Text clustering method and system
A text clustering and text technology, applied in the field of text clustering, can solve the problems of poor matching effect and low accuracy, and achieve the effect of improving the effect, good adaptability, and avoiding the uniqueness of the centroid.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
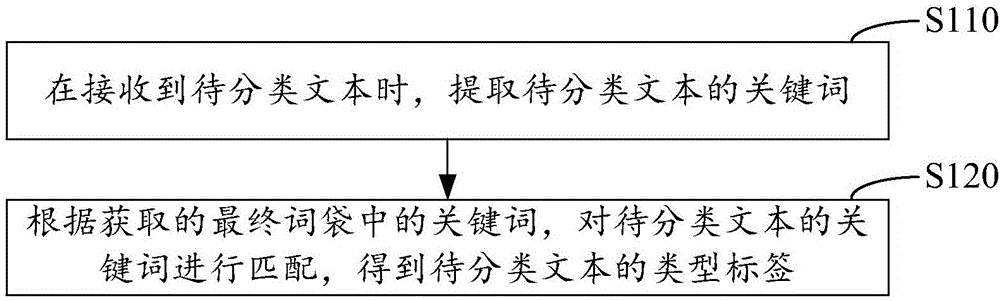
[0024] In order to solve the problems of low accuracy and poor matching effect of traditional text clustering methods, the present invention provides a text clustering method embodiment 1; figure 1 It is a schematic flow diagram of Embodiment 1 of the method for text clustering of the present invention; as figure 1 As shown, the following steps may be included:
[0025] Step S110: When receiving the text to be classified, extract the keywords of the text to be classified
[0026] Step S120: According to the keywords in the obtained final bag of words, match the keywords of the text to be classified to obtain the type label of the text to be classified; wherein, the final bag of words is a collection of words from all kinds of word bags according to the preset selection rules It is obtained after sorting and filtering the keywords; the class tag word bag is a set of keywords generated after keyword extraction of each text corresponding to each type of tag.
[0027] Specifical...
Embodiment 2
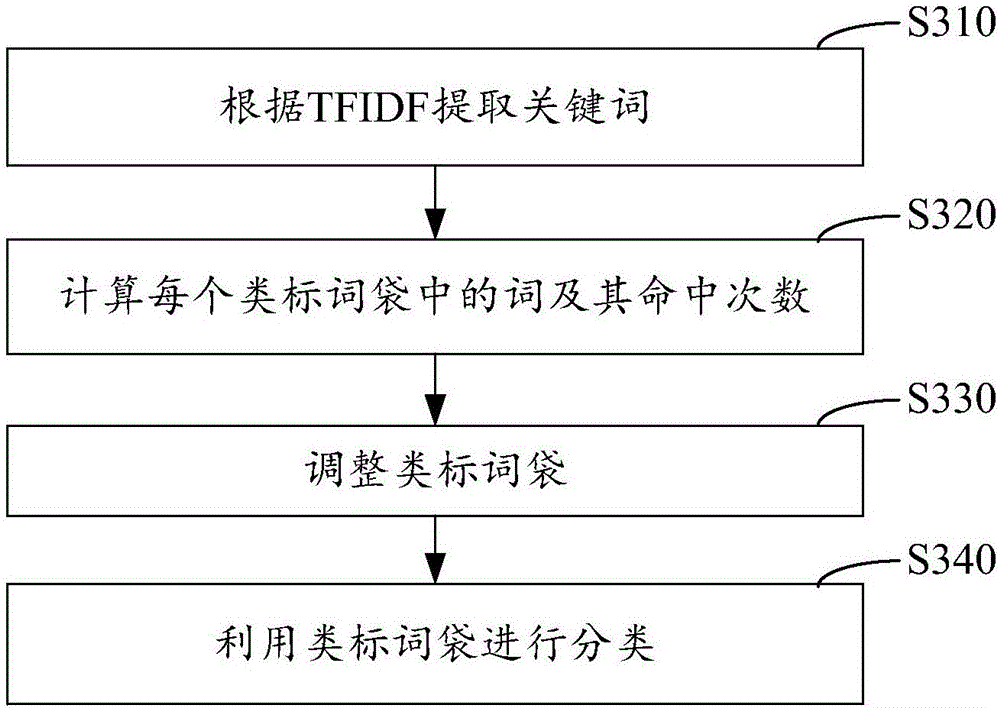
[0052] In order to solve the problems of low accuracy and poor matching effect of traditional text clustering methods, the present invention also provides a text clustering method embodiment 2; image 3 It is a schematic flow diagram of Embodiment 2 of the method for text clustering of the present invention; as image 3 As shown, the following steps can be included, generating keywords→constructing word bag through keywords→adjusting word bag→using word bag classification, including:
[0053] Step S310: extract keywords according to TFIDF;
[0054] TF can be calculated based on the following formula: (the number of times the word appears in the document) / (the total number of words in the document), the larger the value, the more important the word, that is, the greater the weight.
[0055] For example: after a document is segmented, there are a total of 500 word segments, and the word segment "Hello" appears 20 times, then the TF value is: tf=20 / 500=2 / 50=0.04;
[0056] IDF c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com