Rank-Based Text Matching Method for Plagiarism Detection
A matching method and text technology, which can be used in unstructured text data retrieval, text database clustering/classification, semantic analysis, etc., can solve problems such as poor detection performance, and achieve the effect of improved statistical significance and good performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
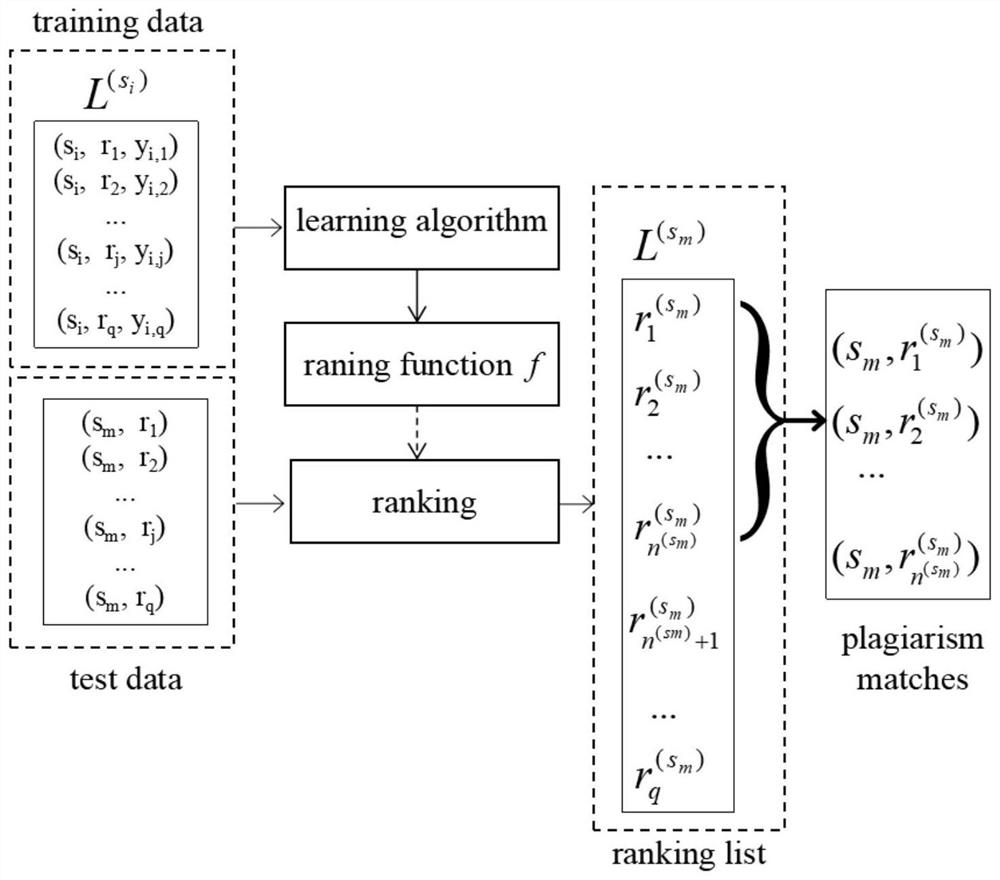
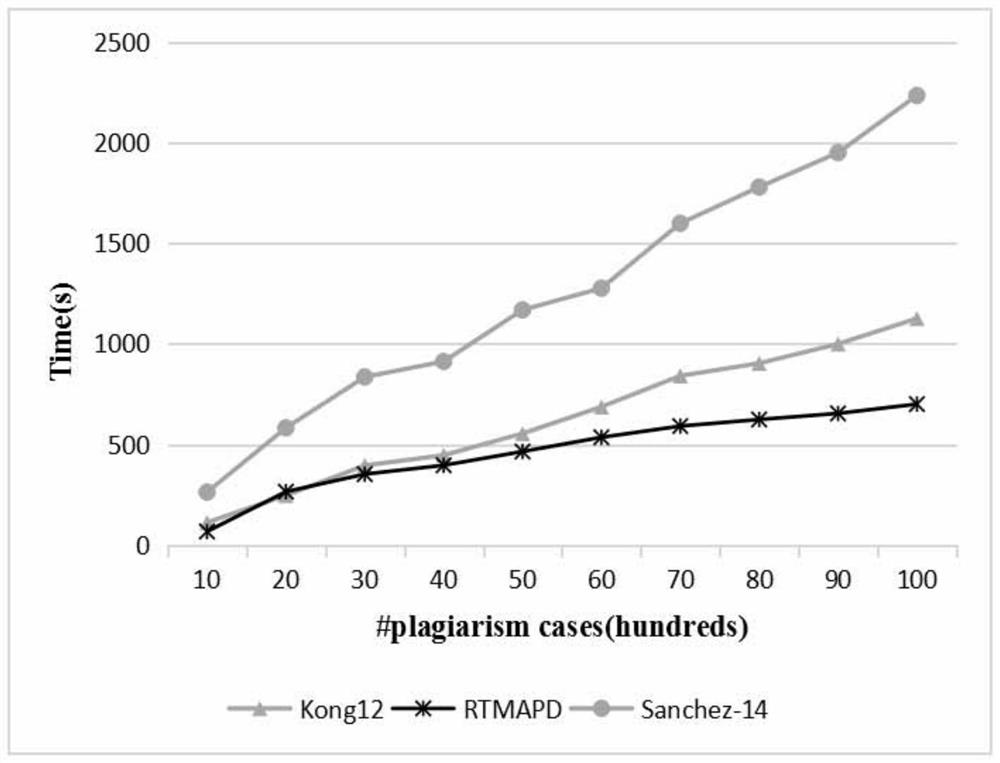
[0068] Such as Figure 1 to Figure 2 As shown, this embodiment is specifically described as follows for the sorting-based plagiarism detection text matching method:
[0069] 1 about plagiarism
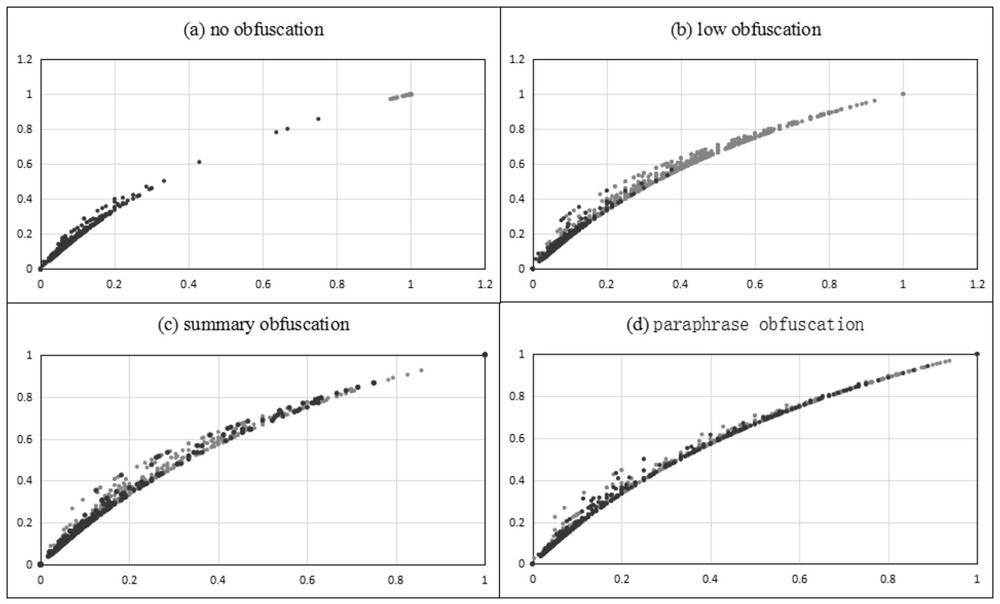
[0070] Generally, plagiarism can be divided into low-ambiguity plagiarism (such as full copy, partial copy, simple modification) and high-ambiguity plagiarism (including paraphrase plagiarism, summary plagiarism, cross-language plagiarism, etc.) (Alzahrani et al., 2012). The low performance of high-fuzzy plagiarism detection is the biggest problem in plagiarism detection at present, and heuristic methods are far from achieving satisfactory performance on high-fuzzy plagiarism detection. The main reason is that the vocabulary of highly fuzzy plagiarized text is quite different from that of the source text, and the number of vocabulary matches is very small, so it is difficult to accurately identify plagiarized matches.
[0071] 2 Analysis of Plagiarism Matching Problems
[0072] To i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com