Realization method for analysis model supporting massive long text data classification
An analysis model and data classification technology, which is applied in text database clustering/classification, unstructured text data retrieval, electronic digital data processing, etc., to achieve the effects of reducing classification accuracy, improving algorithm efficiency, and meeting performance requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0014] The present invention will be further described in detail with reference to the accompanying drawings and embodiments.
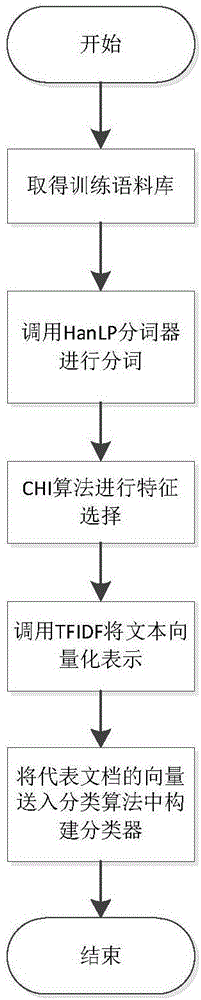
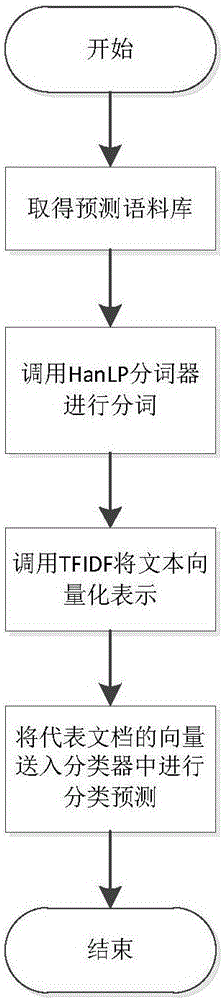
[0015] The present invention provides an analysis model supporting the classification of massive long text data and its implementation method. The analysis model adopts a text classification algorithm based on statistics. The text classification algorithm adopts a vector space model (VSM), and extracts from the CHI algorithm. According to the TFIDF algorithm, the category feature words realize the vectorized representation of the text, and use the naive Bayesian method to train the corpus, and realize the analysis model for the classification of massive long text data.
[0016] The analysis model is realized through the following steps:
[0017] The first step is to establish a VSM-based statistical classification model to represent the text in a vectorized manner.
[0018] Because the situation of directly processing natural language is too complica...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com