Related knowledge point acquisition method and system
A technology of knowledge points and domain knowledge, which is applied in the field of electronic digital data processing, can solve problems such as poor objectivity, heavy workload, and artificial screening, so as to reduce workload, improve efficiency and accuracy, and save time and labor costs. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0033] In this embodiment, a method for obtaining related knowledge points is provided, through which the relevant knowledge points of all knowledge points in the field are obtained, and then according to the obtained related knowledge points, for the entries in the established field encyclopedia It has very good guiding value to check for leaks and fill in vacancies for further improvement. Knowledge point refers to the basic unit of information transmission. Researching the representation and association of knowledge points plays an important role in improving learning navigation, information recommendation, retrieval, and thesaurus establishment.
[0034] The method of obtaining the relevant knowledge points, the flow chart is as follows figure 1 As shown, the specific process is as follows:
[0035] First, obtain domain knowledge points and obtain all knowledge points in this field. For example, when building an encyclopedia, you can obtain all entries in this field that ...
Embodiment 2
[0048] This embodiment provides a method for acquiring relevant knowledge points, the steps of which are the same as those in Embodiment 1. This embodiment provides a specific method for calculating the semantic vector of each candidate knowledge point in the above process, and the specific process is as follows :
[0049] The first step is to determine the number of occurrences of each candidate knowledge point in the candidate document, so that the text of each candidate knowledge point and its occurrence times is obtained. The candidate text is the text obtained after word segmentation from the selected digital resources, and the candidate knowledge point is the word obtained after the word segmentation in the candidate text except common words. This part is the same as that in Embodiment 1, and will not be repeated here.
[0050] The second step is to calculate the binary tree with the minimum weighted path length according to each candidate knowledge point and the number ...
Embodiment 3
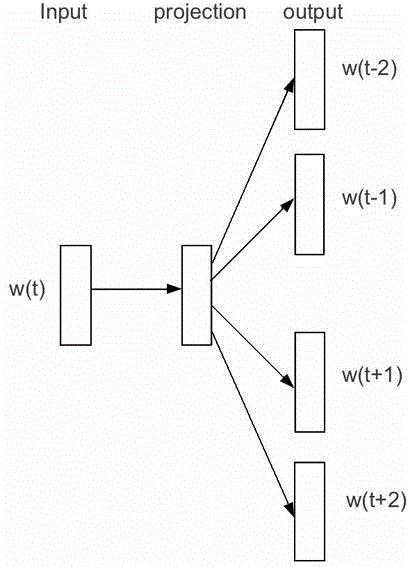
[0066] Field encyclopedias are an important digital publishing resource. Domain encyclopedias usually organize domain information in the form of entries. The domain encyclopedia needs to contain important entries in the domain. However, building a domain encyclopedia requires a lot of human input. This embodiment provides a method for obtaining related knowledge points, where the domain knowledge points are entries in the domain encyclopedia. In this embodiment, the domain e-book text and newspaper text are used to calculate the semantic vector of the candidate entry through the skip-gram model. The semantic similarity between the constructed domain entries and the obtained candidate entries is calculated through semantic vectors. By using the semantic similarity of the entries, other field entries that are semantically related to the field encyclopedia entries and that have been missed are found, so as to reduce the possibility of some field entries being missed. Specific...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com