Method for text classification using diverse text features
A technology of sample features and text classification, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve problems such as inability to mine internal structures well
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
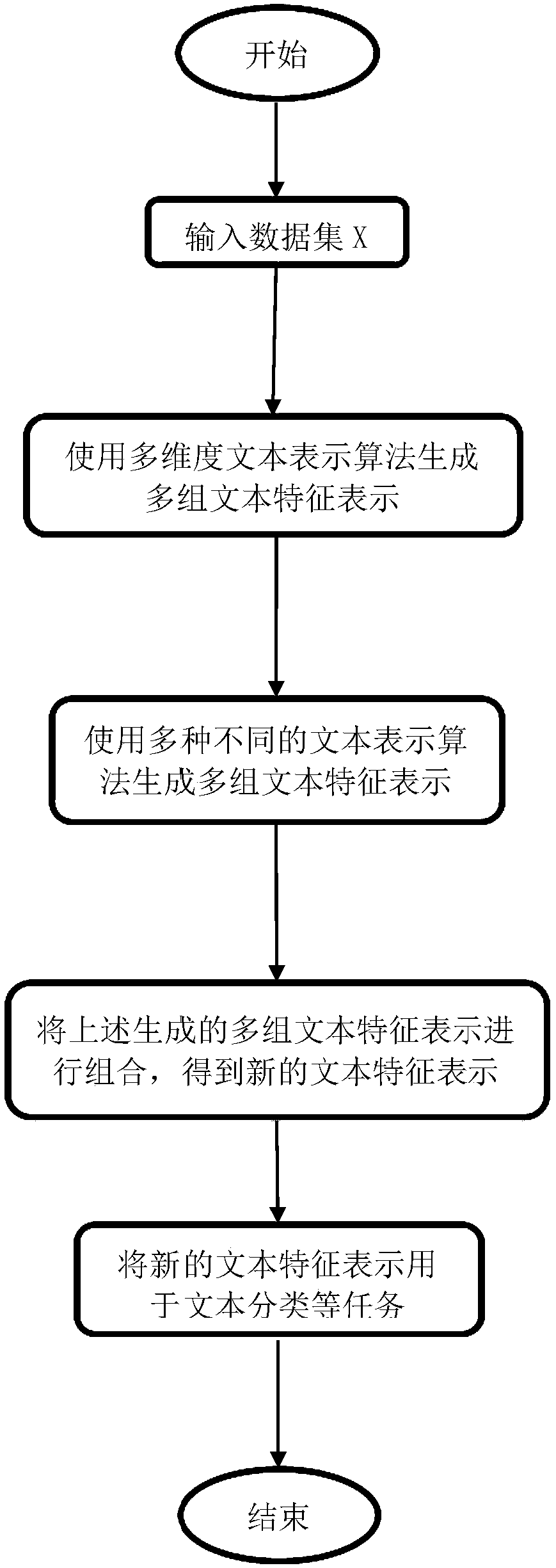
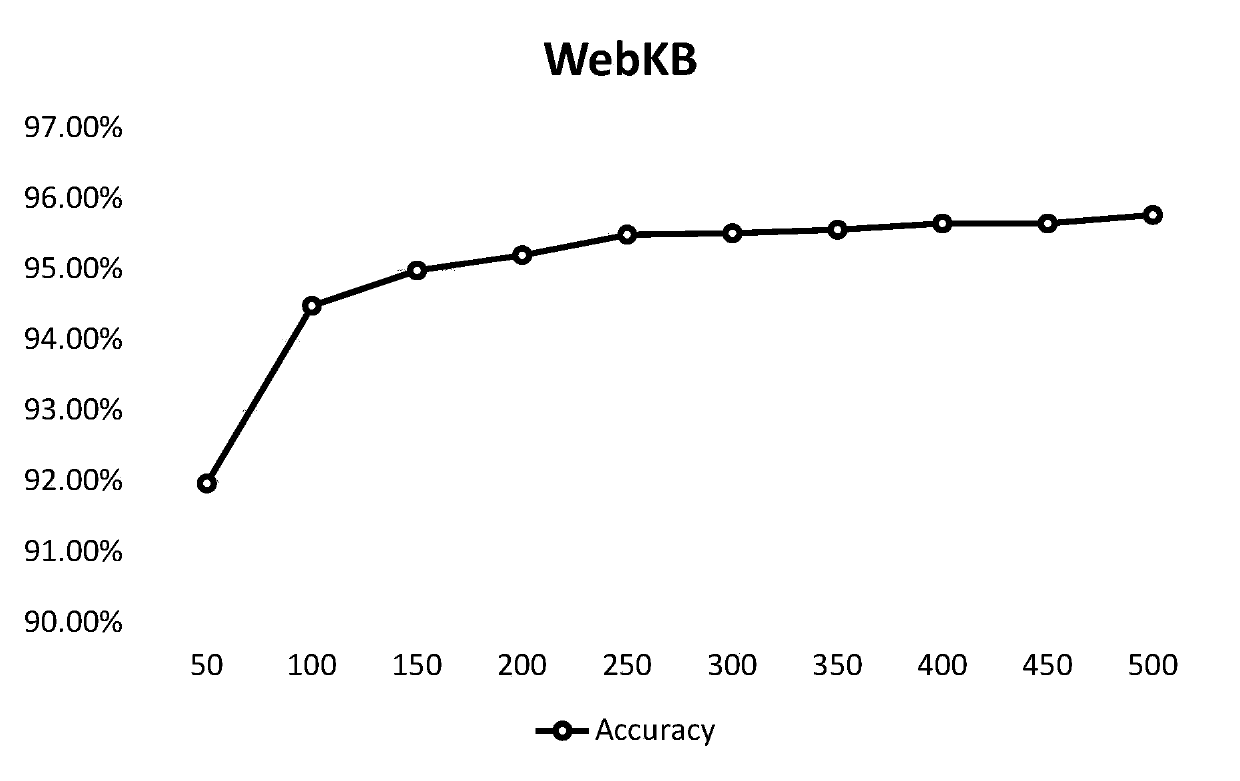
[0091] In this embodiment, the WebKB data set (http: / / www.webkb.org / ) is used as the experimental data set, and the improved Dec.k-Means algorithm is used to generate multi-dimensional text representations, and ten sets of feature representations are generated, each set of features is 50 dimension, such as figure 1 Shown is a flow chart of the present invention when generating a text representation. The application process is as follows:
[0092] 1. Taking the WebKB dataset as input, the detailed information of the dataset is shown in Table 1:
[0093] Table 1
[0094] Number of samples in the training set
[0095] 2. Use the improved Dec.k-Means to generate m=10 sets of feature representations for the training set and test set. In each set of feature representations, the dimension of the feature vector is k 1 =k 2 =...=k 10 =50, the specific steps are as follows:
[0096] (1) Use the bag of words model + TF-IDF weight to convert the training set and test set i...
Embodiment 2
[0116] In this example, the AG's corpus of news articles data set, referred to as the AGNews data set (http: / / www.di.unipi.it / ~gulli / AG_corpus_of_news_articles.html) is used as the experimental data set, and the improved Alter LDA algorithm is used to generate multi-dimensional The text representation of , generate ten sets of feature representations, each set of features is 50 dimensions, the application process is as follows:
[0117] 1. Taking the AG News dataset as input, the details of the dataset are shown in Table 3:
[0118] table 3
[0119] Number of samples in the training set
[0120] 2. Use Alter LDA to generate m=10 sets of feature representations for the training set and test set. In each set of feature representations, the dimension of the feature vector is k 1 =k 2 =...=k 10 =50, the specific steps are as follows:
[0121] (1) Use the Latent Dirichlet Allocation (LDA) algorithm to obtain the topic distribution of words β (1) , the topic distribut...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com