Text feature selection method based on unbalanced data sets
A data set and balanced technology, applied in the direction of electrical digital data processing, special data processing applications, unstructured text data retrieval, etc., can solve the problems of not fully considering important factors affecting feature selection, large amount of information gain calculation, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

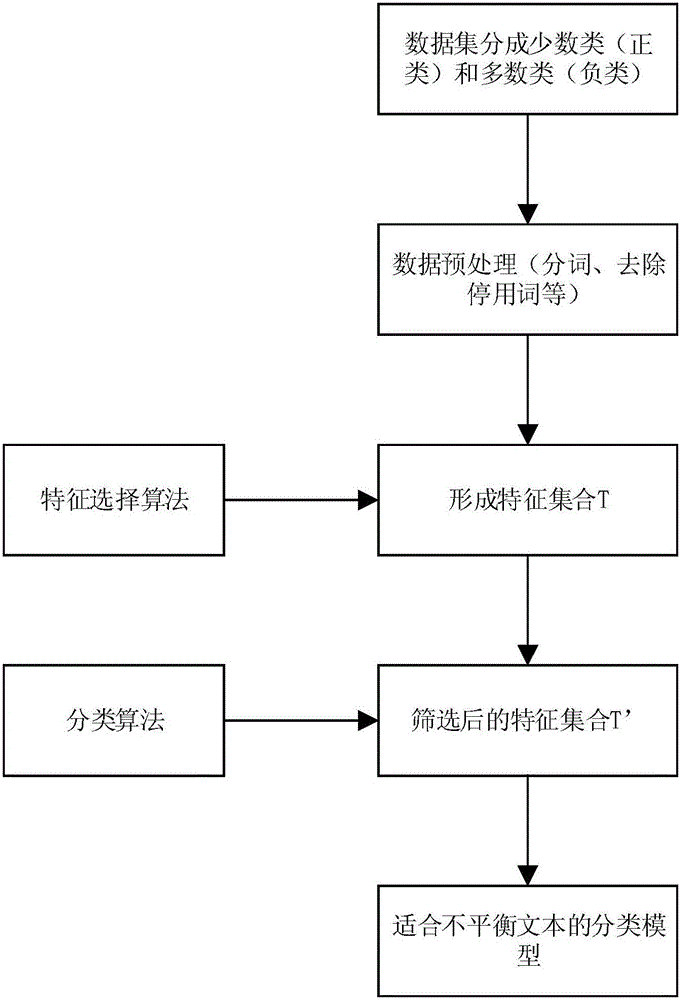
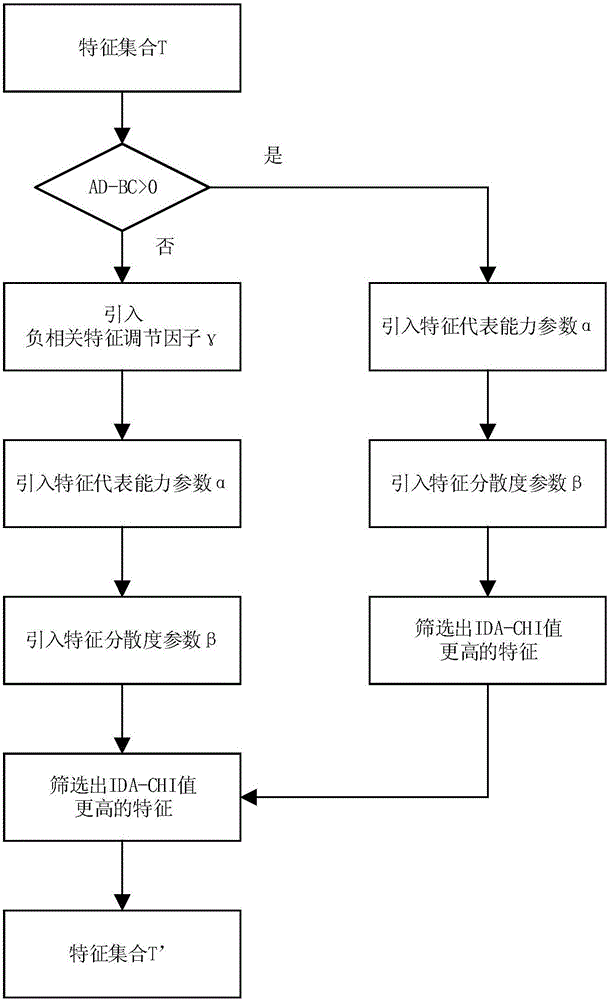
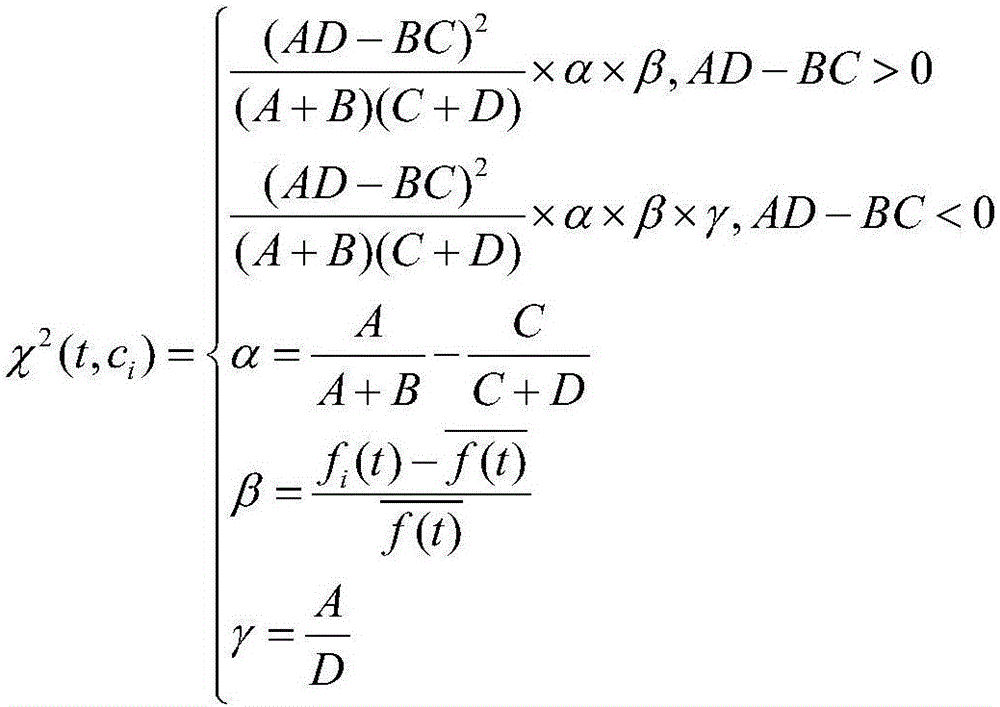
Examples
Embodiment Construction
[0030] In order to check the advantages and disadvantages of the present invention, it can be checked and verified by the following several evaluation indicators.
[0031] See Table 1. Recall and precision are commonly used in unbalanced data classification to measure the classification quality of the model, and the F1 value is a comprehensive consideration of the classification performance of the two classes, taking into account both positive and negative classifications. Average of precision.
[0032] Table 1
[0033]
[0034] Among them, TP (TruePositive) refers to the positive class correctly classified by the classifier; TN (TrueNegative) refers to the negative class correctly classified by the classifier; FP (FalsePositive) refers to the positive class incorrectly classified by the classifier; FN (FalseNegative) Refers to the negative class that was misclassified by the classifier.
[0035] recall
[0036] Precision
[0037] F1 value:
[0038] The data set ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com