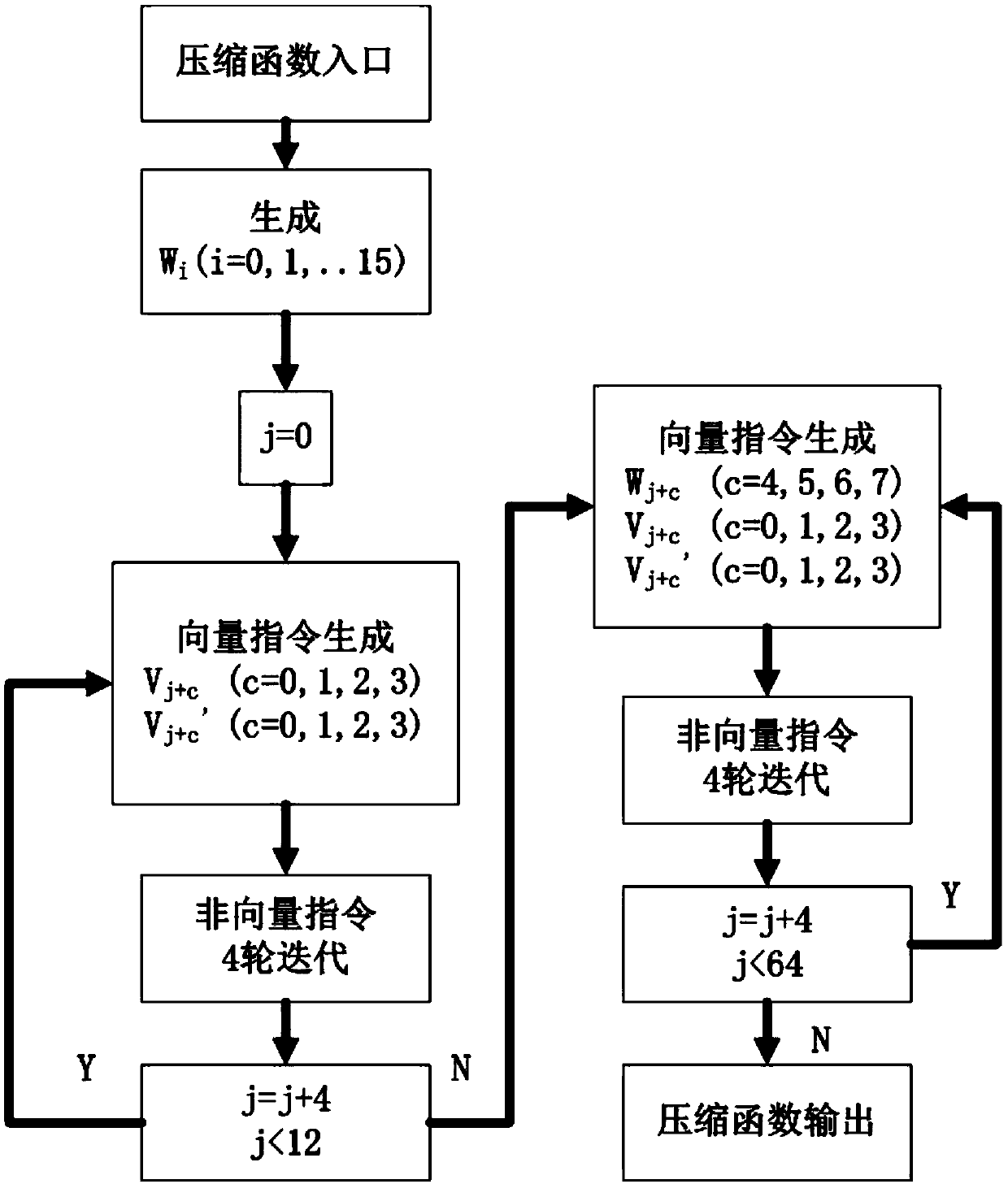
[0818] Embodiment 1: Realization of ARM / NEON instruction set
[0819] The ARM processor is currently the mainstream processor used in smart mobile devices such as mobile phones. Among them, the most widely deployed Cortex-A series ARM processor architecture includes not only the ARM general-purpose instruction set (ARMv7 instruction set), but also the NEON SIMD instruction set. The NEON instruction set contains 16 128-bit SIMD registers, which can perform parallel calculations of 4-way 32-bit words. Therefore, the vector calculation in the 4-way parallel algorithm of the SM3 compression function in this paper can be implemented with NEON instructions, and other instructions can be implemented with conventional ARM Realization of general instructions, which can be written in high-level language and realized by compiling.
[0820] The NEON instructions used are given below. These instructions are given in the form of pseudo functions (Intrinsics), where int32x4_t is a 128-bit NE...
