A Structure-Extended Multinomial Naive Bayesian Text Classification Method
A text classification and polynomial technology, which is applied in the fields of unstructured text data retrieval, text database clustering/classification, special data processing applications, etc., can solve the undiscovered polynomial Naive Bayesian text classification model structure extension method and other problems, Achieve the effect of avoiding the structure learning stage and saving space resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

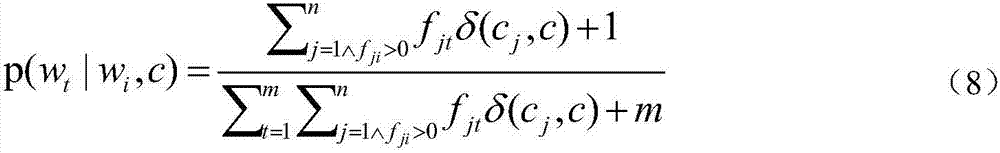
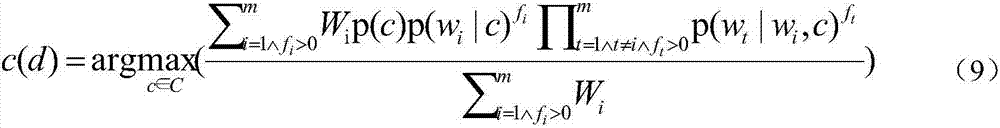
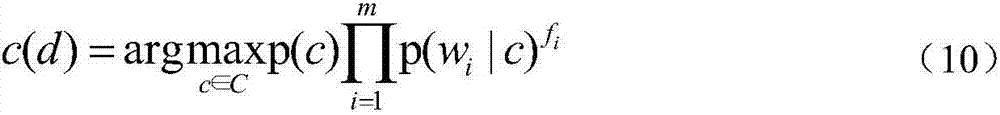
Examples
Embodiment Construction
[0040] The present invention will be further described below in conjunction with embodiment.
[0041] The present invention provides a multinomial naive Bayesian text classification method with extended structure, including a training phase and a classification phase, wherein,
[0042] (1) The training phase includes the following processes:
[0043] (1-1) Use the following formula to calculate the prior probability p(c) of each category in the training document set D:
[0044]
[0045]Among them, the training document set D is a known document set, and any document d in the training document set D is expressed as a word vector form d=1 ,w 2 ,...w m >, where w i is the i-th word in the document d, m is the number of words in the training document set D; n is the number of documents in the training document set D, s is the number of document categories, c j is the class label of the jth document, δ(c j ,c) represents a binary function, when its two parameters are the sa...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com