Embodiment 2
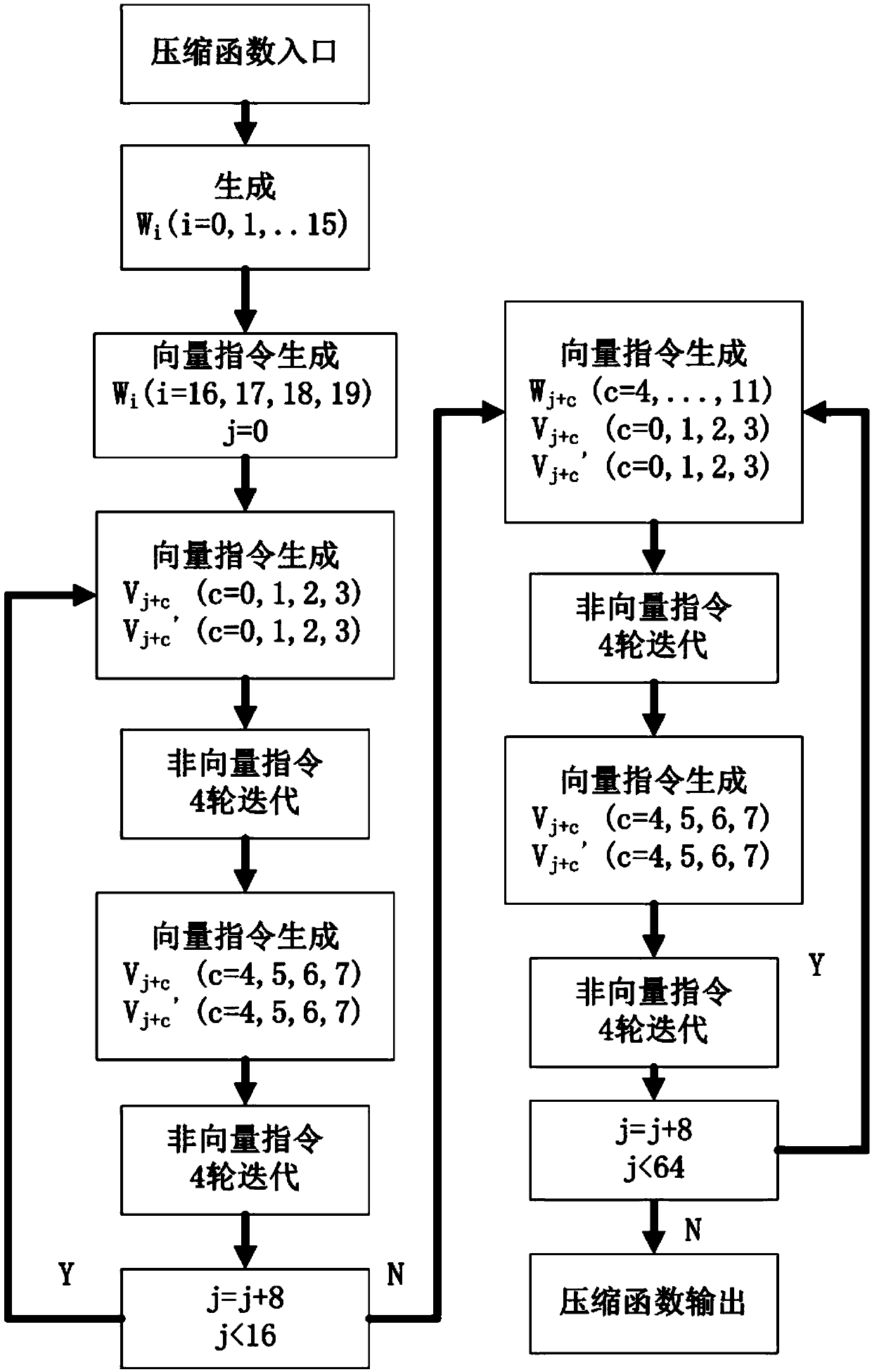
[0825] Embodiment 2: Implementation of X86 / AVX2 instruction set
[0826] Non-vector code can be written in a high-level language and implemented through compilation, and vector algorithms are implemented using AVX2 instructions
[0827] Use the command _m256i c = _mm256_xor_si256(_m256i a, _m256i b)
[0828] c←a<<
[0829] Vector shift left _mm256_sllv_epi32(_m256i a, _m256i count)
[0830] Vector shift right _mm256_srlv_epi32(_m256i a, _m256i count)
[0831] vector or _mm256_or_si256(_m256i a, _m256i b)
[0832] The overall execution statement is as follows:
[0833] _mm256i c=mm256_or_si256(_mm256_sllv_epi32(a,k),_mm256_srlv_epi32(a,32-k))
[0834] c←a+b: use the command _m256i c=_mm256_xor_si256(_m256ia, _m256i b)
[0835] c←b:_m256ic=_mm256_stream_load_si256(_m256i const*mem_addr_of_b)
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com